Burbach Sarah M, Briney Bryan
Department of Immunology and Microbiology, The Scripps Research Institute, La Jolla, CA 92037, USA.
Center for Viral Systems Biology, The Scripps Research Institute, La Jolla, CA 92037, USA.
Patterns (N Y). 2024 Apr 4;5(5):100967. doi: 10.1016/j.patter.2024.100967. eCollection 2024 May 10.
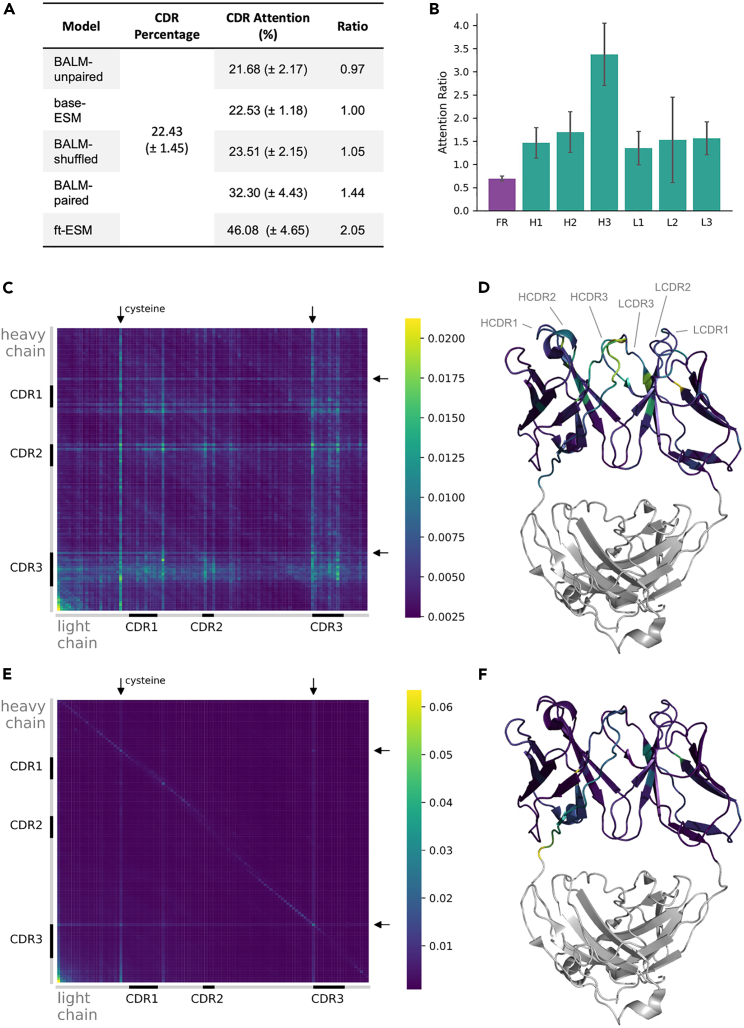
Existing antibody language models are limited by their use of unpaired antibody sequence data. A recently published dataset of ∼1.6 × 10 natively paired human antibody sequences offers a unique opportunity to evaluate how antibody language models are improved by training with native pairs. We trained three baseline antibody language models (BALM), using natively paired (BALM-paired), randomly-paired (BALM-shuffled), or unpaired (BALM-unpaired) sequences from this dataset. To address the paucity of paired sequences, we additionally fine-tuned ESM (evolutionary scale modeling)-2 with natively paired antibody sequences (ft-ESM). We provide evidence that training with native pairs allows the model to learn immunologically relevant features that span the light and heavy chains, which cannot be simulated by training with random pairs. We additionally show that training with native pairs improves model performance on a variety of metrics, including the ability of the model to classify antibodies by pathogen specificity.
现有的抗体语言模型受到其对未配对抗体序列数据使用的限制。最近发布的一个包含约16亿条天然配对人类抗体序列的数据集,为评估抗体语言模型如何通过使用天然配对数据进行训练而得到改进提供了独特机会。我们使用该数据集中的天然配对(BALM-配对)、随机配对(BALM-洗牌)或未配对(BALM-未配对)序列训练了三个基线抗体语言模型(BALM)。为了解决配对序列稀缺的问题,我们还用天然配对抗体序列对ESM(进化尺度建模)-2进行了额外的微调(ft-ESM)。我们提供的证据表明,使用天然配对数据进行训练能使模型学习到跨越轻链和重链的免疫相关特征,而这是使用随机配对数据训练无法模拟的。我们还表明,使用天然配对数据进行训练在各种指标上提高了模型性能,包括模型按病原体特异性对抗体进行分类的能力。