School of Dentistry, European University Cyprus, Nicosia, Cyprus.
Information Management Systems Institute, ATHENA Research and Innovation Center, Athens, Greece.
J Med Internet Res. 2023 Dec 28;25:e51580. doi: 10.2196/51580.
The increasing application of generative artificial intelligence large language models (LLMs) in various fields, including dentistry, raises questions about their accuracy.
This study aims to comparatively evaluate the answers provided by 4 LLMs, namely Bard (Google LLC), ChatGPT-3.5 and ChatGPT-4 (OpenAI), and Bing Chat (Microsoft Corp), to clinically relevant questions from the field of dentistry.
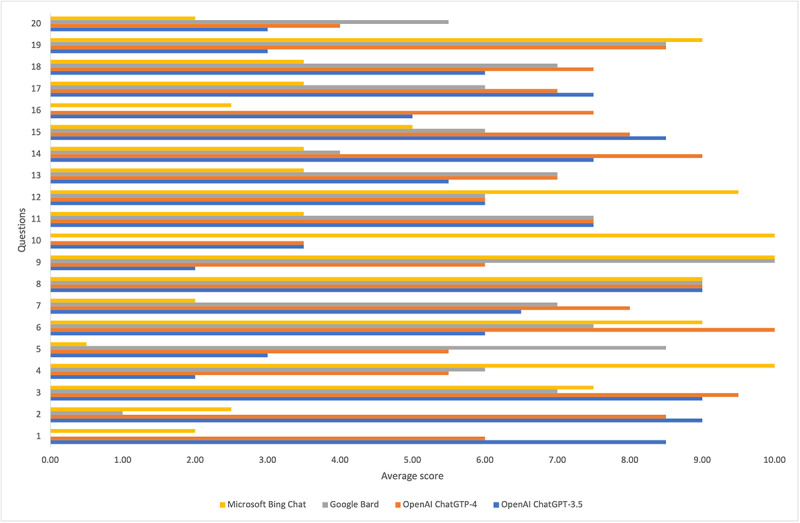
The LLMs were queried with 20 open-type, clinical dentistry-related questions from different disciplines, developed by the respective faculty of the School of Dentistry, European University Cyprus. The LLMs' answers were graded 0 (minimum) to 10 (maximum) points against strong, traditionally collected scientific evidence, such as guidelines and consensus statements, using a rubric, as if they were examination questions posed to students, by 2 experienced faculty members. The scores were statistically compared to identify the best-performing model using the Friedman and Wilcoxon tests. Moreover, the evaluators were asked to provide a qualitative evaluation of the comprehensiveness, scientific accuracy, clarity, and relevance of the LLMs' answers.
Overall, no statistically significant difference was detected between the scores given by the 2 evaluators; therefore, an average score was computed for every LLM. Although ChatGPT-4 statistically outperformed ChatGPT-3.5 (P=.008), Bing Chat (P=.049), and Bard (P=.045), all models occasionally exhibited inaccuracies, generality, outdated content, and a lack of source references. The evaluators noted instances where the LLMs delivered irrelevant information, vague answers, or information that was not fully accurate.
This study demonstrates that although LLMs hold promising potential as an aid in the implementation of evidence-based dentistry, their current limitations can lead to potentially harmful health care decisions if not used judiciously. Therefore, these tools should not replace the dentist's critical thinking and in-depth understanding of the subject matter. Further research, clinical validation, and model improvements are necessary for these tools to be fully integrated into dental practice. Dental practitioners must be aware of the limitations of LLMs, as their imprudent use could potentially impact patient care. Regulatory measures should be established to oversee the use of these evolving technologies.
生成式人工智能大型语言模型(LLM)在包括牙科在内的各个领域的应用日益广泛,这引发了人们对其准确性的质疑。
本研究旨在比较评估 4 种 LLM,即 Bard(Google LLC)、ChatGPT-3.5 和 ChatGPT-4(OpenAI)以及 Bing Chat(Microsoft Corp),对来自牙科领域的临床相关问题的回答。
由塞浦路斯欧洲大学牙科学院的教师分别开发了 20 个开放式、临床牙科相关问题,对 4 种 LLM 进行查询。使用评分表(如果这些问题是向学生提出的考试问题),由 2 名经验丰富的教师根据强有力的传统收集的科学证据(如指南和共识声明)对 LLM 的回答进行 0(最低)到 10(最高)分的评分。使用 Friedman 和 Wilcoxon 检验对评分进行统计学比较,以确定表现最佳的模型。此外,评估者被要求对 LLM 回答的全面性、科学准确性、清晰度和相关性进行定性评估。
总体而言,2 名评估者给出的评分之间没有统计学上的显著差异;因此,为每个 LLM 计算了平均评分。尽管 ChatGPT-4 在统计学上优于 ChatGPT-3.5(P=.008)、Bing Chat(P=.049)和 Bard(P=.045),但所有模型偶尔都存在不准确、笼统、过时的内容和缺乏来源参考的情况。评估者注意到 LLM 提供不相关信息、模糊答案或不完全准确的信息的情况。
本研究表明,尽管 LLM 作为实施循证牙科的辅助工具具有很大的潜力,但如果使用不当,它们当前的局限性可能会导致潜在的有害医疗保健决策。因此,这些工具不应替代牙医对主题的批判性思维和深入理解。为了使这些工具完全融入牙科实践,需要进行进一步的研究、临床验证和模型改进。牙科从业者必须意识到 LLM 的局限性,因为它们的不当使用可能会对患者护理产生影响。应建立监管措施来监督这些不断发展的技术的使用。