Sood Priyanka Dua, Liu Star, Lehmann Harold, Kharrazi Hadi
Bloomberg School of Public Health, Johns Hopkins University, 615 N Wolfe St, Baltimore, MD, 21205, United States, 1 443-287-8264.
School of Medicine, Johns Hopkins University, Baltimore, MD, United States.
JMIR Med Inform. 2024 Aug 27;12:e56734. doi: 10.2196/56734.
Increasing and substantial reliance on electronic health records (EHRs) and data types (ie, diagnosis, medication, and laboratory data) demands assessment of their data quality as a fundamental approach, especially since there is a need to identify appropriate denominator populations with chronic conditions, such as type 2 diabetes (T2D), using commonly available computable phenotype definitions (ie, phenotypes).
To bridge this gap, our study aims to assess how issues of EHR data quality and variations and robustness (or lack thereof) in phenotypes may have potential impacts in identifying denominator populations.
Approximately 208,000 patients with T2D were included in our study, which used retrospective EHR data from the Johns Hopkins Medical Institution (JHMI) during 2017-2019. Our assessment included 4 published phenotypes and 1 definition from a panel of experts at Hopkins. We conducted descriptive analyses of demographics (ie, age, sex, race, and ethnicity), use of health care (inpatient and emergency room visits), and the average Charlson Comorbidity Index score of each phenotype. We then used different methods to induce or simulate data quality issues of completeness, accuracy, and timeliness separately across each phenotype. For induced data incompleteness, our model randomly dropped diagnosis, medication, and laboratory codes independently at increments of 10%; for induced data inaccuracy, our model randomly replaced a diagnosis or medication code with another code of the same data type and induced 2% incremental change from -100% to +10% in laboratory result values; and lastly, for timeliness, data were modeled for induced incremental shift of date records by 30 days to 365 days.
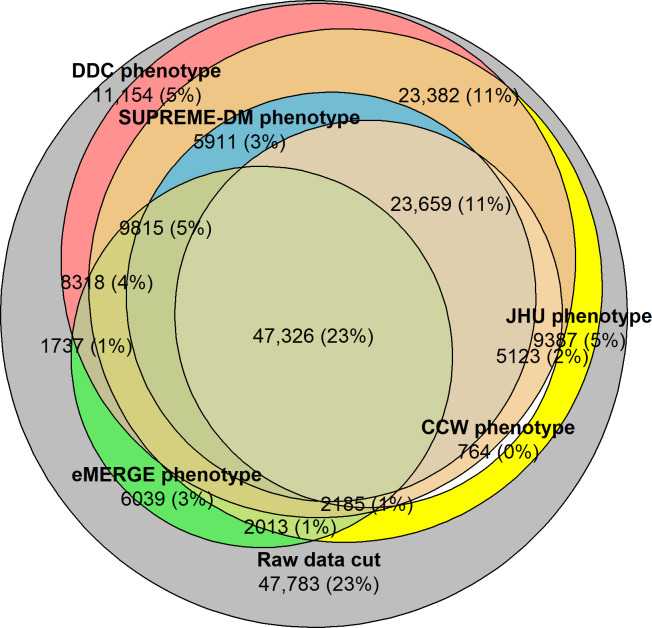
Less than a quarter (n=47,326, 23%) of the population overlapped across all phenotypes using EHRs. The population identified by each phenotype varied across all combinations of data types. Induced incompleteness identified fewer patients with each increment; for example, at 100% diagnostic incompleteness, the Chronic Conditions Data Warehouse phenotype identified zero patients, as its phenotypic characteristics included only diagnosis codes. Induced inaccuracy and timeliness similarly demonstrated variations in performance of each phenotype, therefore resulting in fewer patients being identified with each incremental change.
We used EHR data with diagnosis, medication, and laboratory data types from a large tertiary hospital system to understand T2D phenotypic differences and performance. We used induced data quality methods to learn how data quality issues may impact identification of the denominator populations upon which clinical (eg, clinical research and trials, population health evaluations) and financial or operational decisions are made. The novel results from our study may inform future approaches to shaping a common T2D computable phenotype definition that can be applied to clinical informatics, managing chronic conditions, and additional industry-wide efforts in health care.
对电子健康记录(EHR)及数据类型(即诊断、用药和实验室数据)的依赖日益增加且程度可观,这就需要将数据质量评估作为一种基本方法,特别是因为有必要使用常见的可计算表型定义(即表型)来识别患有慢性病(如2型糖尿病(T2D))的合适分母人群。
为弥补这一差距,我们的研究旨在评估EHR数据质量问题以及表型的变异性和稳健性(或缺乏稳健性)如何可能对识别分母人群产生潜在影响。
我们的研究纳入了约208,000例T2D患者,使用了约翰霍普金斯医疗机构(JHMI)2017 - 2019年的回顾性EHR数据。我们的评估包括4种已发表的表型和来自霍普金斯专家小组的1种定义。我们对人口统计学特征(即年龄、性别、种族和民族)、医疗保健使用情况(住院和急诊就诊)以及每种表型的平均查尔森合并症指数得分进行了描述性分析。然后,我们使用不同方法分别针对每种表型诱导或模拟完整性、准确性和及时性方面的数据质量问题。对于诱导的数据不完整性,我们的模型以10%的增量独立随机删除诊断、用药和实验室代码;对于诱导的数据不准确,我们的模型用相同数据类型的另一个代码随机替换诊断或用药代码,并在实验室结果值中诱导从 - 100%到 + 10%的2%增量变化;最后,对于及时性,对数据进行建模,以诱导日期记录的增量偏移30天至365天。
使用EHR的情况下,所有表型中重叠的人群不到四分之一(n = 47,326,23%)。每种表型识别出的人群在所有数据类型组合中各不相同。诱导的不完整性随着每次增量识别出的患者减少;例如,在100%诊断不完整时,慢性病数据仓库表型识别出零患者,因为其表型特征仅包括诊断代码。诱导的不准确和及时性同样显示出每种表型性能的差异,因此每次增量变化识别出的患者也更少。
我们使用了来自大型三级医院系统的包含诊断、用药和实验室数据类型的EHR数据,以了解T2D表型差异和性能。我们使用诱导数据质量方法来了解数据质量问题如何可能影响分母人群的识别,而临床(如临床研究和试验、人群健康评估)以及财务或运营决策都是基于这些分母人群做出的。我们研究的新结果可能为未来塑造通用的T2D可计算表型定义的方法提供参考,该定义可应用于临床信息学、慢性病管理以及医疗保健领域的其他全行业努力。







