TUM (Technical University of Munich), School of Computation, Information and Technology (CIT), Faculty of Informatics, Chair of Bioinformatics & Computational Biology - i12, Garching/Munich, Germany.
TUM Graduate School, Center of Doctoral Studies in Informatics and its Applications (CeDoSIA), Garching/Munich, Germany.
Nat Commun. 2024 Aug 28;15(1):7407. doi: 10.1038/s41467-024-51844-2.
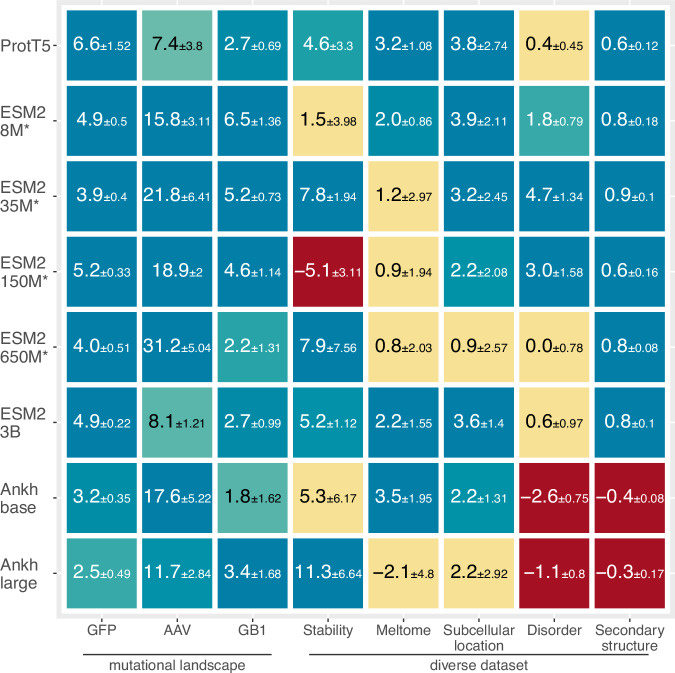
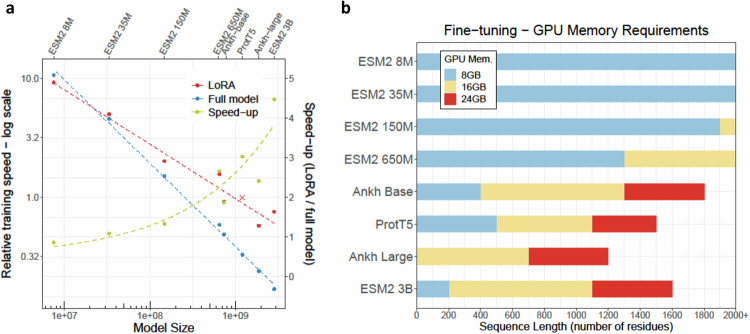
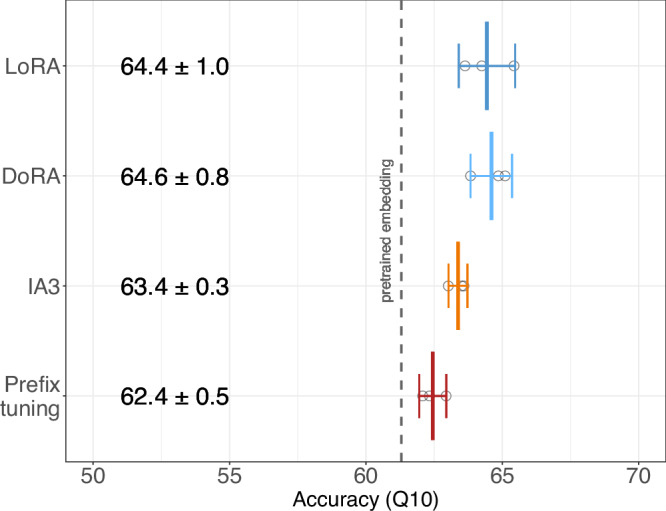
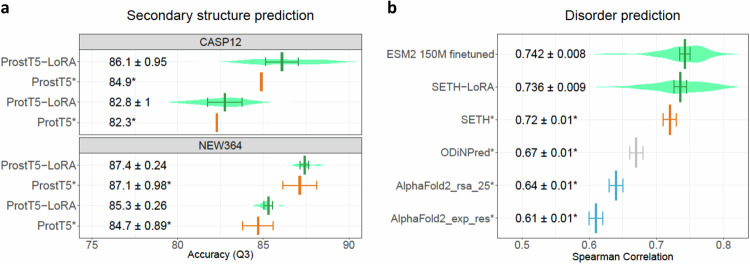
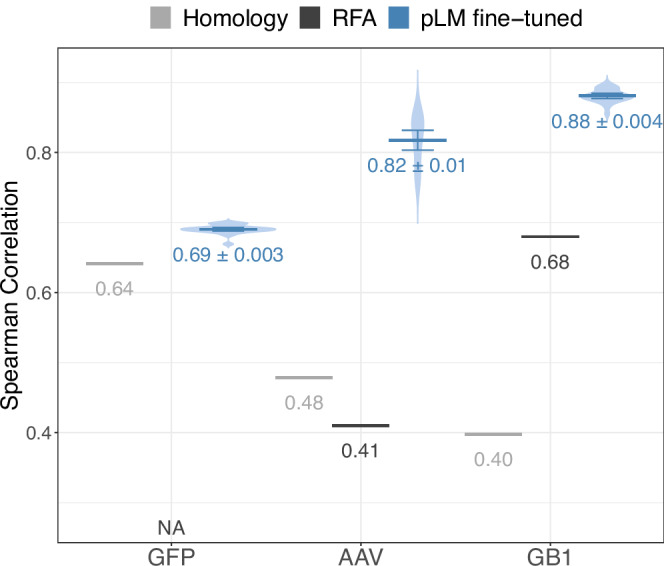
Prediction methods inputting embeddings from protein language models have reached or even surpassed state-of-the-art performance on many protein prediction tasks. In natural language processing fine-tuning large language models has become the de facto standard. In contrast, most protein language model-based protein predictions do not back-propagate to the language model. Here, we compare the fine-tuning of three state-of-the-art