Laboratório de Medicina e Saúde Pública de Precisão (MeSP2), Instituto Gonçalo Moniz, Fundação Oswaldo Cruz, Salvador, Brazil.
Centro de Integração de Dados e Conhecimentos para a Saúde (CIDACS), Instituto Gonçalo Moniz, Fundação Oswaldo Cruz, Salvador, Brazil.
Cell Death Dis. 2024 Sep 13;15(9):671. doi: 10.1038/s41419-024-07043-4.
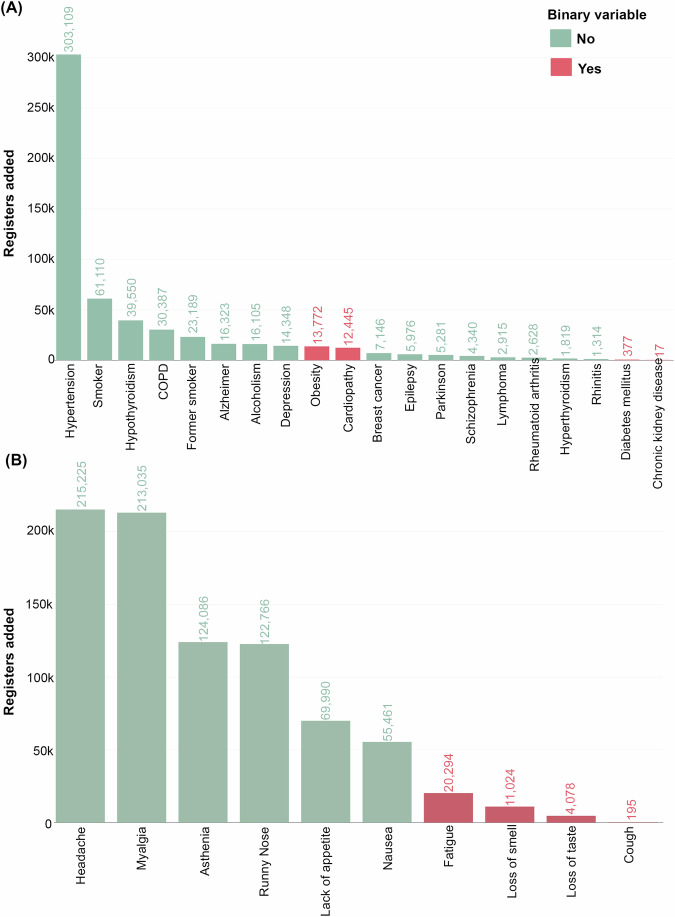
Long COVID is characterized by persistent that extends symptoms beyond established timeframes. Its varied presentation across different populations and healthcare systems poses significant challenges in understanding its clinical manifestations and implications. In this study, we present a novel application of text mining technique to automatically extract unstructured data from a long COVID survey conducted at a prominent university hospital in São Paulo, Brazil. Our phonetic text clustering (PTC) method enables the exploration of unstructured Electronic Healthcare Records (EHR) data to unify different written forms of similar terms into a single phonemic representation. We used n-gram text analysis to detect compound words and negated terms in Portuguese-BR, focusing on medical conditions and symptoms related to long COVID. By leveraging text mining, we aim to contribute to a deeper understanding of this chronic condition and its implications for healthcare systems globally. The model developed in this study has the potential for scalability and applicability in other healthcare settings, thereby supporting broader research efforts and informing clinical decision-making for long COVID patients.
长新冠的特点是持续存在的症状超出了既定的时间框架。它在不同人群和医疗保健系统中的不同表现形式给理解其临床表现和影响带来了重大挑战。在这项研究中,我们提出了一种文本挖掘技术的新应用,用于自动从巴西圣保罗一家著名大学医院进行的长新冠调查中提取非结构化数据。我们的语音文本聚类 (PTC) 方法能够探索非结构化的电子健康记录 (EHR) 数据,将相似术语的不同书写形式统一为单个语音表示。我们使用 n 元组文本分析来检测葡萄牙语-BR 中的复合词和否定词,重点是与长新冠相关的医疗状况和症状。通过利用文本挖掘,我们旨在深入了解这种慢性疾病及其对全球医疗保健系统的影响。本研究中开发的模型具有可扩展性和在其他医疗保健环境中的适用性,从而支持更广泛的研究工作,并为长新冠患者的临床决策提供信息。