Department of Surgery, University of California, San Francisco.
Department of Medicine, University of California, San Francisco.
JAMA Netw Open. 2023 Oct 2;6(10):e2336997. doi: 10.1001/jamanetworkopen.2023.36997.
Informed consent is a critical component of patient care before invasive procedures, yet it is frequently inadequate. Electronic consent forms have the potential to facilitate patient comprehension if they provide information that is readable, accurate, and complete; it is not known if large language model (LLM)-based chatbots may improve informed consent documentation by generating accurate and complete information that is easily understood by patients.
To compare the readability, accuracy, and completeness of LLM-based chatbot- vs surgeon-generated information on the risks, benefits, and alternatives (RBAs) of common surgical procedures.
DESIGN, SETTING, AND PARTICIPANTS: This cross-sectional study compared randomly selected surgeon-generated RBAs used in signed electronic consent forms at an academic referral center in San Francisco with LLM-based chatbot-generated (ChatGPT-3.5, OpenAI) RBAs for 6 surgical procedures (colectomy, coronary artery bypass graft, laparoscopic cholecystectomy, inguinal hernia repair, knee arthroplasty, and spinal fusion).
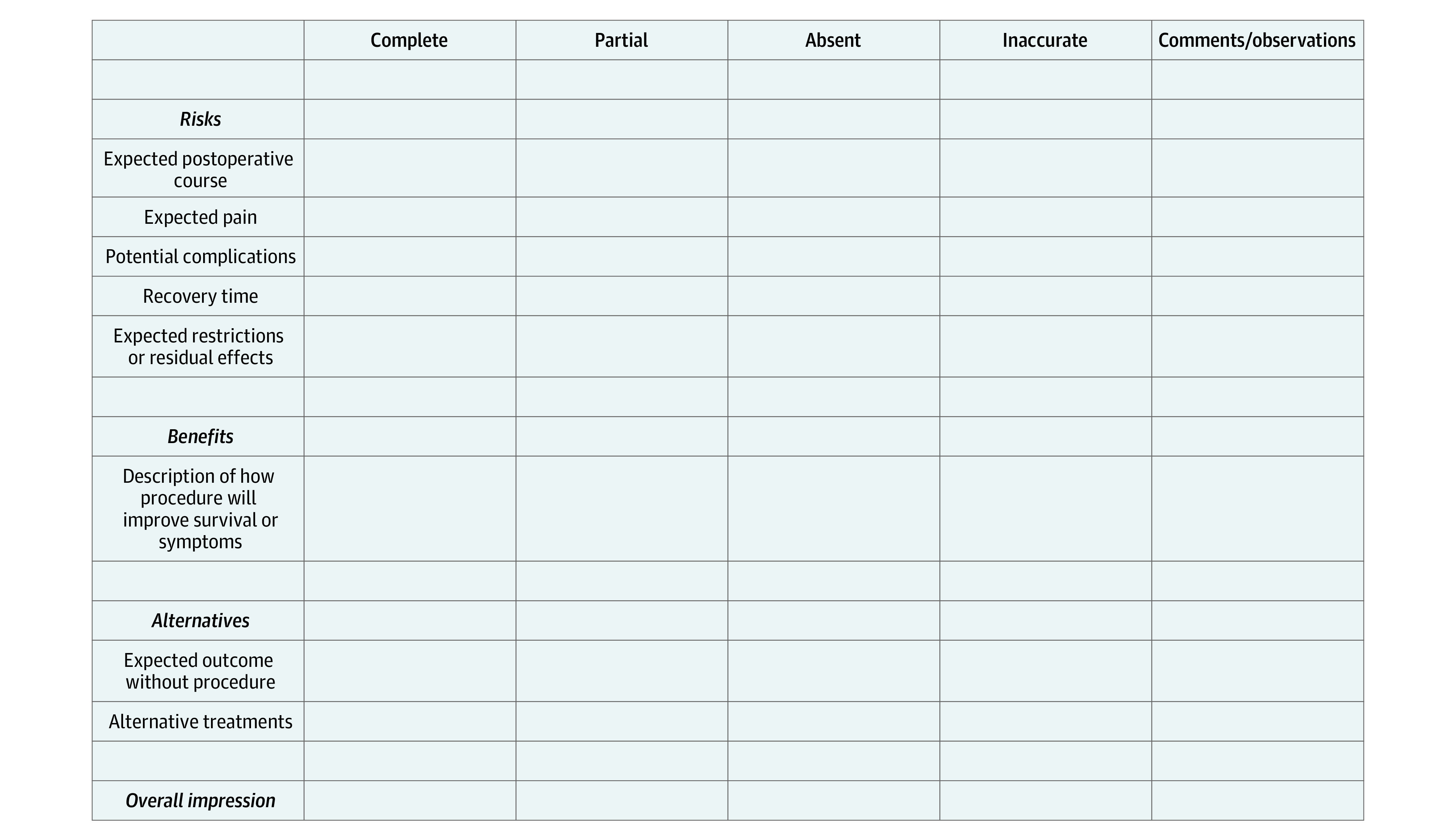
Readability was measured using previously validated scales (Flesh-Kincaid grade level, Gunning Fog index, the Simple Measure of Gobbledygook, and the Coleman-Liau index). Scores range from 0 to greater than 20 to indicate the years of education required to understand a text. Accuracy and completeness were assessed using a rubric developed with recommendations from LeapFrog, the Joint Commission, and the American College of Surgeons. Both composite and RBA subgroup scores were compared.
