Gondode Prakash, Duggal Sakshi, Garg Neha, Sethupathy Surrender, Asai Omshubham, Lohakare Pooja
Department of Anesthesiology Pain Medicine and Critical Care, All India Institute of Medical Sciences (AIIMS) New Delhi, India.
Department of Anesthesiology, All India Institute of Medical Sciences, Nagpur, Maharashtra, India.
Indian J Anaesth. 2024 Jul;68(7):631-636. doi: 10.4103/ija.ija_204_24. Epub 2024 Jun 7.
Artificial intelligence (AI) chatbots like Conversational Generative Pre-trained Transformer (ChatGPT) have recently created much buzz, especially regarding patient education. Such informed patients understand and adhere to the management and get involved in shared decision making. The accuracy and understandability of the generated educational material are prime concerns. Thus, we compared ChatGPT with traditional patient information leaflets (PILs) about chronic pain medications.
Patients' frequently asked questions were generated from PILs available on the official websites of the British Pain Society (BPS) and the Faculty of Pain Medicine. Eight blinded annexures were prepared for evaluation, consisting of traditional PILs from the BPS and AI-generated patient information materials structured similar to PILs by ChatGPT. The authors performed a comparative analysis to assess materials' readability, emotional tone, accuracy, actionability, and understandability. Readability was measured using Flesch Reading Ease (FRE), Gunning Fog Index (GFI), and Flesch-Kincaid Grade Level (FKGL). Sentiment analysis determined emotional tone. An expert panel evaluated accuracy and completeness. Actionability and understandability were assessed with the Patient Education Materials Assessment Tool.
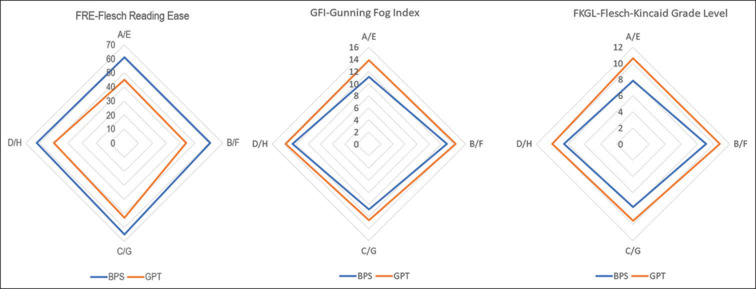
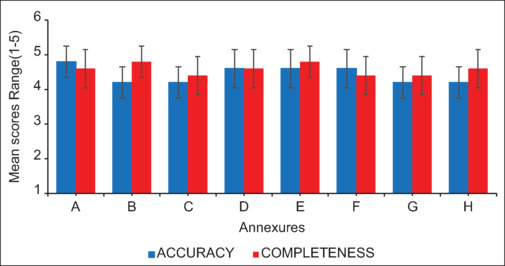
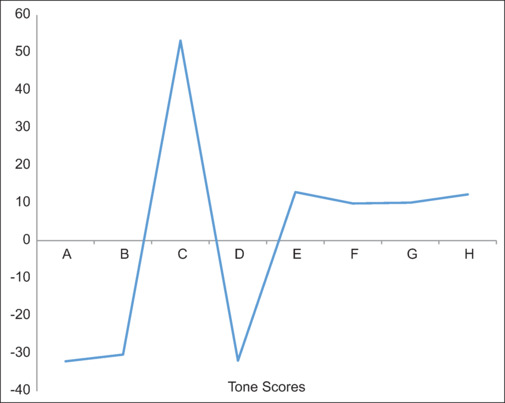
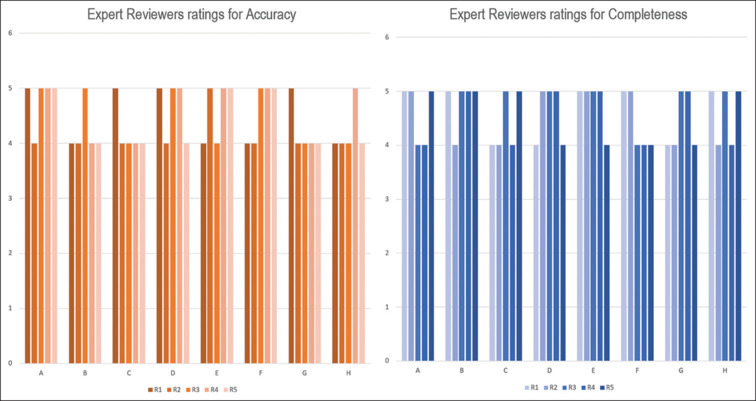
Traditional PILs generally exhibited higher readability ( values < 0.05), with [mean (standard deviation)] FRE [62.25 (1.6) versus 48 (3.7)], GFI [11.85 (0.9) versus 13.65 (0.7)], and FKGL [8.33 (0.5) versus 10.23 (0.5)] but varied emotional tones, often negative, compared to more positive sentiments in ChatGPT-generated texts. Accuracy and completeness did not significantly differ between the two. Actionability and understandability scores were comparable.
While AI chatbots offer efficient information delivery, ensuring accuracy and readability, patient-centeredness remains crucial. It is imperative to balance innovation with evidence-based practice.
诸如对话式生成预训练变换器(ChatGPT)之类的人工智能(AI)聊天机器人最近引起了广泛关注,尤其是在患者教育方面。此类知识渊博的患者能够理解并坚持治疗方案,并参与共同决策。所生成教育材料的准确性和易懂性是首要关注点。因此,我们将ChatGPT与关于慢性疼痛药物的传统患者信息手册(PIL)进行了比较。
从英国疼痛学会(BPS)和疼痛医学学院官方网站上的PIL中生成患者常见问题。准备了八份用于评估的盲法附件,包括来自BPS的传统PIL以及由ChatGPT生成的结构与PIL相似的AI生成患者信息材料。作者进行了比较分析,以评估材料的可读性、情感基调、准确性、可操作性和易懂性。使用弗莱什阅读简易度(FRE)、冈宁雾度指数(GFI)和弗莱什 - 金凯德年级水平(FKGL)来衡量可读性。情感分析确定情感基调。一个专家小组评估准确性和完整性。使用患者教育材料评估工具评估可操作性和易懂性。
传统PIL通常表现出更高的可读性(值<0.05),其[均值(标准差)]FRE[62.25(1.6)对48(3.7)],GFI[11.85(0.9)对13.65(0.7)],以及FKGL[8.33(0.5)对10.23(0.5)],但与ChatGPT生成文本中更积极的情感相比,情感基调各不相同,且往往为负面。两者在准确性和完整性方面没有显著差异。可操作性和易懂性得分相当。
虽然AI聊天机器人能提供高效的信息传递,确保准确性和可读性,但以患者为中心仍然至关重要。必须在创新与循证实践之间取得平衡。