Wiest Isabella Catharina, Wolf Fabian, Leßmann Marie-Elisabeth, van Treeck Marko, Ferber Dyke, Zhu Jiefu, Boehme Heiko, Bressem Keno K, Ulrich Hannes, Ebert Matthias P, Kather Jakob Nikolas
Department of Medicine II, Medical Faculty Mannheim, Heidelberg University, Mannheim, Germany.
Else Kroener Fresenius Center for Digital Health, Faculty of Medicine and University Hospital Carl Gustav Carus, TUD Dresden University of Technology, 01307 Dresden, Germany.
medRxiv. 2024 Sep 3:2024.09.02.24312917. doi: 10.1101/2024.09.02.24312917.
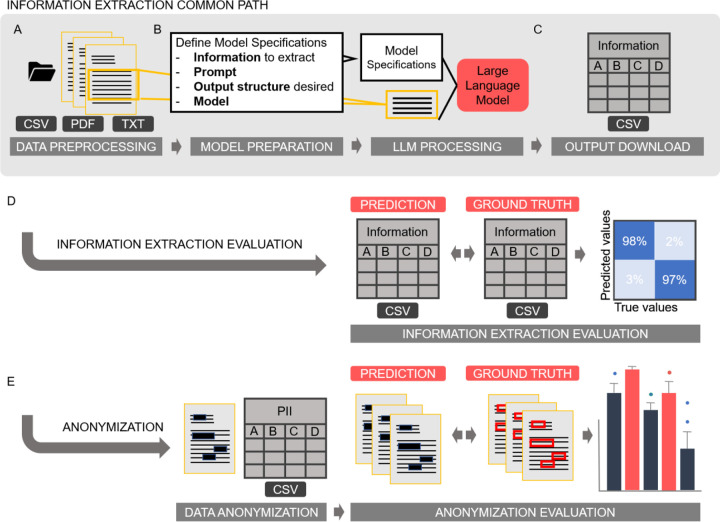
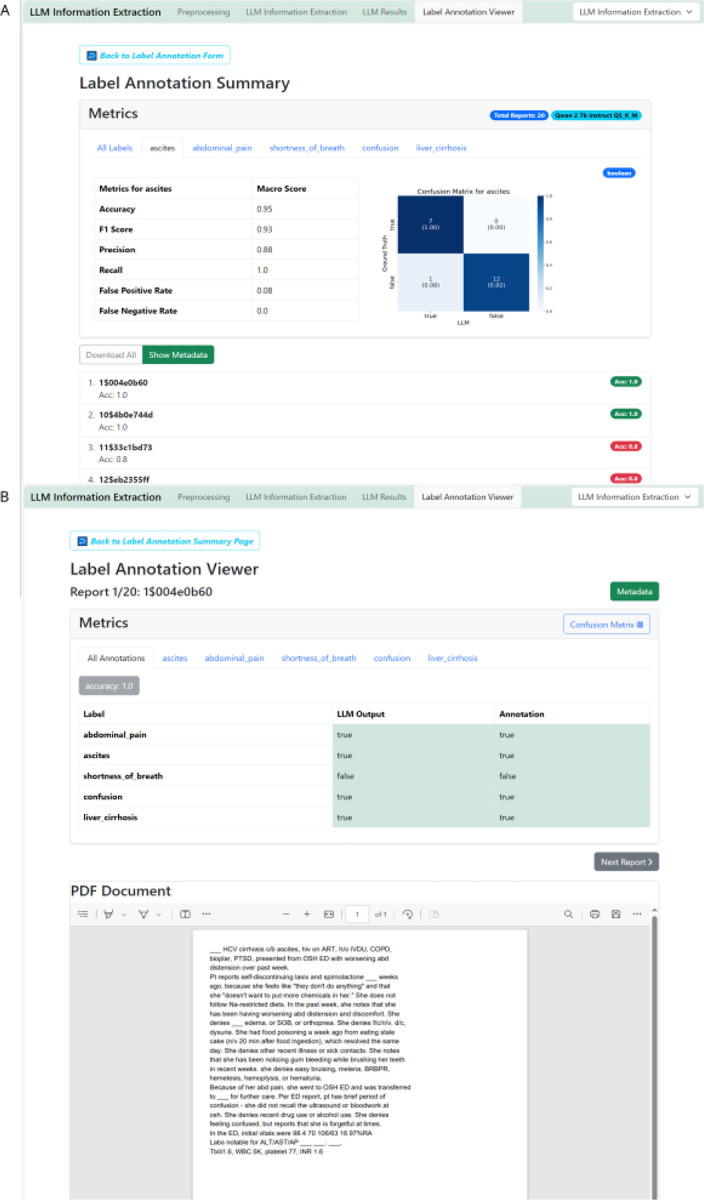
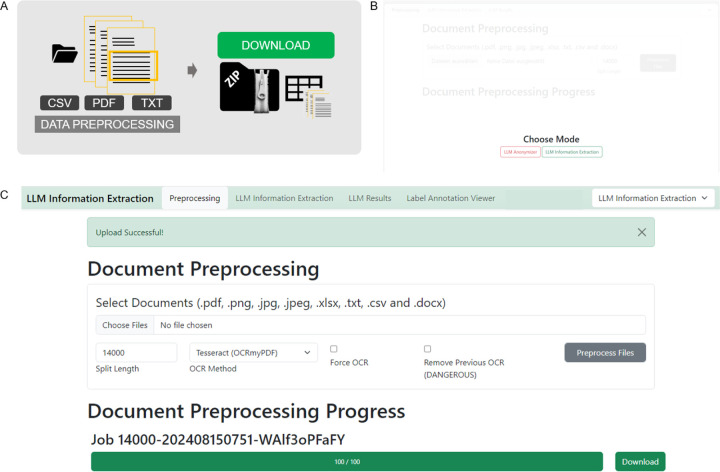
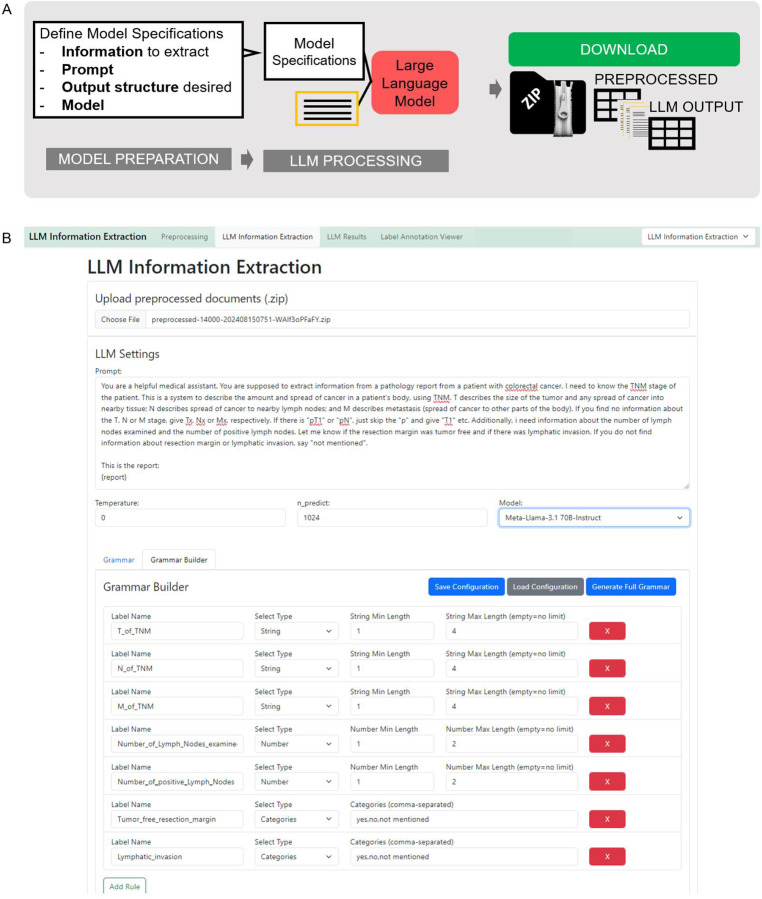
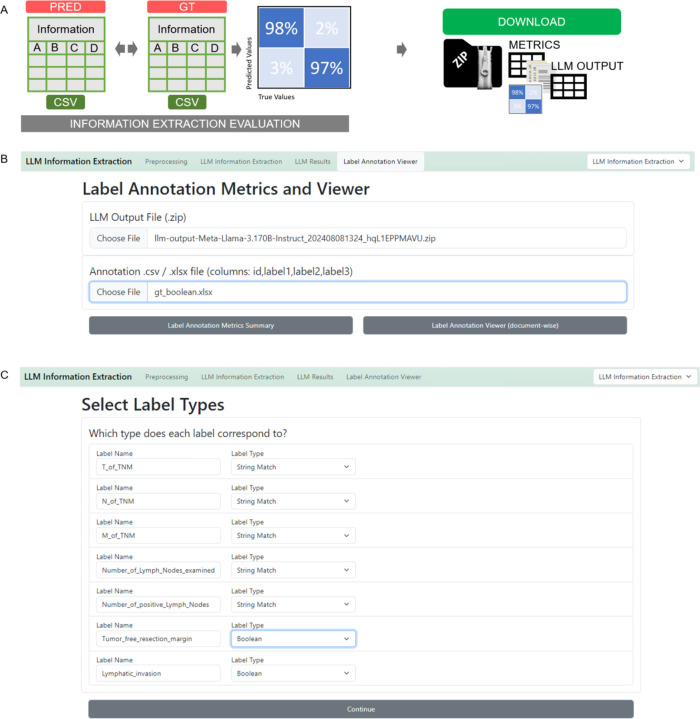
In clinical science and practice, text data, such as clinical letters or procedure reports, is stored in an unstructured way. This type of data is not a quantifiable resource for any kind of quantitative investigations and any manual review or structured information retrieval is time-consuming and costly. The capabilities of Large