Dim Cleyton Aparecido, Neto Nelson Cruz Sampaio, de Morais Jefferson Magalhães
Federal University of Para - Institute of Exact and Natural Sciences, Rua Augusto Corrêa, 01 - Campus Universitário do Guamá - Belém, Pará, 66.075-110, Brazil.
Data Brief. 2024 Jul 14;55:110678. doi: 10.1016/j.dib.2024.110678. eCollection 2024 Aug.
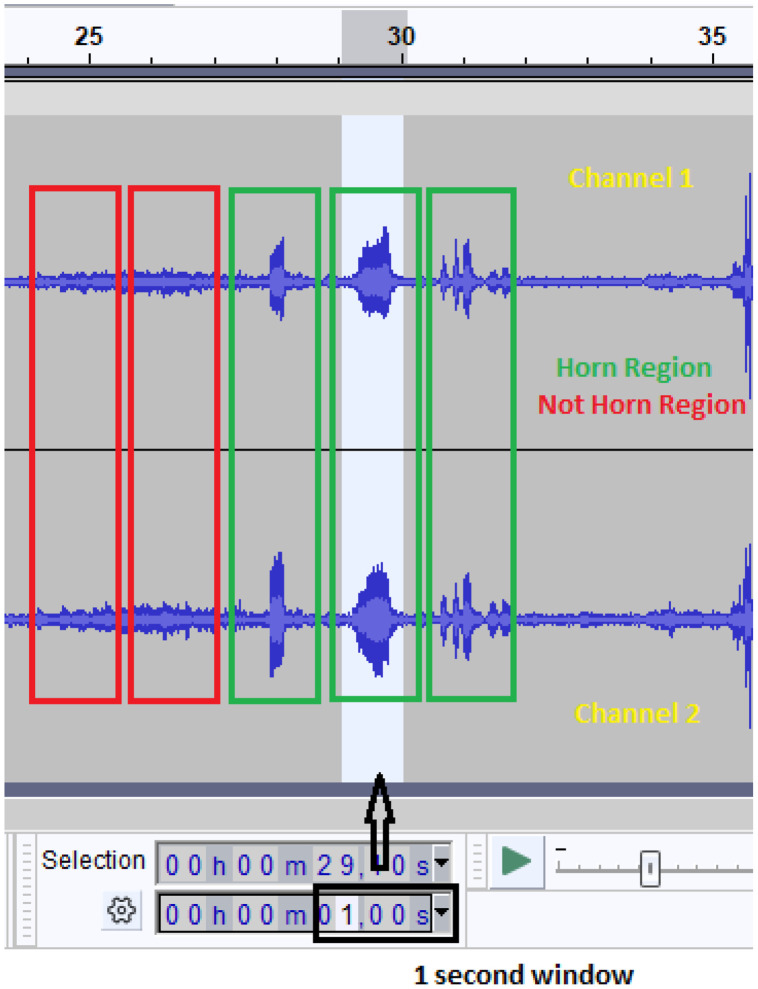
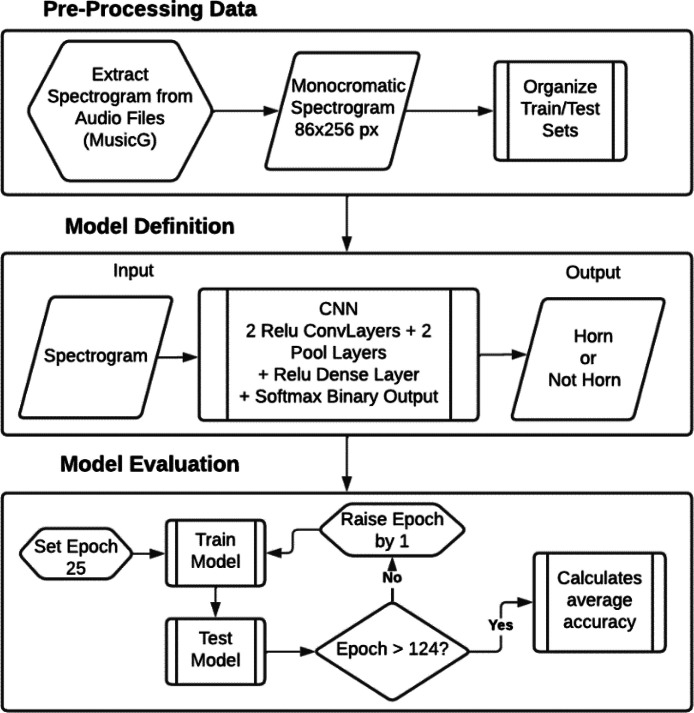
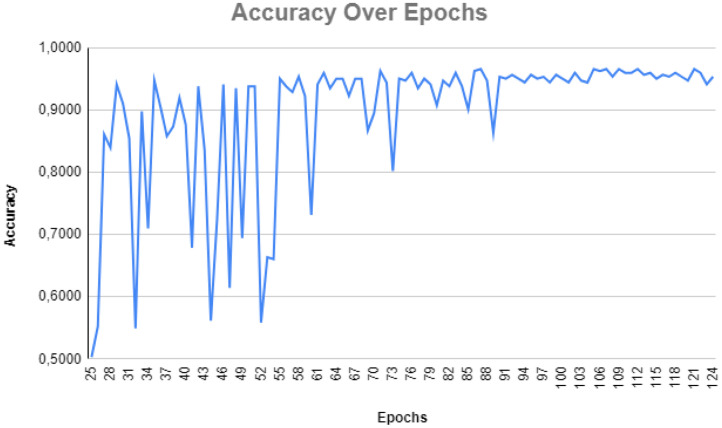
In recent years, there has been significant growth in the development of Machine Learning (ML) models across various fields, such as image and sound recognition and natural language processing. They need to be trained with a large enough data set, ensuring predictions or results are as accurate as possible. When it comes to models for audio recognition, specifically the detection of car horns, the datasets are generally not built considering the specificities of the different scenarios that may exist in real traffic, being limited to collections of random horns, whose sources are sometimes collected from audio streaming sites. There are benefits associated with a ML model trained on data tailored for horn detection. One notable advantage is the potential implementation of horn detection in smartphones and smartwatches equipped with embedded models to aid hearing-impaired individuals while driving and alert them in potentially hazardous situations, thus promoting social inclusion. Given these considerations, we developed a dataset specifically for car horns. This dataset has 1,080 one-second-long .wav audio files categorized into two classes: horn and not horn. The data collection followed a carefully established protocol designed to encompass different scenarios in a real traffic environment, considering diverse relative positions between the involved vehicles. The protocol defines ten distinct scenarios, incorporating variables within the car receiving the horn, including the presence of internal conversations, music, open or closed windows, engine status (on or off), and whether the car is stationary or in motion. Additionally, there are variations in scenarios associated with the vehicle emitting the horn, such as its relative position-behind, alongside, or in front of the receiving vehicle-and the