School of Information Science and Engineering, University of Jinan, Jinan, China.
Laboratory of Zoology, Graduate School of Bioresource and Bioenvironmental Sciences, Kyushu University, Fukuoka-shi, Fukuoka, Japan.
BMC Genomics. 2024 Oct 30;25(1):1019. doi: 10.1186/s12864-024-10954-3.
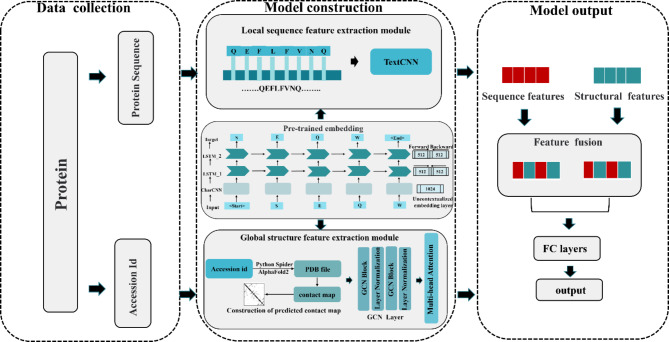
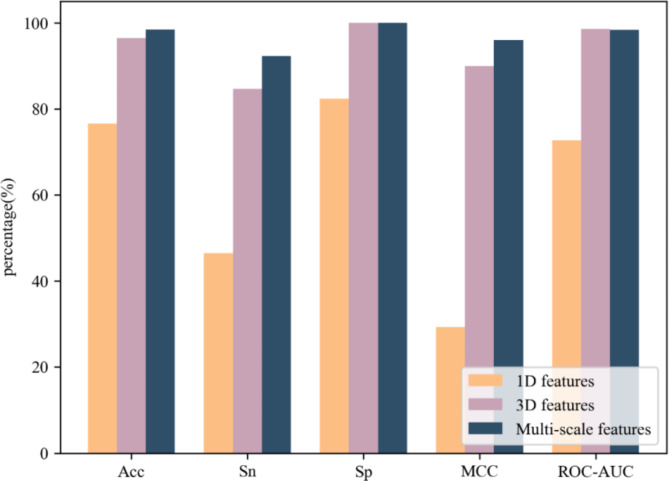
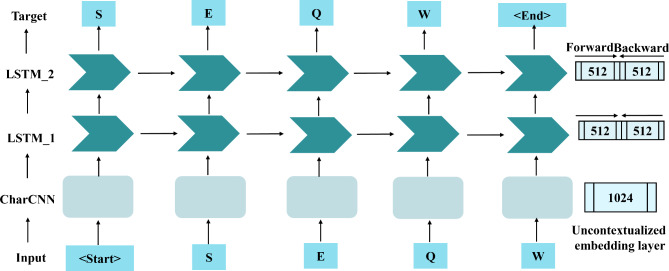
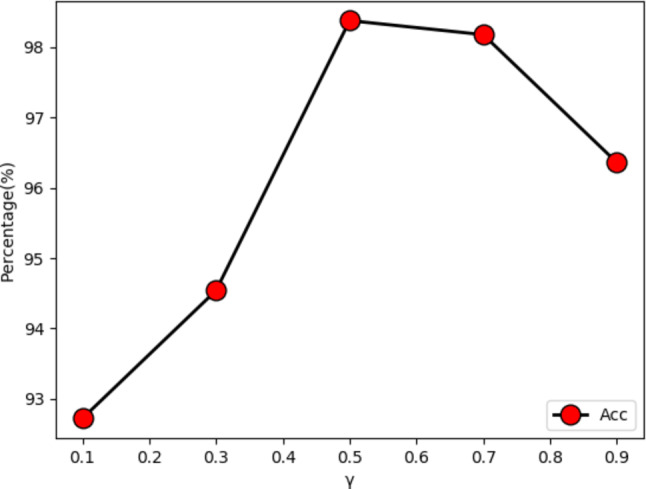
The Golgi apparatus is a crucial component of the inner membrane system in eukaryotic cells, playing a central role in protein biosynthesis. Dysfunction of the Golgi apparatus has been linked to neurodegenerative diseases. Accurate identification of sub-Golgi protein types is therefore essential for developing effective treatments for such diseases. Due to the expensive and time-consuming nature of experimental methods for identifying sub-Golgi protein types, various computational methods have been developed as identification tools. However, the majority of these methods rely solely on neighboring features in the protein sequence and neglect the crucial spatial structure information of the protein.To discover alternative methods for accurately identifying sub-Golgi proteins, we have developed a model called GASIDN. The GASIDN model extracts multi-dimension features by utilizing a 1D convolution module on protein sequences and a graph learning module on contact maps constructed from AlphaFold2.The model utilizes the deep representation learning model SeqVec to initialize protein sequences. GASIDN achieved accuracy values of 98.4% and 96.4% in independent testing and ten-fold cross-validation, respectively, outperforming the majority of previous predictors. To the best of our knowledge, this is the first method that utilizes multi-scale feature fusion to identify and locate sub-Golgi proteins. In order to assess the generalizability and scalability of our model, we conducted experiments to apply it in the identification of proteins from other organelles, including plant vacuoles and peroxisomes. The results obtained from these experiments demonstrated promising outcomes, indicating the effectiveness and versatility of our model. The source code and datasets can be accessed at https://github.com/SJNNNN/GASIDN .
高尔基体是真核细胞内膜系统的关键组成部分,在蛋白质生物合成中发挥核心作用。高尔基体功能障碍与神经退行性疾病有关。因此,准确识别亚高尔基体蛋白类型对于开发此类疾病的有效治疗方法至关重要。由于鉴定亚高尔基体蛋白类型的实验方法昂贵且耗时,因此开发了各种计算方法作为鉴定工具。然而,这些方法中的大多数仅依赖于蛋白质序列中的相邻特征,而忽略了蛋白质关键的空间结构信息。为了发现准确识别亚高尔基体蛋白的替代方法,我们开发了一种名为 GASIDN 的模型。GASIDN 模型通过在蛋白质序列上使用 1D 卷积模块和在由 AlphaFold2 构建的接触图上使用图学习模块来提取多维特征。该模型利用深度表示学习模型 SeqVec 初始化蛋白质序列。GASIDN 在独立测试和十折交叉验证中的准确率分别达到 98.4%和 96.4%,优于大多数先前的预测器。据我们所知,这是第一个利用多尺度特征融合来识别和定位亚高尔基体蛋白的方法。为了评估我们模型的泛化能力和可扩展性,我们进行了实验以将其应用于鉴定来自其他细胞器的蛋白质,包括植物液泡和过氧化物酶体。这些实验的结果表明了我们模型的有效性和多功能性。源代码和数据集可在 https://github.com/SJNNNN/GASIDN 上获取。