Vassis Stratos, Powell Harriet, Petersen Emma, Barkmann Asta, Noeldeke Beatrice, Kristensen Kasper D, Stoustrup Peter
Section of Orthodontics, Department of Dentistry and Oral Health, Aarhus University, Aarhus, DNK.
Section of Orthodontics, Department of Dentistry and Oral Health, Aarhus Universiy, Aarhus, DNK.
Cureus. 2024 Aug 29;16(8):e68085. doi: 10.7759/cureus.68085. eCollection 2024 Aug.
Patients seeking orthodontic treatment may use large language models (LLMs) such as Chat-GPT for self-education, thereby impacting their decision-making process. This study assesses the reliability and validity of Chat-GPT prompts aimed at informing patients about orthodontic side effects and examines patients' perceptions of this information.
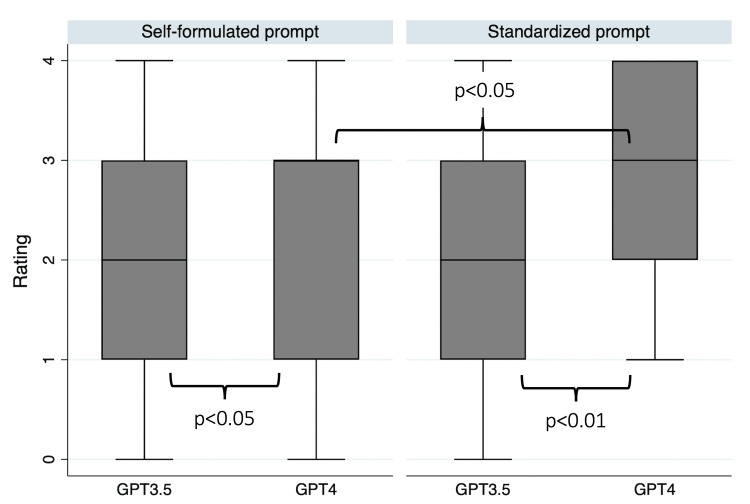
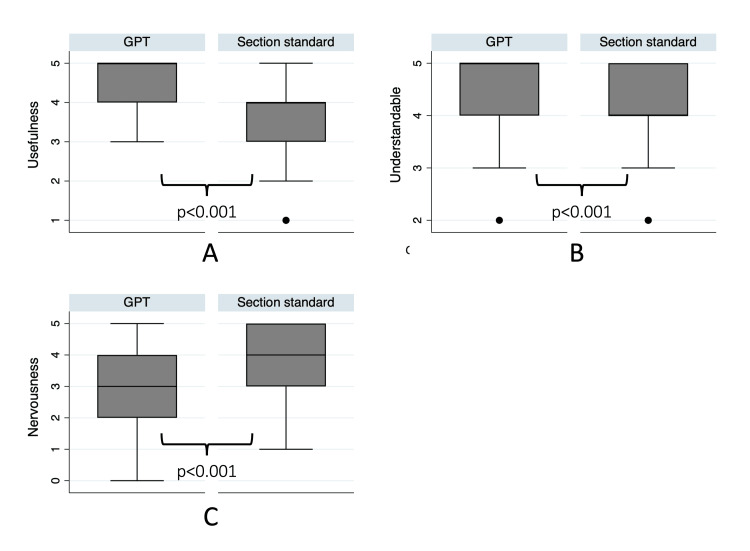
To assess reliability, n = 28 individuals were asked to generate information from GPT-3.5 and Generative Pretrained Transformer 4 (GPT-4) about side effects related to orthodontic treatment using both self-formulated and standardized prompts. Three experts evaluated the content generated based on these prompts regarding its validity. We asked a cohort of 46 orthodontic patients about their perceptions after reading an AI-generated information text about orthodontic side effects and compared it with the standard text from the postgraduate orthodontic program at Aarhus University.
Although the GPT-generated answers mentioned several relevant side effects, the replies were diverse. The experts rated the AI-generated content generally as "neither deficient nor satisfactory," with GPT-4 achieving higher scores than GPT-3.5. The patients perceived the GPT-generated information as more useful and more comprehensive and experienced less nervousness when reading the GPT-generated information. Nearly 80% of patients preferred the AI-generated information over the standard text.
Although patients generally prefer AI-generated information regarding the side effects of orthodontic treatment, the tested prompts fall short of providing thoroughly satisfactory and high-quality education to patients.
寻求正畸治疗的患者可能会使用Chat-GPT等大语言模型进行自我教育,从而影响他们的决策过程。本研究评估了旨在告知患者正畸副作用的Chat-GPT提示的可靠性和有效性,并考察了患者对这些信息的看法。
为评估可靠性,28名个体被要求使用自行制定和标准化的提示,从GPT-3.5和生成式预训练变换器4(GPT-4)生成有关正畸治疗相关副作用的信息。三位专家根据这些提示对生成的内容进行有效性评估。我们询问了46名正畸患者在阅读关于正畸副作用的人工智能生成的信息文本后的看法,并将其与奥胡斯大学正畸研究生课程的标准文本进行比较。
尽管GPT生成的答案提到了几种相关副作用,但回答各不相同。专家们普遍将人工智能生成的内容评为“既不欠缺也不令人满意”,GPT-4的得分高于GPT-3.5。患者认为GPT生成的信息更有用、更全面,并且在阅读GPT生成的信息时紧张感更低。近80%的患者更喜欢人工智能生成的信息而不是标准文本。
尽管患者总体上更喜欢关于正畸治疗副作用的人工智能生成的信息,但所测试的提示未能为患者提供完全令人满意和高质量的教育。