Wu Qingxia, Wu Qingxia, Li Huali, Wang Yan, Bai Yan, Wu Yaping, Yu Xuan, Li Xiaodong, Dong Pei, Xue Jon, Shen Dinggang, Wang Meiyun
Department of Medical Imaging, Henan Provincial People's Hospital & People's Hospital of Zhengzhou University, Zhengzhou, China.
Research Intelligence Department, Beijing United Imaging Research Institute of Intelligent Imaging, Beijing, China.
JMIR Med Inform. 2024 Jul 17;12:e55799. doi: 10.2196/55799.
Large language models show promise for improving radiology workflows, but their performance on structured radiological tasks such as Reporting and Data Systems (RADS) categorization remains unexplored.
This study aims to evaluate 3 large language model chatbots-Claude-2, GPT-3.5, and GPT-4-on assigning RADS categories to radiology reports and assess the impact of different prompting strategies.
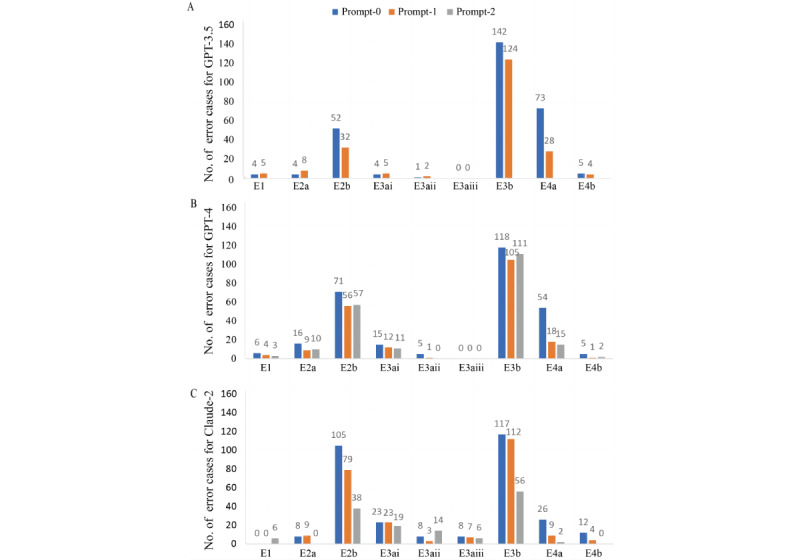
This cross-sectional study compared 3 chatbots using 30 radiology reports (10 per RADS criteria), using a 3-level prompting strategy: zero-shot, few-shot, and guideline PDF-informed prompts. The cases were grounded in Liver Imaging Reporting & Data System (LI-RADS) version 2018, Lung CT (computed tomography) Screening Reporting & Data System (Lung-RADS) version 2022, and Ovarian-Adnexal Reporting & Data System (O-RADS) magnetic resonance imaging, meticulously prepared by board-certified radiologists. Each report underwent 6 assessments. Two blinded reviewers assessed the chatbots' response at patient-level RADS categorization and overall ratings. The agreement across repetitions was assessed using Fleiss κ.
Claude-2 achieved the highest accuracy in overall ratings with few-shot prompts and guideline PDFs (prompt-2), attaining 57% (17/30) average accuracy over 6 runs and 50% (15/30) accuracy with k-pass voting. Without prompt engineering, all chatbots performed poorly. The introduction of a structured exemplar prompt (prompt-1) increased the accuracy of overall ratings for all chatbots. Providing prompt-2 further improved Claude-2's performance, an enhancement not replicated by GPT-4. The interrun agreement was substantial for Claude-2 (k=0.66 for overall rating and k=0.69 for RADS categorization), fair for GPT-4 (k=0.39 for both), and fair for GPT-3.5 (k=0.21 for overall rating and k=0.39 for RADS categorization). All chatbots showed significantly higher accuracy with LI-RADS version 2018 than with Lung-RADS version 2022 and O-RADS (P<.05); with prompt-2, Claude-2 achieved the highest overall rating accuracy of 75% (45/60) in LI-RADS version 2018.
When equipped with structured prompts and guideline PDFs, Claude-2 demonstrated potential in assigning RADS categories to radiology cases according to established criteria such as LI-RADS version 2018. However, the current generation of chatbots lags in accurately categorizing cases based on more recent RADS criteria.
大语言模型有望改善放射学工作流程,但其在结构化放射学任务(如报告和数据系统(RADS)分类)方面的表现仍未得到探索。
本研究旨在评估3个大语言模型聊天机器人——Claude-2、GPT-3.5和GPT-4——对放射学报告进行RADS分类的能力,并评估不同提示策略的影响。
这项横断面研究使用30份放射学报告(每个RADS标准10份)比较了3个聊天机器人,采用三级提示策略:零样本、少样本和指南PDF告知提示。这些病例基于2018版肝脏影像报告和数据系统(LI-RADS)、2022版肺部计算机断层扫描(CT)筛查报告和数据系统(Lung-RADS)以及卵巢附件报告和数据系统(O-RADS)磁共振成像,由获得委员会认证的放射科医生精心准备。每份报告进行6次评估。两名盲法评审员在患者级RADS分类和总体评分方面评估聊天机器人的回答。使用Fleiss κ评估重复评估之间的一致性。
Claude-2在少样本提示和指南PDF(提示2)下总体评分的准确率最高,在6次运行中平均准确率达到57%(17/30),k次投票准确率为50%(15/30)。在没有提示工程的情况下,所有聊天机器人表现不佳。引入结构化示例提示(提示1)提高了所有聊天机器人总体评分的准确率。提供提示2进一步提高了Claude-2的性能,而GPT-4未复制这种提升。Claude-2的重复评估一致性较高(总体评分k = 0.66,RADS分类k = 0.69),GPT-4为中等(两者均为k = 0.39),GPT-3.5为中等(总体评分k = 0.21,RADS分类k = 0.39)。所有聊天机器人在2018版LI-RADS上的准确率显著高于2022版Lung-RADS和O-RADS(P <.05);使用提示2时,Claude-2在2018版LI-RADS中的总体评分准确率最高,为75%(45/60)。
当配备结构化提示和指南PDF时,Claude-2在根据LI-RADS 2018版等既定标准为放射学病例分配RADS分类方面显示出潜力。然而,当前一代聊天机器人在根据更新的RADS标准准确分类病例方面仍存在不足。