Yang Di, Dong Tao, Wang Peng
School of Computer Science and Technology, Changchun University of Science and Technology, Changchun, 130022, China.
Jilin Provincial Joint Key Laboratory of Big Data Science and Engineering, Changchun, 130022, China.
Heliyon. 2024 Apr 29;10(9):e30117. doi: 10.1016/j.heliyon.2024.e30117. eCollection 2024 May 15.
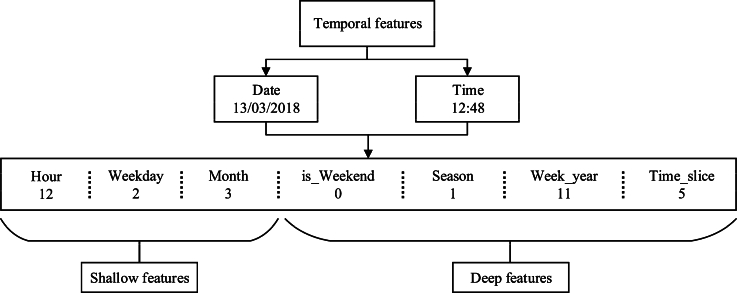
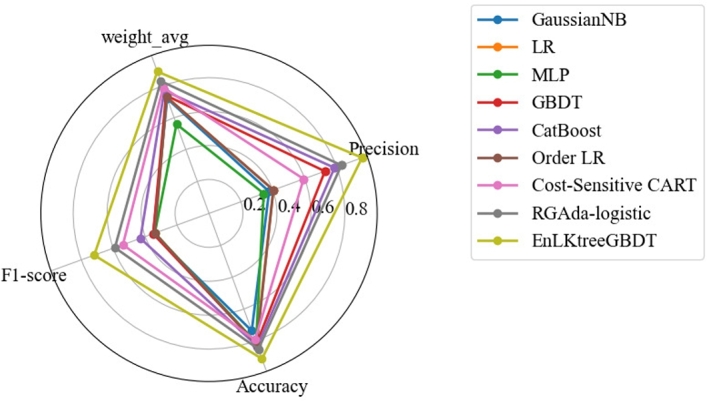
The crash severity analysis is of significant importance in traffic crash prevention and emergency resource allocation. A range of innovations offers potential traffic crash severity prediction models to improve road safety. However, the semantic information inherent in traffic crash data, which is crucial in enabling a deeper understanding of its underlying factors and impacts, has yet to be fully utilized. Moreover, traffic crash data are commonly characterized by a small sample size, which leads to sample imbalance problem resulting in prediction performance decline. To tackle these problems, we propose a semantic understanding-based data-enhanced double-layer stacking model, named EnLKtreeGBDT, for crash severity prediction. Specifically, to fully leverage the inherent semantic information within traffic crash data and analyze the factors influencing crashes, we design a semantic enhancement module for multi-dimensional feature extraction. This module aims to enhance the understanding of crash semantics and improve prediction accuracy. Then we introduce a data enhancement module that utilizes data denoising and migration techniques to address the challenge of data imbalance, reducing the prediction model's dependence on large sample crash data. Furthermore, we construct a two-layer stacking model that combines multiple linear and nonlinear classifiers. This model is designed to augment the capability of learning linear and nonlinear mixed relationships, thereby improving the accuracy of predicting the severity of crashes on complex urban roads. Experiments on historical datasets of UK road safety crashes validate the effectiveness of the proposed model, and superior performance of prediction precision is achieved compared with the state-of-the-arts. The ablation experiments on both semantic and data enhancement modules further confirm the indispensability of each module in the proposed model.
碰撞严重程度分析在交通事故预防和应急资源分配中具有重要意义。一系列创新为交通事故严重程度预测模型提供了潜力,以提高道路安全。然而,交通事故数据中固有的语义信息对于深入理解其潜在因素和影响至关重要,但尚未得到充分利用。此外,交通事故数据通常具有样本量小的特点,这会导致样本不均衡问题,进而导致预测性能下降。为了解决这些问题,我们提出了一种基于语义理解的数据增强双层堆叠模型,名为EnLKtreeGBDT,用于碰撞严重程度预测。具体而言,为了充分利用交通事故数据中的固有语义信息并分析影响碰撞的因素,我们设计了一个用于多维度特征提取的语义增强模块。该模块旨在增强对碰撞语义的理解并提高预测准确性。然后,我们引入一个数据增强模块,该模块利用数据去噪和迁移技术来应对数据不均衡的挑战,减少预测模型对大量样本碰撞数据的依赖。此外,我们构建了一个结合多个线性和非线性分类器的双层堆叠模型。该模型旨在增强学习线性和非线性混合关系的能力,从而提高预测复杂城市道路碰撞严重程度的准确性。对英国道路安全碰撞历史数据集进行的实验验证了所提出模型的有效性,并且与现有技术相比,实现了更高的预测精度。对语义和数据增强模块的消融实验进一步证实了每个模块在所提出模型中的不可或缺性。