Keloth Vipina K, Selek Salih, Chen Qingyu, Gilman Christopher, Fu Sunyang, Dang Yifang, Chen Xinghan, Hu Xinyue, Zhou Yujia, He Huan, Fan Jungwei W, Wang Karen, Brandt Cynthia, Tao Cui, Liu Hongfang, Xu Hua
Department of Biomedical Informatics and Data Science, Yale School of Medicine, New Haven, CT, USA.
Department of Psychiatry and Behavioral Sciences, UTHealth McGovern Medical School, Houston, TX, USA.
medRxiv. 2024 May 22:2024.05.21.24307726. doi: 10.1101/2024.05.21.24307726.
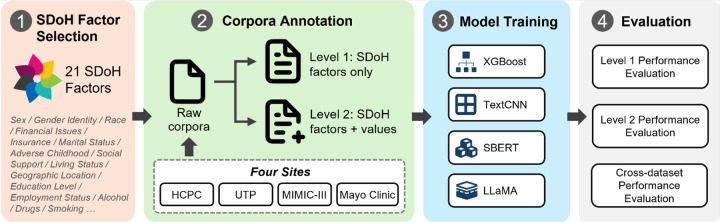
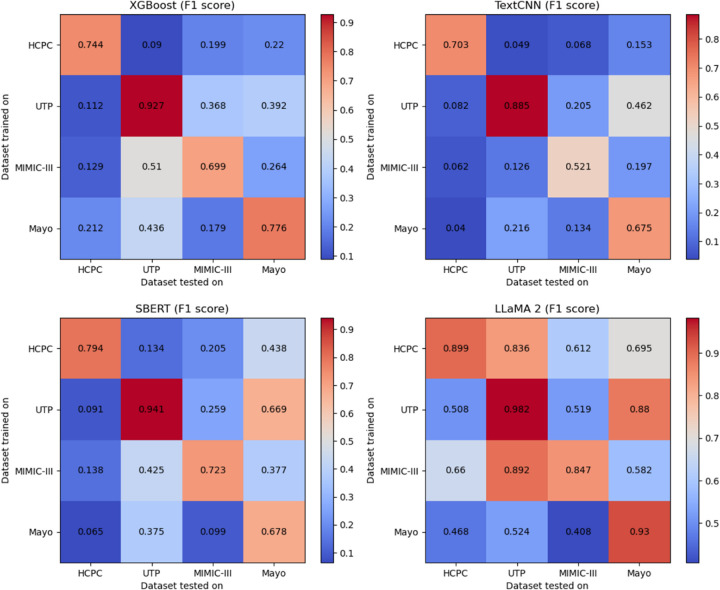
The consistent and persuasive evidence illustrating the influence of social determinants on health has prompted a growing realization throughout the health care sector that enhancing health and health equity will likely depend, at least to some extent, on addressing detrimental social determinants. However, detailed social determinants of health (SDoH) information is often buried within clinical narrative text in electronic health records (EHRs), necessitating natural language processing (NLP) methods to automatically extract these details. Most current NLP efforts for SDoH extraction have been limited, investigating on limited types of SDoH elements, deriving data from a single institution, focusing on specific patient cohorts or note types, with reduced focus on generalizability. This study aims to address these issues by creating cross-institutional corpora spanning different note types and healthcare systems, and developing and evaluating the generalizability of classification models, including novel large language models (LLMs), for detecting SDoH factors from diverse types of notes from four institutions: Harris County Psychiatric Center, University of Texas Physician Practice, Beth Israel Deaconess Medical Center, and Mayo Clinic. Four corpora of deidentified clinical notes were annotated with 21 SDoH factors at two levels: level 1 with SDoH factor types only and level 2 with SDoH factors along with associated values. Three traditional classification algorithms (XGBoost, TextCNN, Sentence BERT) and an instruction tuned LLM-based approach (LLaMA) were developed to identify multiple SDoH factors. Substantial variation was noted in SDoH documentation practices and label distributions based on patient cohorts, note types, and hospitals. The LLM achieved top performance with micro-averaged F1 scores over 0.9 on level 1 annotated corpora and an F1 over 0.84 on level 2 annotated corpora. While models performed well when trained and tested on individual datasets, cross-dataset generalization highlighted remaining obstacles. To foster collaboration, access to partial annotated corpora and models trained by merging all annotated datasets will be made available on the PhysioNet repository.
有说服力的一致证据表明社会决定因素对健康有影响,这促使整个医疗保健行业越来越意识到,改善健康和健康公平性至少在一定程度上可能取决于解决有害的社会决定因素。然而,详细的健康社会决定因素(SDoH)信息往往隐藏在电子健康记录(EHR)的临床叙述文本中,因此需要自然语言处理(NLP)方法来自动提取这些细节。目前大多数用于提取SDoH的NLP工作都很有限,只研究有限类型的SDoH元素,从单一机构获取数据,专注于特定患者群体或笔记类型,而对通用性的关注较少。本研究旨在通过创建跨不同笔记类型和医疗系统的跨机构语料库,以及开发和评估分类模型(包括新型大语言模型(LLM))的通用性来解决这些问题,这些模型用于从哈里斯县精神病中心、德克萨斯大学医师实践中心、贝斯以色列女执事医疗中心和梅奥诊所这四个机构的不同类型笔记中检测SDoH因素。四个去识别化临床笔记语料库用21个SDoH因素在两个级别上进行了注释:一级仅标注SDoH因素类型,二级标注SDoH因素及其相关值。开发了三种传统分类算法(XGBoost、TextCNN、Sentence BERT)和一种基于指令微调的基于LLM的方法(LLaMA)来识别多个SDoH因素。基于患者群体、笔记类型和医院,在SDoH文档实践和标签分布方面存在显著差异。LLM在一级注释语料库上的微平均F1分数超过0.9,在二级注释语料库上的F1分数超过0.84,表现最佳。虽然模型在单个数据集上进行训练和测试时表现良好,但跨数据集泛化突出了仍然存在的障碍。为了促进合作,将在PhysioNet存储库上提供对部分注释语料库和通过合并所有注释数据集训练的模型的访问权限。