Ma Xueting, Ma Guorui, Liu Yang, Qi Shuhan
School of Computer Science and Technology, Harbin Institute of Technology, Shenzhen 518055, China.
Guangdong Provincial Key Laboratory of Novel Security Intelligence Technologies, Shenzhen 518055, China.
Entropy (Basel). 2024 Aug 21;26(8):712. doi: 10.3390/e26080712.
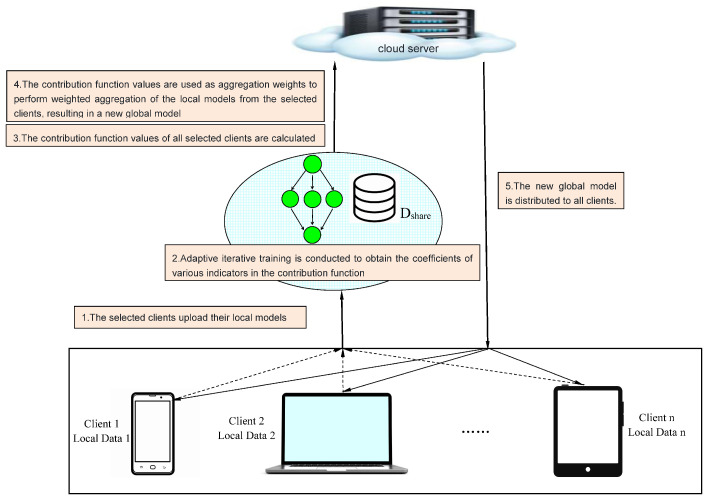
With the rapid advancement of the Internet and big data technologies, traditional centralized machine learning methods are challenged when dealing with large-scale datasets. Federated Learning (FL), as an emerging distributed machine learning paradigm, enables multiple clients to collaboratively train a global model while preserving privacy. Edge computing, also recognized as a critical technology for handling massive datasets, has garnered significant attention. However, the heterogeneity of clients in edge computing environments can severely impact the performance of the resultant models. This study introduces an Adaptive Personalized Client-Selection and Model-Aggregation Algorithm, , aimed at optimizing FL performance in edge computing settings. The algorithm evaluates clients' contributions by calculating the real-time performance of local models and the cosine similarity between local and global models, and it designs a function to quantify each client's contribution. The server then selects clients and assigns weights during model aggregation based on these contributions. Moreover, the algorithm accommodates personalized needs in local model updates, rather than simply overwriting with the global model. Extensive experiments were conducted on the and datasets, simulating three data distributions with parameters dir = 0.1, 0.3, and 0.5. The accuracy improvements achieved were 3.9%, 1.9%, and 1.1% for the dataset, and 31.9%, 8.4%, and 5.4% for the dataset, respectively.
随着互联网和大数据技术的快速发展,传统的集中式机器学习方法在处理大规模数据集时面临挑战。联邦学习(FL)作为一种新兴的分布式机器学习范式,使多个客户端能够在保护隐私的同时协作训练全局模型。边缘计算也被认为是处理海量数据集的关键技术,已引起广泛关注。然而,边缘计算环境中客户端的异质性会严重影响最终模型的性能。本研究提出了一种自适应个性化客户端选择和模型聚合算法,旨在优化边缘计算环境中的联邦学习性能。该算法通过计算局部模型的实时性能以及局部模型与全局模型之间的余弦相似度来评估客户端的贡献,并设计了一个函数来量化每个客户端的贡献。然后,服务器在模型聚合期间根据这些贡献选择客户端并分配权重。此外,该算法在局部模型更新中考虑了个性化需求,而不是简单地用全局模型覆盖。在 和 数据集上进行了广泛的实验,模拟了参数dir = 0.1、0.3和0.5的三种数据分布。对于 数据集,准确率提高分别为3.9%、1.9%和1.1%,对于 数据集,准确率提高分别为31.9%、8.4%和5.4%。