Zhang Gongbo, Jin Qiao, Zhou Yiliang, Wang Song, Idnay Betina R, Luo Yiming, Park Elizabeth, Nestor Jordan G, Spotnitz Matthew E, Soroush Ali, Campion Thomas, Lu Zhiyong, Weng Chunhua, Peng Yifan
Department of Biomedical Informatics, Columbia University, New York, NY, USA.
National Center for Biotechnology Information, National Library of Medicine, National Institutes of Health, Bethesda, MD, USA.
ArXiv. 2024 Jul 25:arXiv:2408.00588v1.
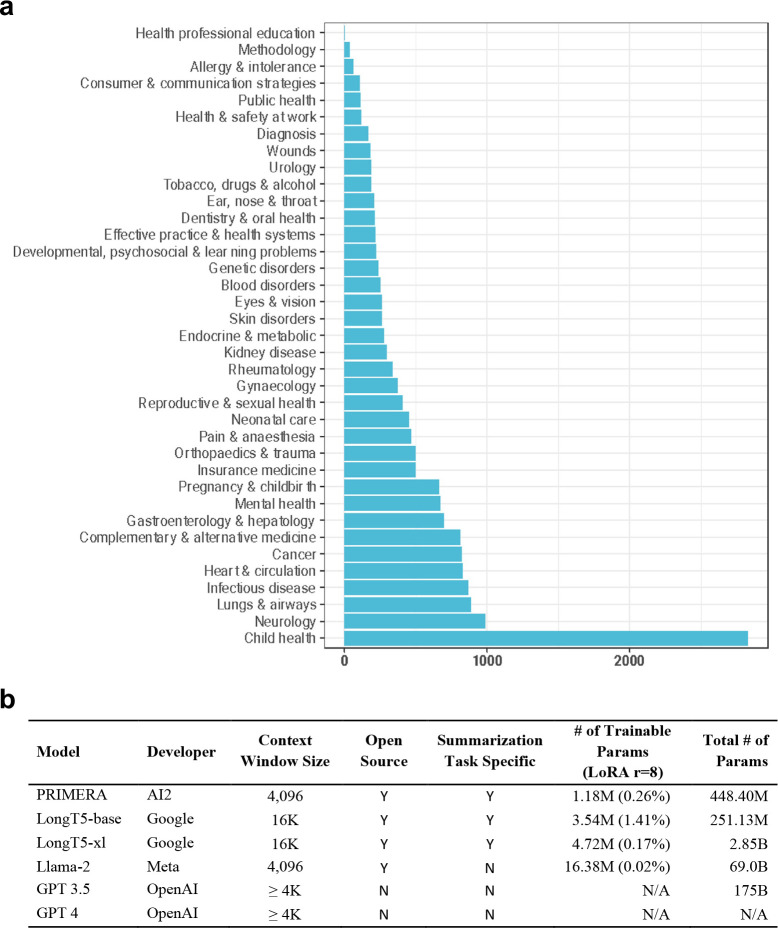
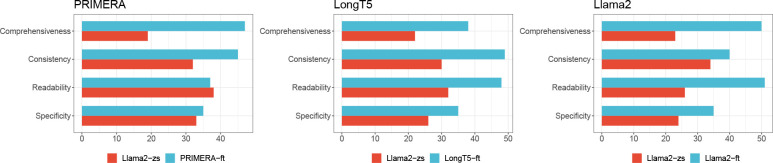
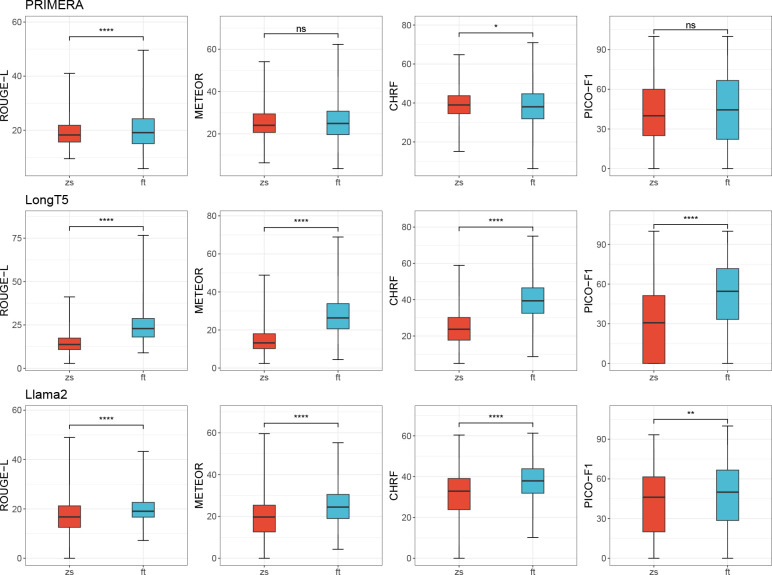
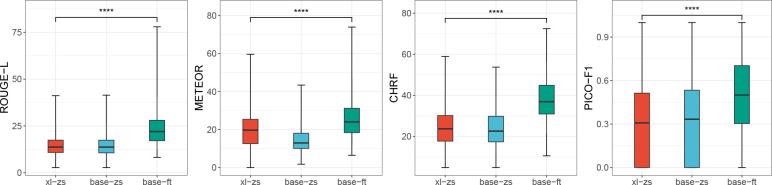
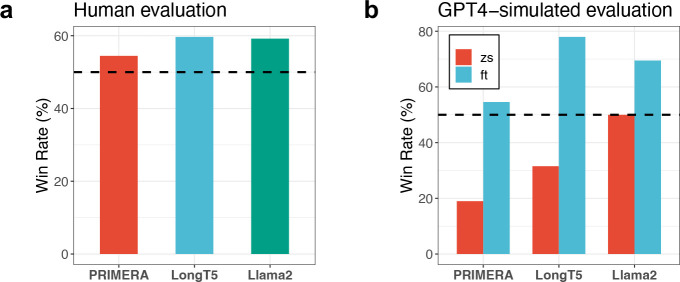
Large language models (LLMs) hold great promise in summarizing medical evidence. Most recent studies focus on the application of proprietary LLMs. Using proprietary LLMs introduces multiple risk factors, including a lack of transparency and vendor dependency. While open-source LLMs allow better transparency and customization, their performance falls short compared to proprietary ones. In this study, we investigated to what extent fine-tuning open-source LLMs can further improve their performance in summarizing medical evidence. Utilizing a benchmark dataset, MedReview, consisting of 8,161 pairs of systematic reviews and summaries, we