UCLA-Caltech Medical Scientist Training Program, David Geffen School of Medicine, University of California, Los Angeles, Los Angeles, CA 90095, United States.
Division of Biology and Biological Engineering, California Institute of Technology, Pasadena, CA 91125, United States.
Bioinformatics. 2024 Jun 3;40(6). doi: 10.1093/bioinformatics/btae331.
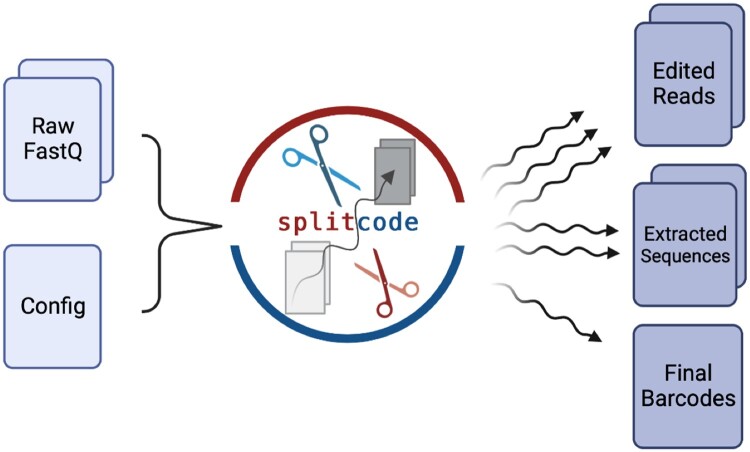
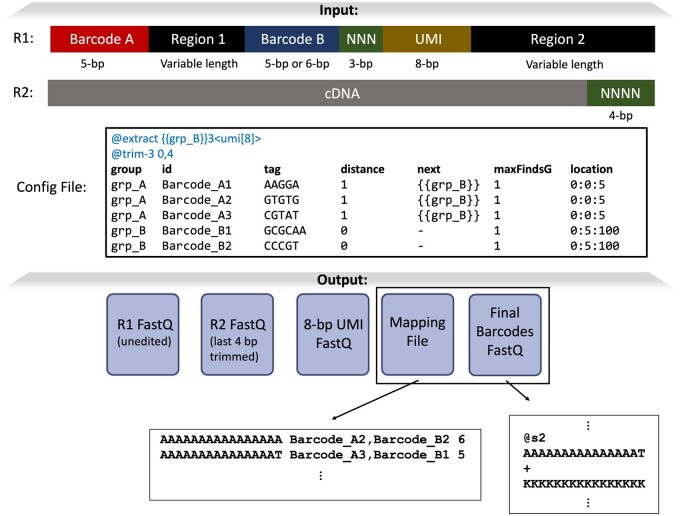
Next-generation sequencing libraries are constructed with numerous synthetic constructs such as sequencing adapters, barcodes, and unique molecular identifiers. Such sequences can be essential for interpreting results of sequencing assays, and when they contain information pertinent to an experiment, they must be processed and analyzed.
We present a tool called splitcode, that enables flexible and efficient parsing, interpreting, and editing of sequencing reads. This versatile tool facilitates simple, reproducible preprocessing of reads from libraries constructed for a large array of single-cell and bulk sequencing assays.
The splitcode program is available at http://github.com/pachterlab/splitcode.
下一代测序文库是通过许多合成结构构建的,例如测序接头、条形码和独特的分子标识符。这些序列对于解释测序实验的结果至关重要,当它们包含与实验相关的信息时,就必须对其进行处理和分析。
我们提出了一种名为 splitcode 的工具,它可以灵活高效地解析、解释和编辑测序reads。这个多功能的工具简化了从大量单细胞和批量测序实验构建的文库中进行reads 的预处理,具有良好的可重复性。
splitcode 程序可在 http://github.com/pachterlab/splitcode 上获得。