Gu Bowen, Shao Vivian, Liao Ziqian, Carducci Valentina, Brufau Santiago Romero, Yang Jie, Desai Rishi J
Division of Pharmacoepidemiology and Pharmacoeconomics, Department of Medicine, Brigham and Women's Hospital, Harvard Medical School, 1620 Tremont Street, Suite 3030-R, Boston, MA, 02120, USA.
Department of Otorhinolaryngology - Head & Neck Surgery, Mayo Clinic, Rochester, MN, USA.
BMC Med Res Methodol. 2025 Jan 28;25(1):23. doi: 10.1186/s12874-025-02470-z.
A vast amount of potentially useful information such as description of patient symptoms, family, and social history is recorded as free-text notes in electronic health records (EHRs) but is difficult to reliably extract at scale, limiting their utility in research. This study aims to assess whether an "out of the box" implementation of open-source large language models (LLMs) without any fine-tuning can accurately extract social determinants of health (SDoH) data from free-text clinical notes.
We conducted a cross-sectional study using EHR data from the Mass General Brigham (MGB) system, analyzing free-text notes for SDoH information. We selected a random sample of 200 patients and manually labeled nine SDoH aspects. Eight advanced open-source LLMs were evaluated against a baseline pattern-matching model. Two human reviewers provided the manual labels, achieving 93% inter-annotator agreement. LLM performance was assessed using accuracy metrics for overall, mentioned, and non-mentioned SDoH, and macro F1 scores.
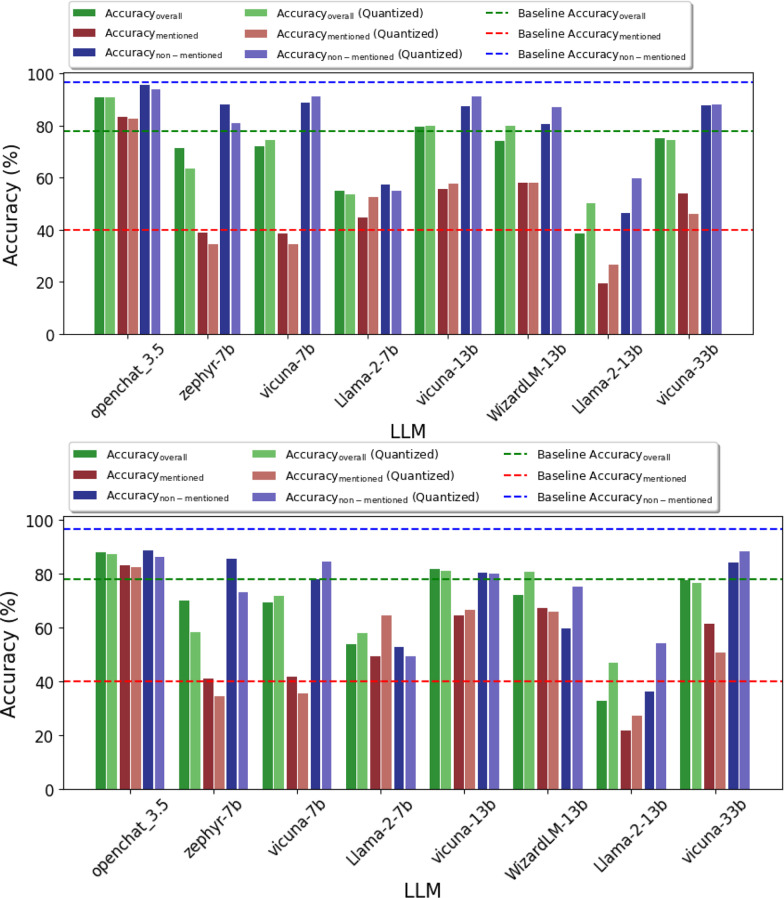
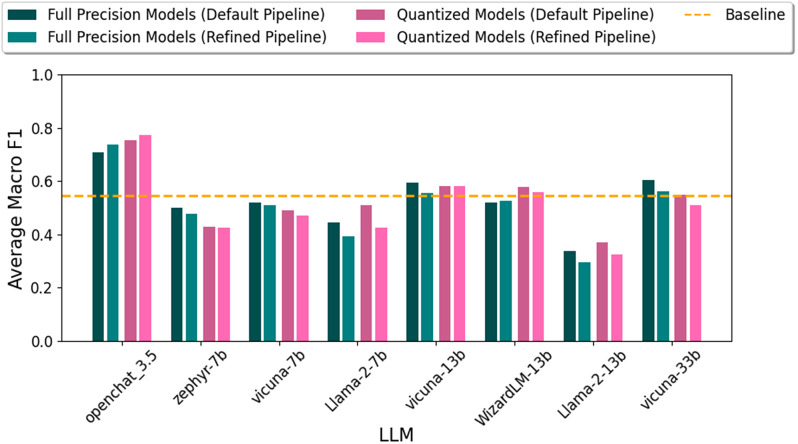
LLMs outperformed the baseline pattern-matching approach, particularly for explicitly mentioned SDoH, achieving up to 40% higher Accuracy. openchat_3.5 was the best-performing model, surpassing the baseline in overall accuracy across all nine SDoH aspects. The refined pipeline with prompt engineering reduced hallucinations and improved accuracy.
Open-source LLMs are effective and scalable tools for extracting SDoH from unstructured EHRs, surpassing traditional pattern-matching methods. Further refinement and domain-specific training could enhance their utility in clinical research and predictive analytics, improving healthcare outcomes and addressing health disparities.
大量潜在有用信息,如患者症状描述、家族史和社会史等,都以自由文本注释的形式记录在电子健康记录(EHR)中,但难以大规模可靠提取,限制了它们在研究中的效用。本研究旨在评估无需任何微调的开源大语言模型(LLM)的“开箱即用”实施能否从自由文本临床注释中准确提取健康的社会决定因素(SDoH)数据。
我们使用来自麻省总医院布莱根(MGB)系统的EHR数据进行了一项横断面研究,分析自由文本注释中的SDoH信息。我们随机抽取了200名患者的样本,并手动标记了九个SDoH方面。针对基线模式匹配模型评估了八个先进的开源LLM。两名人类审阅者提供手动标记,注释者间一致性达到93%。使用总体、提及和未提及的SDoH的准确性指标以及宏观F1分数评估LLM性能。
LLM的表现优于基线模式匹配方法,特别是对于明确提及的SDoH,准确率提高了40%。openchat_3.5是表现最佳的模型,在所有九个SDoH方面的总体准确率超过了基线。带有提示工程的优化管道减少了幻觉并提高了准确性。
开源LLM是从非结构化EHR中提取SDoH的有效且可扩展的工具,优于传统的模式匹配方法。进一步的优化和特定领域训练可以提高它们在临床研究和预测分析中的效用,改善医疗保健结果并解决健康差异问题。