Division of Gastrointestinal and Minimally Invasive Surgery, Department of Surgery, Atrium Health Carolinas Medical Center, Charlotte, North Carolina.
Department of Economics, Massachusetts Institute of Technology, Cambridge.
JAMA Netw Open. 2024 Aug 1;7(8):e2425373. doi: 10.1001/jamanetworkopen.2024.25373.
Artificial intelligence (AI) has permeated academia, especially OpenAI Chat Generative Pretrained Transformer (ChatGPT), a large language model. However, little has been reported on its use in medical research.
To assess a chatbot's capability to generate and grade medical research abstracts.
DESIGN, SETTING, AND PARTICIPANTS: In this cross-sectional study, ChatGPT versions 3.5 and 4.0 (referred to as chatbot 1 and chatbot 2) were coached to generate 10 abstracts by providing background literature, prompts, analyzed data for each topic, and 10 previously presented, unassociated abstracts to serve as models. The study was conducted between August 2023 and February 2024 (including data analysis).
Abstract versions utilizing the same topic and data were written by a surgical trainee or a senior physician or generated by chatbot 1 and chatbot 2 for comparison. The 10 training abstracts were written by 8 surgical residents or fellows, edited by the same senior surgeon, at a high-volume hospital in the Southeastern US with an emphasis on outcomes-based research. Abstract comparison was then based on 10 abstracts written by 5 surgical trainees within the first 6 months of their research year, edited by the same senior author.
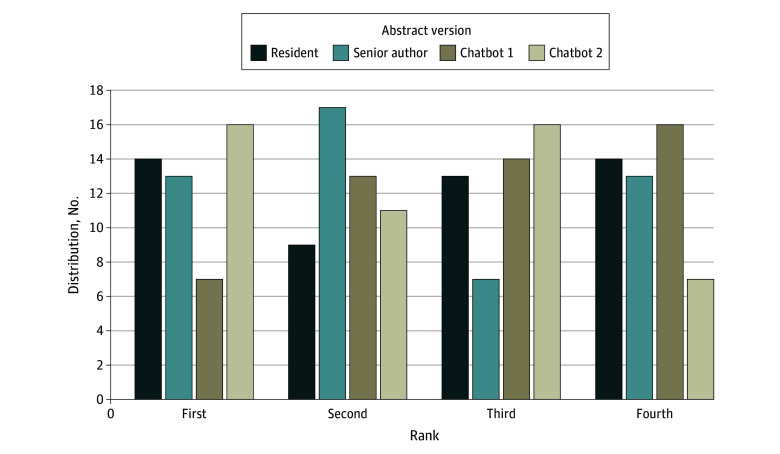
The primary outcome measurements were the abstract grades using 10- and 20-point scales and ranks (first to fourth). Abstract versions by chatbot 1, chatbot 2, junior residents, and the senior author were compared and judged by blinded surgeon-reviewers as well as both chatbot models. Five academic attending surgeons from Denmark, the UK, and the US, with extensive experience in surgical organizations, research, and abstract evaluation served as reviewers.
Surgeon-reviewers were unable to differentiate between abstract versions. Each reviewer ranked an AI-generated version first at least once. Abstracts demonstrated no difference in their median (IQR) 10-point scores (resident, 7.0 [6.0-8.0]; senior author, 7.0 [6.0-8.0]; chatbot 1, 7.0 [6.0-8.0]; chatbot 2, 7.0 [6.0-8.0]; P = .61), 20-point scores (resident, 14.0 [12.0-7.0]; senior author, 15.0 [13.0-17.0]; chatbot 1, 14.0 [12.0-16.0]; chatbot 2, 14.0 [13.0-16.0]; P = .50), or rank (resident, 3.0 [1.0-4.0]; senior author, 2.0 [1.0-4.0]; chatbot 1, 3.0 [2.0-4.0]; chatbot 2, 2.0 [1.0-3.0]; P = .14). The abstract grades given by chatbot 1 were comparable to the surgeon-reviewers' grades. However, chatbot 2 graded more favorably than the surgeon-reviewers and chatbot 1. Median (IQR) chatbot 2-reviewer grades were higher than surgeon-reviewer grades of all 4 abstract versions (resident, 14.0 [12.0-17.0] vs 16.9 [16.0-17.5]; P = .02; senior author, 15.0 [13.0-17.0] vs 17.0 [16.5-18.0]; P = .03; chatbot 1, 14.0 [12.0-16.0] vs 17.8 [17.5-18.5]; P = .002; chatbot 2, 14.0 [13.0-16.0] vs 16.8 [14.5-18.0]; P = .04). When comparing the grades of the 2 chatbots, chatbot 2 gave higher median (IQR) grades for abstracts than chatbot 1 (resident, 14.0 [13.0-15.0] vs 16.9 [16.0-17.5]; P = .003; senior author, 13.5 [13.0-15.5] vs 17.0 [16.5-18.0]; P = .004; chatbot 1, 14.5 [13.0-15.0] vs 17.8 [17.5-18.5]; P = .003; chatbot 2, 14.0 [13.0-15.0] vs 16.8 [14.5-18.0]; P = .01).
