Institute of Psychology, Julius-Maximilians-Universität Würzburg, Würzburg, Germany.
Judge Business School, University of Cambridge, Cambridge, UK.
Nat Med. 2024 Nov;30(11):3098-3100. doi: 10.1038/s41591-024-03180-7. Epub 2024 Jul 25.
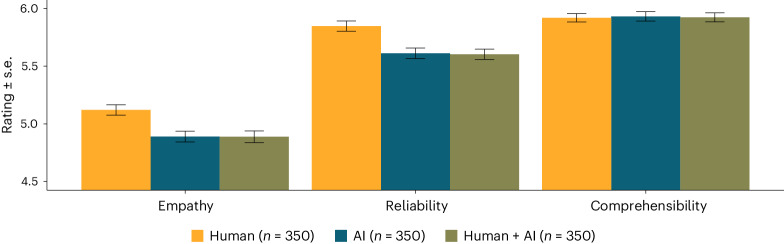
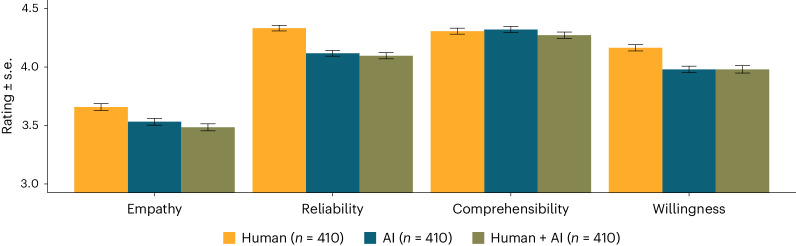
Large language models offer novel opportunities to seek digital medical advice. While previous research primarily addressed the performance of such artificial intelligence (AI)-based tools, public perception of these advancements received little attention. In two preregistered studies (n = 2,280), we presented participants with scenarios of patients obtaining medical advice. All participants received identical information, but we manipulated the putative source of this advice ('AI', 'human physician', 'human + AI'). 'AI'- and 'human + AI'-labeled advice was evaluated as significantly less reliable and less empathetic compared with 'human'-labeled advice. Moreover, participants indicated lower willingness to follow the advice when AI was believed to be involved in advice generation. Our findings point toward an anti-AI bias when receiving digital medical advice, even when AI is supposedly supervised by physicians. Given the tremendous potential of AI for medicine, elucidating ways to counteract this bias should be an important objective of future research.
大型语言模型为寻求数字医疗建议提供了新的机会。虽然之前的研究主要关注这些人工智能(AI)工具的性能,但公众对这些进展的看法却很少受到关注。在两项预先注册的研究中(n=2280),我们向参与者展示了患者获得医疗建议的场景。所有参与者都收到了相同的信息,但我们操纵了所谓的建议来源(“AI”、“人类医生”、“人类+AI”)。与“人类”标签的建议相比,“AI”和“人类+AI”标签的建议被评估为可靠性和同理心显著降低。此外,当参与者认为 AI 参与建议生成时,他们表示更不愿意遵循建议。我们的研究结果表明,即使 AI 是由医生监管的,在收到数字医疗建议时也会出现反 AI 偏见。鉴于 AI 在医学上的巨大潜力,阐明克服这种偏见的方法应该是未来研究的一个重要目标。