Chen Shifu
HaploX Biotechnology Shenzhen China.
Shenzhen Institutes of Advanced Technology Chinese Academy of Sciences Shenzhen China.
Imeta. 2023 May 8;2(2):e107. doi: 10.1002/imt2.107. eCollection 2023 May.
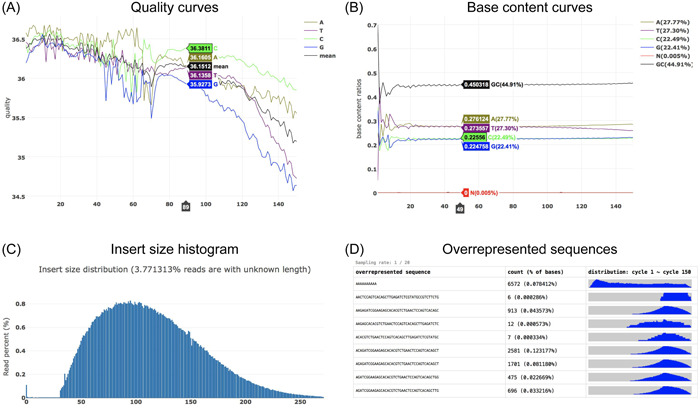
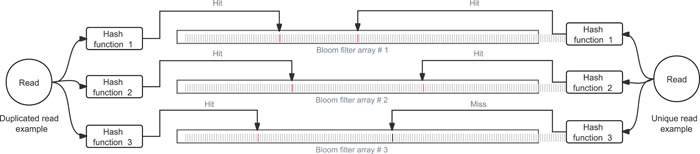
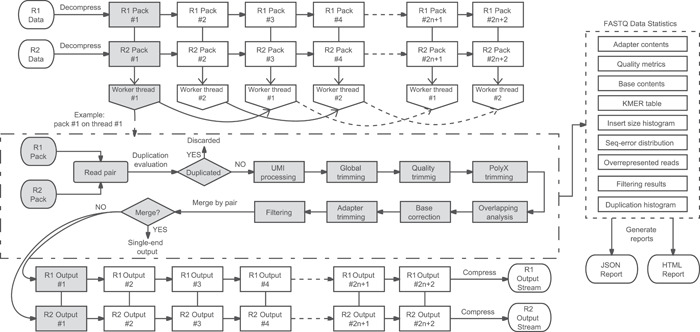
A large amount of sequencing data is generated and processed every day with the continuous evolution of sequencing technology and the expansion of sequencing applications. One consequence of such sequencing data explosion is the increasing cost and complexity of data processing. The preprocessing of FASTQ data, which means removing adapter contamination, filtering low-quality reads, and correcting wrongly represented bases, is an indispensable but resource intensive part of sequencing data analysis. Therefore, although a lot of software applications have been developed to solve this problem, bioinformatics scientists and engineers are still pursuing faster, simpler, and more energy-efficient software. Several years ago, the author developed fastp, which is an ultrafast all-in-one FASTQ data preprocessor with many modern features. This software has been approved by many bioinformatics users and has been continuously maintained and updated. Since the first publication on fastp, it has been greatly improved, making it even faster and more powerful. For instance, the duplication evaluation module has been improved, and a new deduplication module has been added. This study aimed to introduce the new features of fastp and demonstrate how it was designed and implemented.
随着测序技术的不断发展和测序应用的扩展,每天都会生成和处理大量的测序数据。这种测序数据爆炸的一个后果是数据处理成本和复杂性的增加。FASTQ数据的预处理,即去除接头污染、过滤低质量 reads 以及校正错误表示的碱基,是测序数据分析中不可或缺但资源密集的一部分。因此,尽管已经开发了许多软件应用程序来解决这个问题,但生物信息学科学家和工程师仍在追求更快、更简单、更节能的软件。几年前,作者开发了fastp,这是一个具有许多现代功能的超快一体化FASTQ数据预处理器。该软件已得到许多生物信息学用户的认可,并一直在持续维护和更新。自首次发表关于fastp的文章以来,它已经有了很大的改进,使其更快、更强大。例如,重复评估模块得到了改进,并添加了一个新的去重模块。本研究旨在介绍fastp的新功能,并展示其设计和实现方式。