The total sample consisted of 36 RBAs, with 1 RBA generated by the LLM-based chatbot and 5 RBAs generated by a surgeon for each of the 6 surgical procedures. The mean (SD) readability score for the LLM-based chatbot RBAs was 12.9 (2.0) vs 15.7 (4.0) for surgeon-generated RBAs (P = .10). The mean (SD) composite completeness and accuracy score was lower for surgeons' RBAs at 1.6 (0.5) than for LLM-based chatbot RBAs at 2.2 (0.4) (P < .001). The LLM-based chatbot scores were higher than the surgeon-generated scores for descriptions of the benefits of surgery (2.3 [0.7] vs 1.4 [0.7]; P < .001) and alternatives to surgery (2.7 [0.5] vs 1.4 [0.7]; P < .001). There was no significant difference in chatbot vs surgeon RBA scores for risks of surgery (1.7 [0.5] vs 1.7 [0.4]; P = .38).
The findings of this cross-sectional study suggest that despite not being perfect, LLM-based chatbots have the potential to enhance informed consent documentation. If an LLM were embedded in electronic health records in a manner compliant with the Health Insurance Portability and Accountability Act, it could be used to provide personalized risk information while easing documentation burden for physicians.
知情同意是侵入性手术前患者护理的重要组成部分,但它经常不充分。如果电子同意书能够提供易于理解的可读、准确和完整的信息,那么它们有可能促进患者的理解;目前尚不清楚大型语言模型 (LLM) 为基础的聊天机器人是否可以通过生成易于患者理解的准确和完整信息来改善知情同意文件。
比较 LLM 为基础的聊天机器人生成的与外科医生生成的关于常见手术风险、益处和替代方案 (RBA) 的信息的可读性、准确性和完整性。
设计、设置和参与者:这项横断面研究比较了旧金山一家学术转诊中心电子同意书中随机选择的外科医生生成的 RBA 与 LLM 为基础的聊天机器人生成的(ChatGPT-3.5、OpenAI)6 种手术(结肠切除术、冠状动脉旁路移植术、腹腔镜胆囊切除术、腹股沟疝修补术、膝关节置换术和脊柱融合术)的 RBA。
使用以前验证过的量表(Flesh-Kincaid 年级水平、Gunning Fog 指数、简单 Googlegook 量表和 Coleman-Liau 指数)来衡量可读性。得分范围从 0 到 20 以上,表示理解文本所需的教育年限。使用 LeapFrog、联合委员会和美国外科医生学院的建议制定的评分标准来评估准确性和完整性。比较了综合和 RBA 亚组得分。
总样本包括 36 份 RBA,其中 1 份由 LLM 为基础的聊天机器人生成,6 种手术中每种手术由 5 份由外科医生生成。LLM 为基础的聊天机器人生成的 RBA 的平均(SD)可读性评分为 12.9(2.0),而外科医生生成的 RBA 为 15.7(4.0)(P=0.10)。外科医生生成的 RBA 的平均(SD)综合完整性和准确性评分为 1.6(0.5),而 LLM 为基础的聊天机器人生成的 RBA 为 2.2(0.4)(P<0.001)。LLM 为基础的聊天机器人的评分高于外科医生生成的手术益处描述(2.3[0.7]与 1.4[0.7];P<0.001)和手术替代方案(2.7[0.5]与 1.4[0.7];P<0.001)。手术风险的聊天机器人与外科医生 RBA 评分无显著差异(1.7[0.5]与 1.7[0.4];P=0.38)。
这项横断面研究的结果表明,尽管不完美,但 LLM 为基础的聊天机器人有可能增强知情同意文件。如果 LLM 以符合《健康保险流通与责任法案》的方式嵌入电子健康记录中,它可以用于提供个性化的风险信息,同时减轻医生的文件负担。