fine-tuned three broadly-used, open-sourced LLMs, namely PRIMERA, LongT5, and Llama-2. Overall, the fine-tuned LLMs obtained an increase of 9.89 in ROUGE-L (95% confidence interval: 8.94-10.81), 13.21 in METEOR score (95% confidence interval: 12.05-14.37), and 15.82 in CHRF score (95% confidence interval: 13.89-16.44). The performance of fine-tuned LongT5 is close to GPT-3.5 with zero-shot settings. Furthermore, smaller fine-tuned models sometimes even demonstrated superior performance compared to larger zero-shot models. The above trends of improvement were also manifested in both human and GPT4-simulated evaluations. Our results can be applied to guide model selection for tasks demanding particular domain knowledge, such as medical evidence summarization.
大语言模型(LLMs)在总结医学证据方面具有巨大潜力。最近的研究大多集中在专有大语言模型的应用上。使用专有大语言模型会引入多种风险因素,包括缺乏透明度和对供应商的依赖。虽然开源大语言模型具有更高的透明度和可定制性,但其性能与专有模型相比仍有差距。在本研究中,我们调查了对开源大语言模型进行微调在多大程度上可以进一步提高其在总结医学证据方面的性能。我们利用一个基准数据集MedReview,该数据集由8161对系统评价和总结组成,对三个广泛使用的开源大语言模型PRIMERA、LongT5和Llama-2进行了微调。总体而言,微调后的大语言模型在ROUGE-L指标上提高了9.89(95%置信区间:8.94 - 10.81),在METEOR分数上提高了13.21(95%置信区间:12.05 - 14.37),在CHRF分数上提高了15.82(95%置信区间:13.89 - 16.44)。微调后的LongT5在零样本设置下的性能接近GPT-3.5。此外,有时较小的微调模型甚至比更大的零样本模型表现更优。上述改进趋势在人工评估和GPT4模拟评估中均有体现。我们的结果可用于指导针对需要特定领域知识的任务(如医学证据总结)进行模型选择。