models (ESM2, ProtT5, Ankh) on eight different tasks. Two results stand out. Firstly, task-specific supervised fine-tuning almost always improves downstream predictions. Secondly, parameter-efficient fine-tuning can reach similar improvements consuming substantially fewer resources at up to 4.5-fold acceleration of training over fine-tuning full models. Our results suggest to always try fine-tuning, in particular for problems with small datasets, such as for fitness landscape predictions of a single protein. For ease of adaptability, we provide easy-to-use notebooks to fine-tune all models used during this work for per-protein (pooling) and per-residue prediction tasks.
基于蛋白质语言模型的嵌入预测方法在许多蛋白质预测任务上已经达到甚至超过了最新水平。在自然语言处理中,微调大型语言模型已经成为事实上的标准。相比之下,大多数基于蛋白质语言模型的蛋白质预测都不会反向传播到语言模型中。在这里,我们比较了三种最先进的模型(ESM2、ProtT5、Ankh)在八个不同任务上的微调。有两个结果非常突出。首先,特定于任务的监督式微调几乎总是可以改进下游预测。其次,参数高效的微调可以达到类似的改进,消耗的资源要少得多,对于完整模型的微调,可以加速高达 4.5 倍的训练。我们的结果表明,总是应该尝试微调,特别是对于数据集较小的问题,例如单个蛋白质的适应性景观预测。为了便于适应性,我们提供了易于使用的笔记本,用于微调在这项工作中使用的所有模型,用于蛋白质(池化)和残基预测任务。