Terwilliger Emma, Bcharah George, Bcharah Hend, Bcharah Estefana, Richardson Clare, Scheffler Patrick
Otolaryngology, Mayo Clinic Alix School of Medicine, Scottsdale, USA.
Otolaryngology, Andrew Taylor Still University School of Osteopathic Medicine, Mesa, USA.
Cureus. 2024 Jul 9;16(7):e64204. doi: 10.7759/cureus.64204. eCollection 2024 Jul.
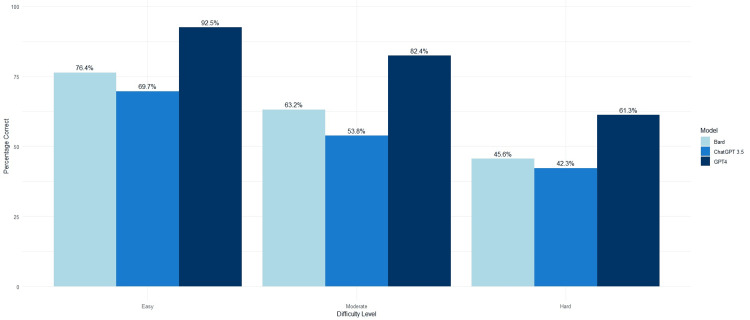
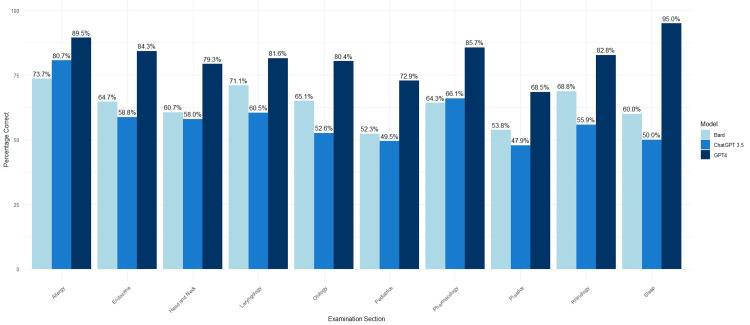
Objective To evaluate and compare the performance of Chat Generative Pre-Trained Transformer (ChatGPT), GPT-4, and Google Bard on United States otolaryngology board-style questions to scale their ability to act as an adjunctive study tool and resource for students and doctors. Methods A 1077 text question and 60 image-based questions from the otolaryngology board exam preparation tool BoardVitals were inputted into ChatGPT, GPT-4, and Google Bard. The questions were scaled true or false, depending on whether the artificial intelligence (AI) modality provided the correct response. Data analysis was performed in R Studio. Results GPT-4 scored the highest at 78.7% compared to ChatGPT and Bard at 55.3% and 61.7% (p<0.001), respectively. In terms of question difficulty, all three AI models performed best on easy questions (ChatGPT: 69.7%, GPT-4: 92.5%, and Bard: 76.4%) and worst on hard questions (ChatGPT: 42.3%, GPT-4: 61.3%, and Bard: 45.6%). Across all difficulty levels, GPT-4 did better than Bard and ChatGPT (p<0.0001). GPT-4 outperformed ChatGPT and Bard in all subspecialty sections, with significantly higher scores (p<0.05) on all sections except allergy (p>0.05). On image-based questions, GPT-4 performed better than Bard (56.7% vs 46.4%, p=0.368) and had better overall image interpretation capabilities. Conclusion This study showed that the GPT-4 model performed better than both ChatGPT and Bard on the United States otolaryngology board practice questions. Although the GPT-4 results were promising, AI should still be used with caution when being implemented in medical education or patient care settings.
目的 评估并比较聊天生成预训练变换器(ChatGPT)、GPT-4和谷歌巴德(Google Bard)在美国耳鼻喉科委员会风格问题上的表现,以衡量它们作为学生和医生辅助学习工具及资源的能力。方法 将来自耳鼻喉科委员会考试备考工具BoardVitals的1077道文本问题和60道基于图像的问题输入ChatGPT、GPT-4和谷歌巴德。根据人工智能(AI)模式是否给出正确答案,问题被判定为真或假。在R Studio中进行数据分析。结果 GPT-4得分最高,为78.7%,而ChatGPT和巴德分别为55.3%和61.7%(p<0.001)。在问题难度方面,所有三个AI模型在简单问题上表现最佳(ChatGPT:69.7%,GPT-4:92.5%,巴德:76.4%),在难题上表现最差(ChatGPT:42.3%,GPT-4:61.3%,巴德:45.6%)。在所有难度级别上,GPT-4的表现优于巴德和ChatGPT(p<0.0001)。GPT-4在所有亚专业领域的表现均优于ChatGPT和巴德,除过敏领域外(p>0.05),在所有领域的得分均显著更高(p<0.05)。在基于图像的问题上,GPT-4的表现优于巴德(56.7%对46.4%,p = 0.368),并且具有更好的整体图像解释能力。结论 本研究表明,在美国耳鼻喉科委员会练习题上,GPT-4模型的表现优于ChatGPT和巴德。尽管GPT-4的结果很有前景,但在医学教育或患者护理环境中应用AI时仍应谨慎使用。