Sallam Malik, Al-Salahat Khaled, Eid Huda, Egger Jan, Puladi Behrus
Department of Pathology, Microbiology and Forensic Medicine, School of Medicine, The University of Jordan, Amman, Jordan.
Department of Clinical Laboratories and Forensic Medicine, Jordan University Hospital, Amman, Jordan.
Adv Med Educ Pract. 2024 Sep 20;15:857-871. doi: 10.2147/AMEP.S479801. eCollection 2024.
Artificial intelligence (AI) chatbots excel in language understanding and generation. These models can transform healthcare education and practice. However, it is important to assess the performance of such AI models in various topics to highlight its strengths and possible limitations. This study aimed to evaluate the performance of ChatGPT (GPT-3.5 and GPT-4), Bing, and Bard compared to human students at a postgraduate master's level in Medical Laboratory Sciences.
The study design was based on the METRICS checklist for the design and reporting of AI-based studies in healthcare. The study utilized a dataset of 60 Clinical Chemistry multiple-choice questions (MCQs) initially conceived for assessing 20 MSc students. The revised Bloom's taxonomy was used as the framework for classifying the MCQs into four cognitive categories: Remember, Understand, Analyze, and Apply. A modified version of the CLEAR tool was used for the assessment of the quality of AI-generated content, with Cohen's κ for inter-rater agreement.
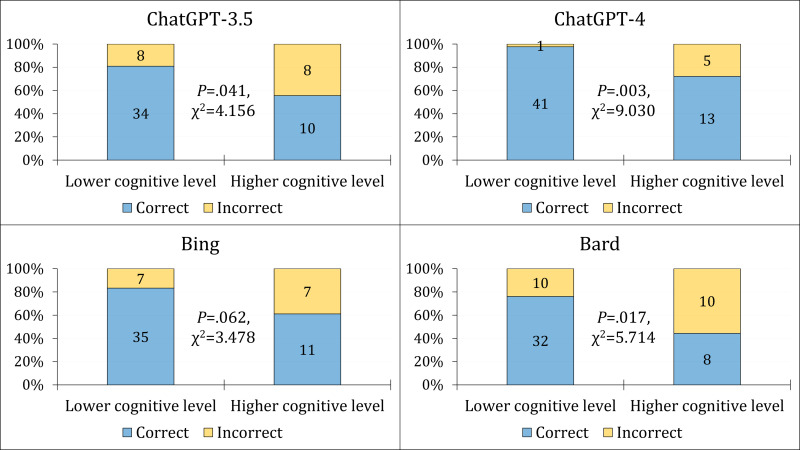
Compared to the mean students' score which was 0.68±0.23, GPT-4 scored 0.90 ± 0.30, followed by Bing (0.77 ± 0.43), GPT-3.5 (0.73 ± 0.45), and Bard (0.67 ± 0.48). Statistically significant better performance was noted in lower cognitive domains (Remember and Understand) in GPT-3.5 (=0.041), GPT-4 (=0.003), and Bard (=0.017) compared to the higher cognitive domains (Apply and Analyze). The CLEAR scores indicated that ChatGPT-4 performance was "Excellent" compared to the "Above average" performance of ChatGPT-3.5, Bing, and Bard.
The findings indicated that ChatGPT-4 excelled in the Clinical Chemistry exam, while ChatGPT-3.5, Bing, and Bard were above average. Given that the MCQs were directed to postgraduate students with a high degree of specialization, the performance of these AI chatbots was remarkable. Due to the risk of academic dishonesty and possible dependence on these AI models, the appropriateness of MCQs as an assessment tool in higher education should be re-evaluated.
人工智能(AI)聊天机器人在语言理解和生成方面表现出色。这些模型可以改变医疗保健教育和实践。然而,评估此类AI模型在各个主题中的性能以突出其优势和可能的局限性非常重要。本研究旨在评估ChatGPT(GPT-3.5和GPT-4)、必应和巴德与医学检验科学专业研究生水平的人类学生相比的性能。
本研究设计基于医疗保健领域基于AI的研究设计和报告的METRICS清单。该研究使用了一个由60道临床化学多项选择题(MCQ)组成的数据集,这些题目最初是为评估20名理学硕士学生而设计的。修订后的布鲁姆分类法被用作将MCQ分为四个认知类别的框架:记忆、理解、分析和应用。使用CLEAR工具的修改版本来评估AI生成内容的质量,并使用科恩κ系数来评估评分者间的一致性。
与学生的平均得分0.68±0.23相比,GPT-4的得分为0.90±0.30,其次是必应(0.77±0.43)、GPT-3.5(0.73±0.45)和巴德(0.67±0.48)。与较高认知领域(应用和分析)相比,GPT-3.5(=0.041)、GPT-4(=0.003)和巴德(=0.017)在较低认知领域(记忆和理解)的表现具有统计学意义上的显著优势。CLEAR分数表明,与ChatGPT-3.5、必应和巴德的“高于平均水平”表现相比,ChatGPT-4的表现为“优秀”。
研究结果表明,ChatGPT-4在临床化学考试中表现出色,而ChatGPT-3.5、必应和巴德的表现高于平均水平。鉴于这些MCQ是针对高度专业化的研究生的,这些AI聊天机器人的表现非常出色。由于存在学术不诚实的风险以及可能对这些AI模型的依赖,应重新评估MCQ作为高等教育评估工具的适用性。