types of horns used, which may include a short honk, a prolonged one, or a rhythmic pattern of three quick honks. The data collection process started with simultaneous audio recordings on two smartphones positioned inside the receiving vehicle, capturing all scenarios in a single audio file on each device. A 400-meter route was defined in a controlled area, so the audio recordings could be carried out safely. For each established scenario, the route was covered with emissions of different types of horns in distinct positions between the vehicles, and then the route was restarted in the next scenario. After the collection phase, the data preprocessing involved manually cutting each horn sound in multiple one-second windowing profiles, saving them in PCM stereo .wav files with a 16-bit depth and a 44.1 kHz sampling rate. For each horn clipping, a corresponding non-horn clipping in close proximity was performed, ensuring a balanced model. This dataset was designed for utilization in various machine learning algorithms, whether for detecting horns with the binary labels, or classifying different patterns of horns by rearranging labels considering the file nomenclature. In technical validation, classifications were performed using a convolutional neural network trained with spectrograms from the dataset's audio, achieving an average accuracy of 89% across 100 trained models.

近年来,机器学习(ML)模型在各个领域都有了显著发展,如图像和声音识别以及自然语言处理。这些模型需要用足够大的数据集进行训练,以确保预测或结果尽可能准确。在音频识别模型方面,特别是汽车喇叭检测,数据集通常没有考虑到实际交通中可能存在的不同场景的特殊性,仅限于随机喇叭的收集,其来源有时是从音频流网站收集的。使用专门为喇叭检测量身定制的数据训练的ML模型有诸多好处。一个显著的优势是,有可能在配备嵌入式模型的智能手机和智能手表中实现喇叭检测,以帮助听力受损者在驾驶时,并在潜在危险情况下提醒他们,从而促进社会包容。考虑到这些因素,我们专门开发了一个汽车喇叭数据集。这个数据集有1080个一秒长的.wav音频文件,分为两类:喇叭和非喇叭。数据收集遵循了精心制定的协议,旨在涵盖真实交通环境中的不同场景,考虑到相关车辆之间的各种相对位置。该协议定义了十种不同的场景,纳入了接收喇叭的汽车内部的变量,包括内部对话、音乐的存在、窗户打开或关闭、发动机状态(开或关)以及汽车是静止还是行驶。此外,与发出喇叭的车辆相关的场景也有变化,例如其相对位置——在接收车辆后面、旁边或前面——以及使用的喇叭类型,可能包括短按喇叭、长按喇叭或三声快速喇叭的节奏模式。数据收集过程首先在位于接收车辆内的两部智能手机上同时进行音频录制,在每个设备上的单个音频文件中捕捉所有场景。在一个受控区域定义了一条400米的路线,以便安全地进行音频录制。对于每个既定场景,在车辆之间的不同位置用不同类型的喇叭发出声音覆盖该路线,然后在下一个场景中重新开始该路线。在收集阶段之后,数据预处理包括在多个一秒的窗口配置文件中手动切割每个喇叭声音,将它们保存为16位深度和44.1kHz采样率的PCM立体声.wav文件。对于每个喇叭剪辑,在其附近进行相应的非喇叭剪辑,以确保模型平衡。这个数据集设计用于各种机器学习算法,无论是用于使用二元标签检测喇叭,还是通过考虑文件命名法重新排列标签来对不同的喇叭模式进行分类。在技术验证中,使用从数据集中的音频频谱图训练的卷积神经网络进行分类,在100个训练模型中平均准确率达到89%。