In this cross-sectional study, trained chatbots generated convincing medical abstracts, undifferentiable from resident or senior author drafts. Chatbot 1 graded abstracts similarly to surgeon-reviewers, while chatbot 2 was less stringent. These findings may assist surgeon-scientists in successfully implementing AI in medical research.
重要性:人工智能(AI)已经渗透到学术界,尤其是大型语言模型 OpenAI ChatGPT。然而,关于其在医学研究中的应用,鲜有报道。
目的:评估聊天机器人生成和评分医学研究摘要的能力。
设计、地点和参与者:在这项横断面研究中,我们对 ChatGPT 版本 3.5 和 4.0(分别称为聊天机器人 1 和聊天机器人 2)进行了培训,让它们根据背景文献、提示生成 10 篇摘要,并分析了每个主题的数据,以及 10 篇以前呈现的、不相关的摘要作为模型。研究于 2023 年 8 月至 2024 年 2 月进行(包括数据分析)。
暴露:利用相同主题和数据生成的摘要版本由外科住院医师或高级医师撰写,或由聊天机器人 1 和聊天机器人 2 生成进行比较。这 10 篇培训摘要由 8 名外科住院医师或研究员撰写,由同一名高级外科医生编辑,该研究在位于美国东南部的一家重视基于结果的研究的高容量医院进行。然后,根据前 6 个月研究期间的 5 名外科住院医师撰写的 10 篇摘要,基于 10 点和 20 点评分(第一至第四)进行比较。
主要结果和测量:主要结果测量指标是使用 10 点和 20 点评分(第一至第四)以及排名(第一至第四)的摘要等级。比较了聊天机器人 1、聊天机器人 2、初级住院医师和高级作者的摘要版本,并由盲审外科医生评审员以及两个聊天机器人模型进行判断。来自丹麦、英国和美国的 5 名学术主治外科医生,在外科组织、研究和摘要评估方面拥有丰富的经验,担任评审员。
结果:外科医生评审员无法区分摘要版本。每位评审员至少有一次将 AI 生成的版本排名第一。摘要的中位数(IQR)10 分评分没有差异(住院医师,7.0[6.0-8.0];高级作者,7.0[6.0-8.0];聊天机器人 1,7.0[6.0-8.0];聊天机器人 2,7.0[6.0-8.0];P=0.61),20 分评分(住院医师,14.0[12.0-7.0];高级作者,15.0[13.0-17.0];聊天机器人 1,14.0[12.0-16.0];聊天机器人 2,14.0[13.0-16.0];P=0.50)或排名(住院医师,3.0[1.0-4.0];高级作者,2.0[1.0-4.0];聊天机器人 1,3.0[2.0-4.0];聊天机器人 2,2.0[1.0-3.0];P=0.14)。聊天机器人 1 给出的摘要等级与外科医生评审员的等级相当。然而,聊天机器人 2 的评分比外科医生评审员和聊天机器人 1 更有利。聊天机器人 2 评审员的中位数(IQR)评分高于所有 4 个摘要版本的外科医生评审员评分(住院医师,14.0[12.0-17.0] vs 16.9[16.0-17.5];P=0.02;高级作者,15.0[13.0-17.0] vs 17.0[16.5-18.0];P=0.03;聊天机器人 1,14.0[12.0-16.0] vs 17.8[17.5-18.5];P=0.002;聊天机器人 2,14.0[13.0-16.0] vs 16.8[14.5-18.0];P=0.04)。当比较这两个聊天机器人的评分时,聊天机器人 2 对摘要的中位数(IQR)评分高于聊天机器人 1(住院医师,14.0[13.0-15.0] vs 16.9[16.0-17.5];P=0.003;高级作者,13.5[13.0-15.5] vs 17.0[16.5-18.0];P=0.004;聊天机器人 1,14.5[13.0-15.0] vs 17.8[17.5-18.5];P=0.003;聊天机器人 2,14.0[13.0-15.0] vs 16.8[14.5-18.0];P=0.01)。
结论和相关性:在这项横断面研究中,经过训练的聊天机器人生成了令人信服的医学摘要,与住院医师或高级作者的草稿无法区分。聊天机器人 1 对摘要的评分与外科医生评审员相似,而聊天机器人 2 则较为宽松。这些发现可能有助于外科医生科学家在医学研究中成功实施 AI。