Interdisciplinary Program for Bioengineering, Seoul National University, Seoul, Republic of Korea.
Seoul National University Medical Research Center, Seoul, Republic of Korea.
JMIR Med Inform. 2024 Oct 30;12:e52897. doi: 10.2196/52897.
The bidirectional encoder representations from transformers (BERT) model has attracted considerable attention in clinical applications, such as patient classification and disease prediction. However, current studies have typically progressed to application development without a thorough assessment of the model's comprehension of clinical context. Furthermore, limited comparative studies have been conducted on BERT models using medical documents from non-English-speaking countries. Therefore, the applicability of BERT models trained on English clinical notes to non-English contexts is yet to be confirmed. To address these gaps in literature, this study focused on identifying the most effective BERT model for non-English clinical notes.
In this study, we evaluated the contextual understanding abilities of various BERT models applied to mixed Korean and English clinical notes. The objective of this study was to identify the BERT model that excels in understanding the context of such documents.
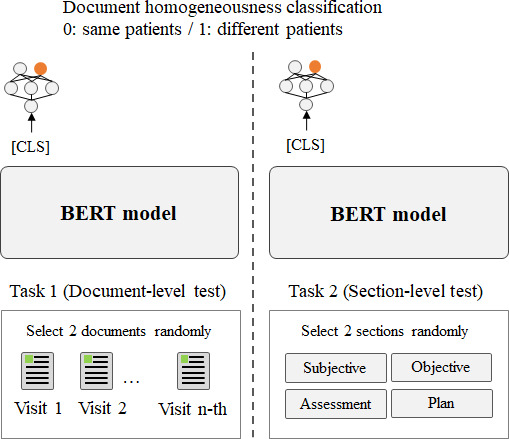
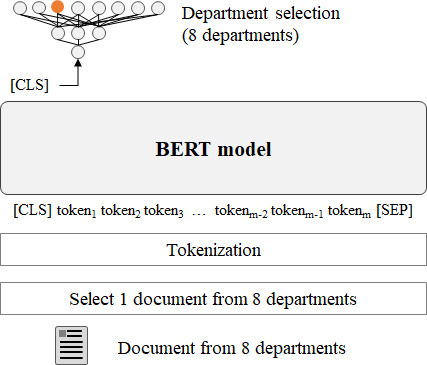
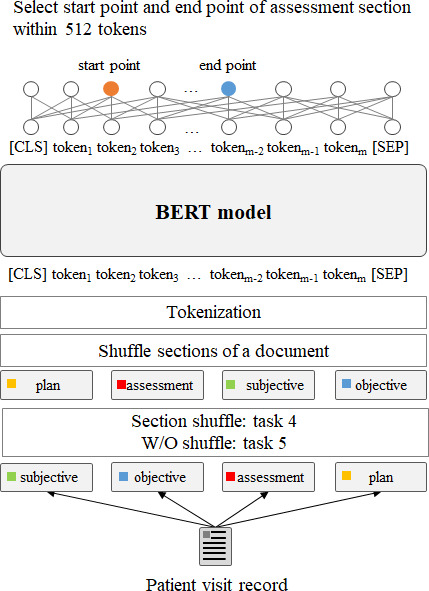
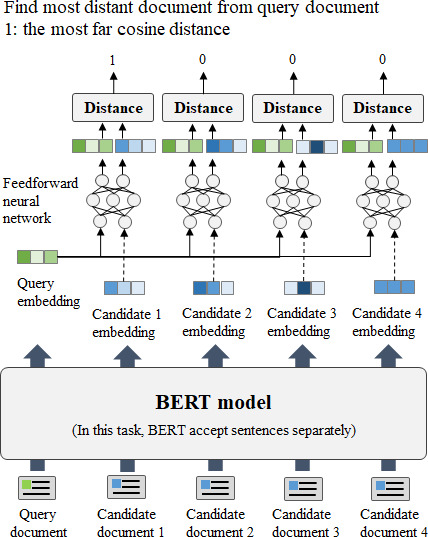
Using data from 164,460 patients in a South Korean tertiary hospital, we pretrained BERT-base, BERT for Biomedical Text Mining (BioBERT), Korean BERT (KoBERT), and Multilingual BERT (M-BERT) to improve their contextual comprehension capabilities and subsequently compared their performances in 7 fine-tuning tasks.
The model performance varied based on the task and token usage. First, BERT-base and BioBERT excelled in tasks using classification ([CLS]) token embeddings, such as document classification. BioBERT achieved the highest F1-score of 89.32. Both BERT-base and BioBERT demonstrated their effectiveness in document pattern recognition, even with limited Korean tokens in the dictionary. Second, M-BERT exhibited a superior performance in reading comprehension tasks, achieving an F1-score of 93.77. Better results were obtained when fewer words were replaced with unknown ([UNK]) tokens. Third, M-BERT excelled in the knowledge inference task in which correct disease names were inferred from 63 candidate disease names in a document with disease names replaced with [MASK] tokens. M-BERT achieved the highest hit@10 score of 95.41.
This study highlighted the effectiveness of various BERT models in a multilingual clinical domain. The findings can be used as a reference in clinical and language-based applications.
基于转换器的双向编码器表示(BERT)模型在临床应用中引起了广泛关注,例如患者分类和疾病预测。然而,目前的研究通常在没有彻底评估模型对临床环境的理解能力的情况下就进行应用开发。此外,针对使用非英语国家的医学文献的 BERT 模型的比较研究也很有限。因此,在英语临床记录上训练的 BERT 模型在非英语环境下的适用性仍有待确认。为了解决文献中的这些差距,本研究专注于确定最适合非英语临床记录的 BERT 模型。
在这项研究中,我们评估了应用于混合韩语和英语临床记录的各种 BERT 模型的上下文理解能力。本研究的目的是确定在理解此类文档方面表现出色的 BERT 模型。
使用来自韩国一家三级医院的 164460 名患者的数据,我们对 BERT-base、生物医学文本挖掘用 BERT(BioBERT)、韩语 BERT(KoBERT)和多语言 BERT(M-BERT)进行了预训练,以提高它们的上下文理解能力,然后比较了它们在 7 个微调任务中的表现。
模型性能因任务和标记使用情况而异。首先,BERT-base 和 BioBERT 在使用分类([CLS])标记嵌入的任务中表现出色,例如文档分类。BioBERT 获得了 89.32 的最高 F1 分数。BERT-base 和 BioBERT 都在文档模式识别方面表现出色,即使字典中韩语标记有限。其次,M-BERT 在阅读理解任务中的表现优于其他模型,其 F1 分数为 93.77。当用未知([UNK])标记替换的单词较少时,结果会更好。第三,M-BERT 在知识推理任务中表现出色,该任务根据文档中用 [MASK] 标记替换的疾病名称,从 63 个候选疾病名称中推断出正确的疾病名称。M-BERT 获得了 95.41 的最高命中@10 分数。
本研究强调了各种 BERT 模型在多语言临床领域的有效性。这些发现可作为临床和基于语言的应用的参考。