de Llano García Daniela, Marrero-Ponce Yovani, Agüero-Chapin Guillermin, Ferri Francesc J, Antunes Agostinho, Martinez-Rios Felix, Rodríguez Hortensia
School of Chemical Sciences and Engineering, Yachay Tech University, Hda. San José s/n y Proyecto Yachay, Urcuquí 100119, Imbabura, Ecuador.
Universidad San Francisco de Quito (USFQ), Grupo de Medicina Molecular y Traslacional (MeM&T), Colegio de Ciencias de la Salud (COCSA), Escuela de Medicina, Edificio de Especialidades Médicas, Instituto de Simulación Computacional (ISC-USFQ), Diego de Robles y vía Interoceánica, Quito 170157, Pichincha, Ecuador.
Antibiotics (Basel). 2024 Aug 14;13(8):768. doi: 10.3390/antibiotics13080768.
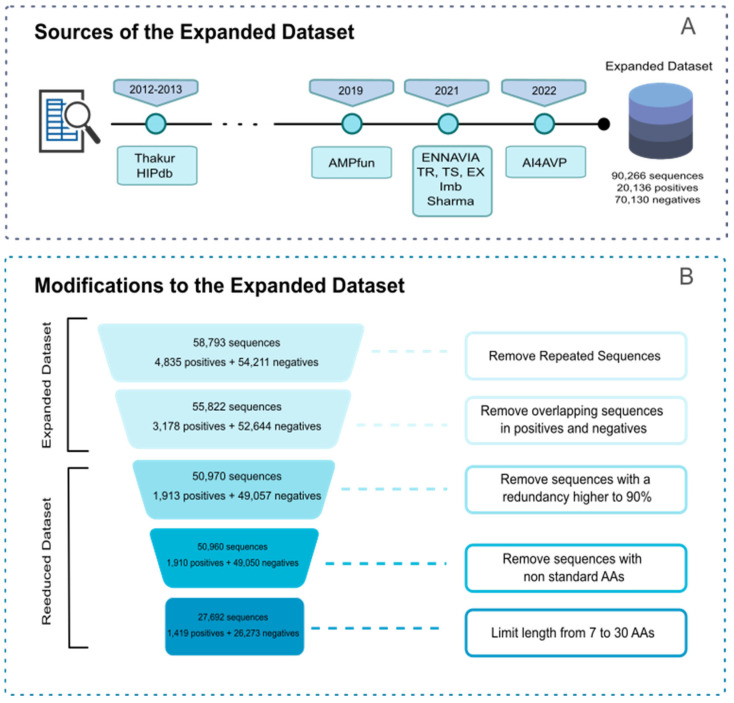
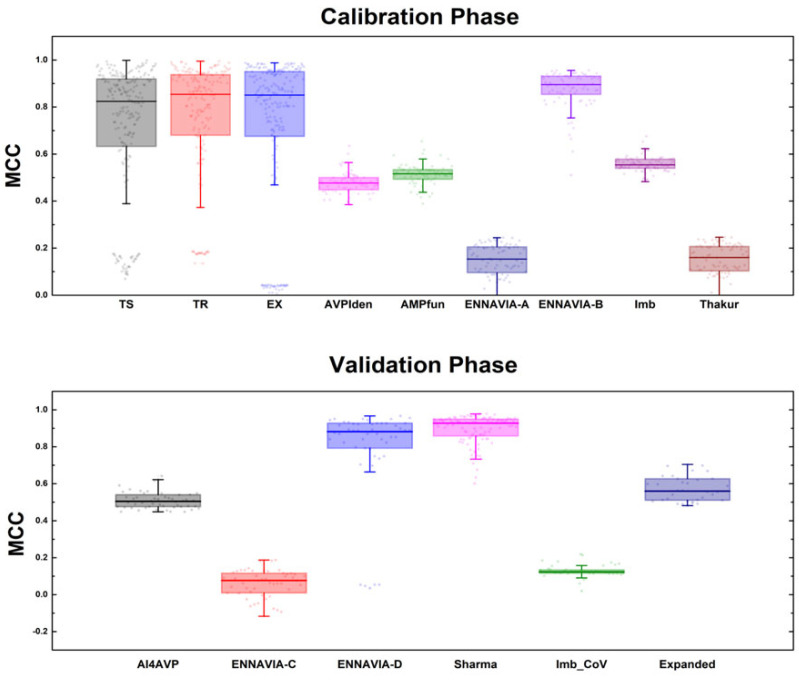
Antiviral peptides (AVPs) represent a promising strategy for addressing the global challenges of viral infections and their growing resistances to traditional drugs. Lab-based AVP discovery methods are resource-intensive, highlighting the need for efficient computational alternatives. In this study, we developed five non-trained but supervised multi-query similarity search models (MQSSMs) integrated into the StarPep toolbox. Rigorous testing and validation across diverse AVP datasets confirmed the models' robustness and reliability. The top-performing model, M13+, demonstrated impressive results, with an accuracy of 0.969 and a Matthew's correlation coefficient of 0.71. To assess their competitiveness, the top five models were benchmarked against 14 publicly available machine-learning and deep-learning AVP predictors. The MQSSMs outperformed these predictors, highlighting their efficiency in terms of resource demand and public accessibility. Another significant achievement of this study is the creation of the most comprehensive dataset of antiviral sequences to date. In general, these results suggest that MQSSMs are promissory tools to develop good alignment-based models that can be successfully applied in the screening of large datasets for new AVP discovery.
抗病毒肽(AVP)是应对病毒感染及其对传统药物日益增长的耐药性这一全球挑战的一种有前景的策略。基于实验室的AVP发现方法资源密集,凸显了对高效计算替代方法的需求。在本研究中,我们开发了五个集成到StarPep工具箱中的非训练但有监督的多查询相似性搜索模型(MQSSM)。在不同的AVP数据集上进行的严格测试和验证证实了这些模型的稳健性和可靠性。表现最佳的模型M13 +取得了令人印象深刻的结果,准确率为0.969,马修斯相关系数为0.71。为了评估它们的竞争力,将排名前五的模型与14个公开可用的机器学习和深度学习AVP预测器进行了基准测试。MQSSM优于这些预测器,凸显了它们在资源需求和公众可及性方面的效率。本研究的另一项重大成就是创建了迄今为止最全面的抗病毒序列数据集。总体而言,这些结果表明,MQSSM是开发基于良好比对的模型的有前途的工具,可成功应用于筛选大型数据集以发现新的AVP。