Therre Amelie, Bell Raoul, Menne Nicola Marie, Mayer Carolin, Lichtenhagen Ulla, Buchner Axel
Department of Experimental Psychology, Heinrich Heine University Düsseldorf, Universitätsstraße 1, 40225, Düsseldorf, Germany.
Sci Rep. 2024 Jun 19;14(1):14126. doi: 10.1038/s41598-024-64768-0.
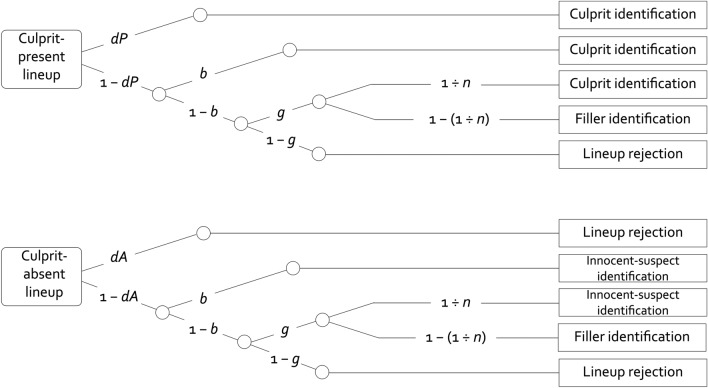
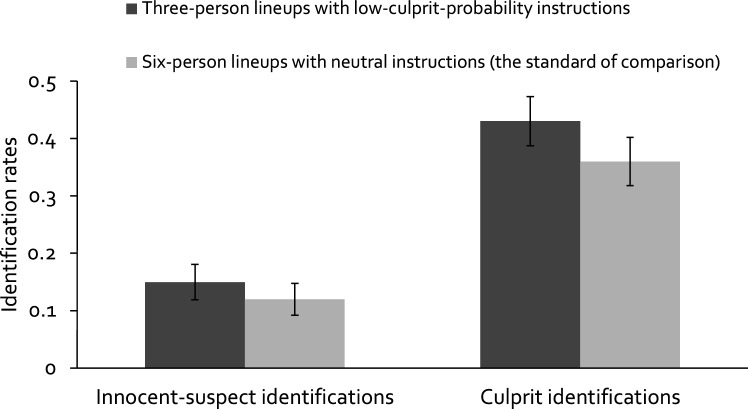
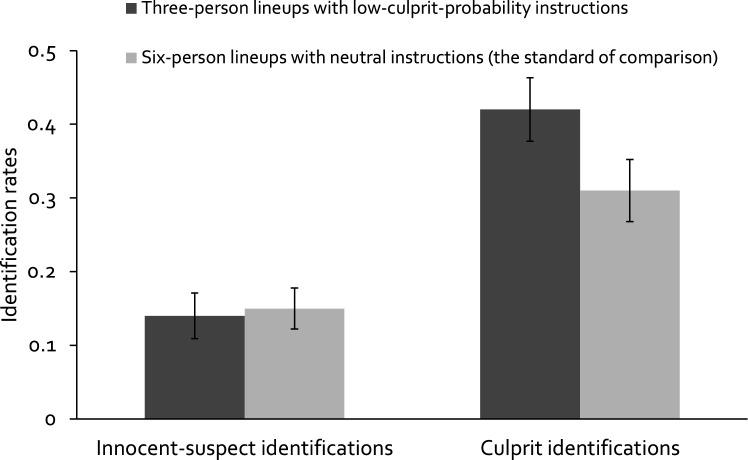
The primary argument for including large numbers of known-to-be innocent fillers in lineups is that guessing-based selections are dispersed among a large number of lineup members, leading to low innocent-suspect identification rates. However, a recent study using the two-high threshold eyewitness identification model has demonstrated advantages of smaller lineups at the level of the processes underlying the observable responses. Participants were more likely to detect the presence of the culprit and less likely to select lineup members based on guessing in smaller than in larger lineups. Nonetheless, at the level of observable responses, the rate of innocent-suspect identifications was higher in smaller compared to larger lineups due to the decreased dispersion of guessing-based selections among the lineup members. To address this issue, we combined smaller lineups with lineup instructions insinuating that the culprit was unlikely to be in the lineup. The goal was to achieve a particularly low rate of guessing-based selections. These lineups were compared to larger lineups with neutral instructions. In two experiments, culprit-presence detection occurred with a higher probability in smaller compared to larger lineups. Furthermore, instructions insinuating that the culprit was unlikely to be in the lineup reduced guessing-based selection compared to neutral instructions. At the level of observable responses, the innocent-suspect identification rate did not differ between smaller lineups with low-culprit-probability instructions and larger lineups with neutral instructions. The rate of culprit identifications was higher in smaller lineups with low-culprit-probability instructions than in larger lineups with neutral instructions.
在列队辨认中纳入大量已知无辜陪衬人员的主要理由是,基于猜测的选择分散在大量列队成员之中,导致无辜嫌疑人被指认的比例较低。然而,最近一项使用双高阈值目击证人辨认模型的研究表明,在可观察反应背后的过程层面,较小规模的列队有其优势。与较大规模的列队相比,参与者在较小规模的列队中更有可能察觉到罪犯的存在,而基于猜测选择列队成员的可能性更小。尽管如此,在可观察反应层面,由于基于猜测的选择在列队成员中的分散性降低,较小规模列队中无辜嫌疑人被指认的比例高于较大规模的列队。为解决这一问题,我们将较小规模的列队与暗示罪犯不太可能在列队中的列队指示相结合。目标是实现特别低的基于猜测的选择率。将这些列队与具有中性指示的较大规模列队进行比较。在两项实验中,与较大规模的列队相比,较小规模的列队中察觉到罪犯存在的概率更高。此外,与中性指示相比,暗示罪犯不太可能在列队中的指示减少了基于猜测的选择。在可观察反应层面,具有低罪犯概率指示的较小规模列队与具有中性指示的较大规模列队之间,无辜嫌疑人被指认的比例没有差异。具有低罪犯概率指示的较小规模列队中罪犯被指认的比例高于具有中性指示的较大规模列队。