Language Models (LLMs) mark a paradigm shift in natural language processing and offer new possibilities for structured Information Extraction (IE) from medical free text. This protocol describes a workflow for LLM based information extraction (LLM-AIx), enabling extraction of predefined entities from unstructured text using privacy preserving LLMs. By converting unstructured clinical text into structured data, LLM-AIx addresses a critical barrier in clinical research and practice, where the efficient extraction of information is essential for improving clinical decision-making, enhancing patient outcomes, and facilitating large-scale data analysis. The protocol consists of four main processing steps: 1) Problem definition and data preparation, 2) data preprocessing, 3) LLM-based IE and 4) output evaluation. LLM-AIx allows integration on local hospital hardware without the need of transferring any patient data to external servers. As example tasks, we applied LLM-AIx for the anonymization of fictitious clinical letters from patients with pulmonary embolism. Additionally, we extracted symptoms and laterality of the pulmonary embolism of these fictitious letters. We demonstrate troubleshooting for potential problems within the pipeline with an IE on a real-world dataset, 100 pathology reports from the Cancer Genome Atlas Program (TCGA), for TNM stage extraction. LLM-AIx can be executed without any programming knowledge via an easy-to-use interface and in no more than a few minutes or hours, depending on the LLM model selected.
在临床科学与实践中,诸如临床信函或诊疗报告等文本数据以非结构化方式存储。这类数据并非用于任何定量研究的可量化资源,任何人工审阅或结构化信息检索都既耗时又昂贵。大语言模型(LLMs)的能力标志着自然语言处理的范式转变,并为从医学自由文本中进行结构化信息提取(IE)提供了新的可能性。本方案描述了一种基于大语言模型的信息提取工作流程(LLM - AIx),它能够使用隐私保护大语言模型从未结构化文本中提取预定义实体。通过将非结构化临床文本转换为结构化数据,LLM - AIx解决了临床研究与实践中的一个关键障碍,即高效提取信息对于改善临床决策、提升患者治疗效果以及促进大规模数据分析至关重要。该方案包括四个主要处理步骤:1)问题定义与数据准备,2)数据预处理,3)基于大语言模型的信息提取,以及4)输出评估。LLM - AIx允许在本地医院硬件上进行集成,无需将任何患者数据传输到外部服务器。作为示例任务,我们将LLM - AIx应用于对肺栓塞患者虚构临床信函进行匿名化处理。此外,我们提取了这些虚构信函中肺栓塞的症状和部位。我们通过对来自癌症基因组图谱计划(TCGA)的100份病理报告这一真实世界数据集进行信息提取,展示了对流程中潜在问题的故障排除,以提取TNM分期。LLM - AIx可以通过易于使用的界面在无需任何编程知识的情况下执行,根据所选的大语言模型,执行时间不超过几分钟或几小时。