Department of Medicine IV, LMU University Hospital, Munich, Germany.
Department of Medicine I, LMU University Hospital, Munich, Germany.
J Med Internet Res. 2024 Jul 8;26:e56110. doi: 10.2196/56110.
OpenAI's ChatGPT is a pioneering artificial intelligence (AI) in the field of natural language processing, and it holds significant potential in medicine for providing treatment advice. Additionally, recent studies have demonstrated promising results using ChatGPT for emergency medicine triage. However, its diagnostic accuracy in the emergency department (ED) has not yet been evaluated.
This study compares the diagnostic accuracy of ChatGPT with GPT-3.5 and GPT-4 and primary treating resident physicians in an ED setting.
Among 100 adults admitted to our ED in January 2023 with internal medicine issues, the diagnostic accuracy was assessed by comparing the diagnoses made by ED resident physicians and those made by ChatGPT with GPT-3.5 or GPT-4 against the final hospital discharge diagnosis, using a point system for grading accuracy.
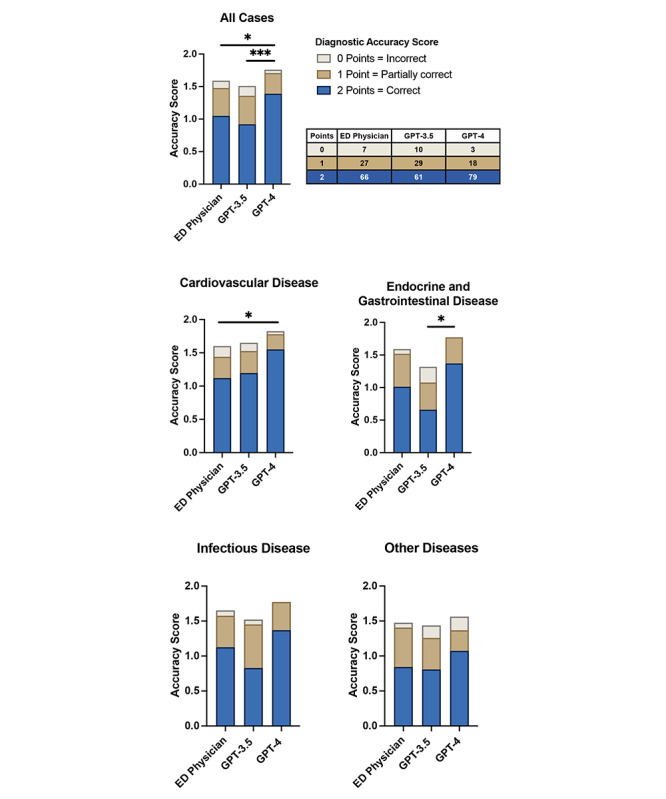
The study enrolled 100 patients with a median age of 72 (IQR 58.5-82.0) years who were admitted to our internal medicine ED primarily for cardiovascular, endocrine, gastrointestinal, or infectious diseases. GPT-4 outperformed both GPT-3.5 (P<.001) and ED resident physicians (P=.01) in diagnostic accuracy for internal medicine emergencies. Furthermore, across various disease subgroups, GPT-4 consistently outperformed GPT-3.5 and resident physicians. It demonstrated significant superiority in cardiovascular (GPT-4 vs ED physicians: P=.03) and endocrine or gastrointestinal diseases (GPT-4 vs GPT-3.5: P=.01). However, in other categories, the differences were not statistically significant.
In this study, which compared the diagnostic accuracy of GPT-3.5, GPT-4, and ED resident physicians against a discharge diagnosis gold standard, GPT-4 outperformed both the resident physicians and its predecessor, GPT-3.5. Despite the retrospective design of the study and its limited sample size, the results underscore the potential of AI as a supportive diagnostic tool in ED settings.
OpenAI 的 ChatGPT 是自然语言处理领域的开创性人工智能(AI),它在提供治疗建议方面具有重要的医学应用潜力。此外,最近的研究表明,ChatGPT 在急诊分诊中具有很有前景的结果。然而,它在急诊室(ED)的诊断准确性尚未得到评估。
本研究比较了 ChatGPT 与 GPT-3.5 和 GPT-4 以及 ED 主治住院医师在 ED 环境中的诊断准确性。
在 2023 年 1 月入住我们 ED 的 100 名患有内科问题的成年人中,通过比较 ED 主治住院医师与 ChatGPT 与 GPT-3.5 或 GPT-4 做出的诊断与最终出院诊断,使用分级准确性的评分系统来评估诊断准确性。
这项研究共纳入了 100 名中位年龄为 72(IQR 58.5-82.0)岁的患者,他们主要因心血管、内分泌、胃肠道或传染病而入住我们的内科 ED。GPT-4 在诊断内科急症方面的准确性优于 GPT-3.5(P<.001)和 ED 主治住院医师(P=.01)。此外,在各种疾病亚组中,GPT-4 始终优于 GPT-3.5 和主治住院医师。它在心血管疾病(GPT-4 与 ED 医师:P=.03)和内分泌或胃肠道疾病(GPT-4 与 GPT-3.5:P=.01)方面表现出显著优势。然而,在其他类别中,差异没有统计学意义。
在这项研究中,我们将 GPT-3.5、GPT-4 和 ED 主治住院医师的诊断准确性与出院诊断金标准进行了比较,GPT-4 的表现优于主治住院医师和其前身 GPT-3.5。尽管研究采用了回顾性设计且样本量有限,但研究结果强调了 AI 作为 ED 环境中辅助诊断工具的潜力。