School of Biology & Engineering, Guizhou Medical University, Guiyang, Guizhou 550004, P.R. China.
College of Computer Science and Technology, and Key Laboratory of Symbolic Computation and Knowledge Engineering of Ministry of Education, Jilin University, Changchun, Jilin 130012, P.R. China.
Brief Bioinform. 2022 Sep 20;23(5). doi: 10.1093/bib/bbac173.
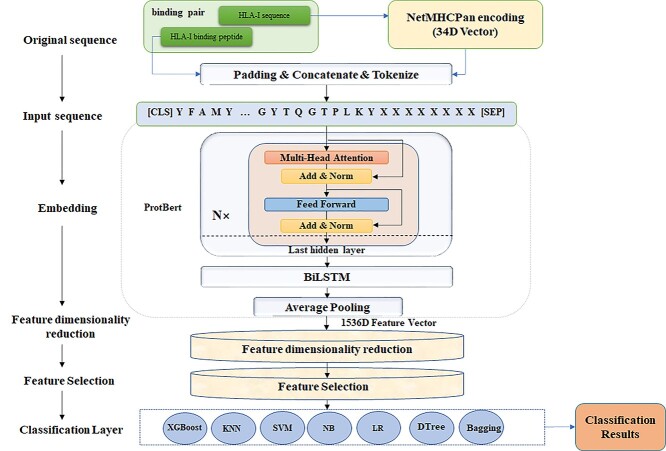
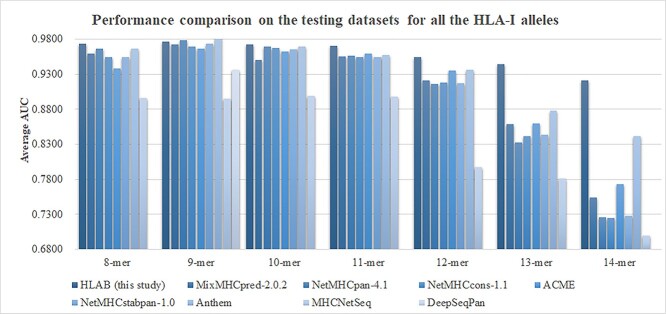
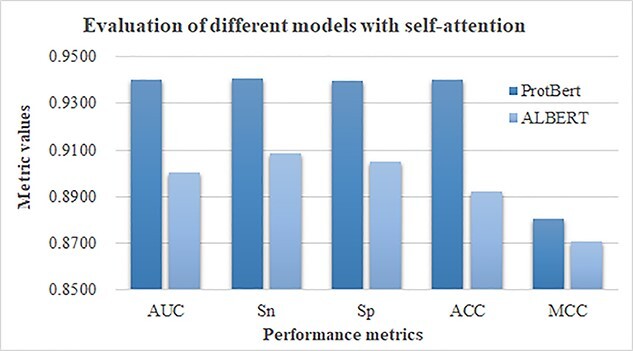
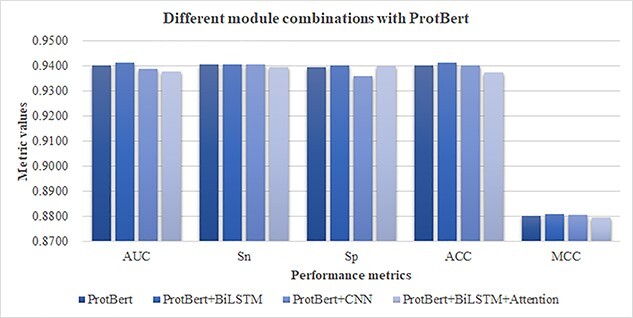
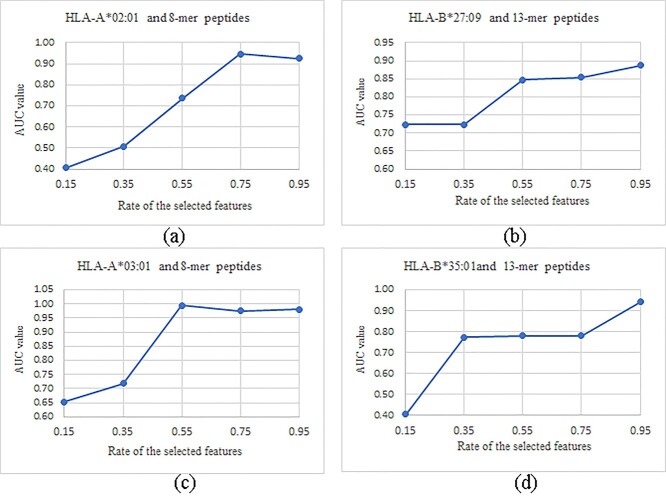
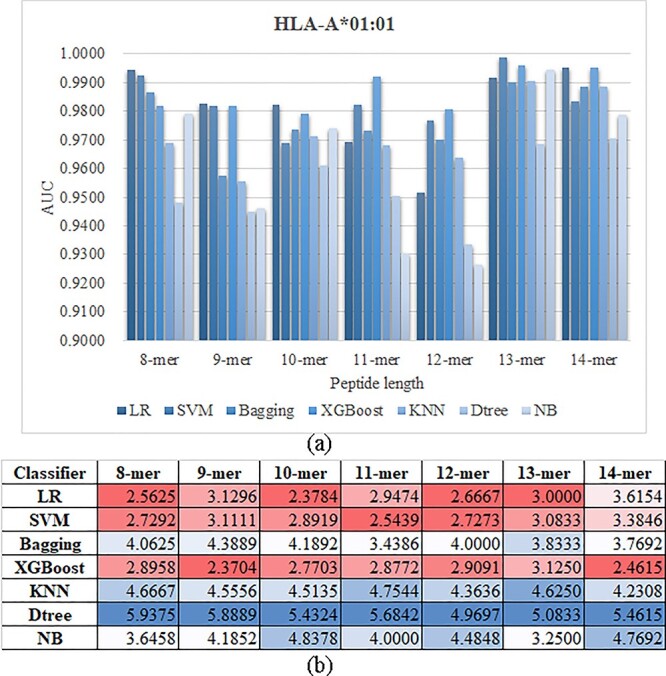
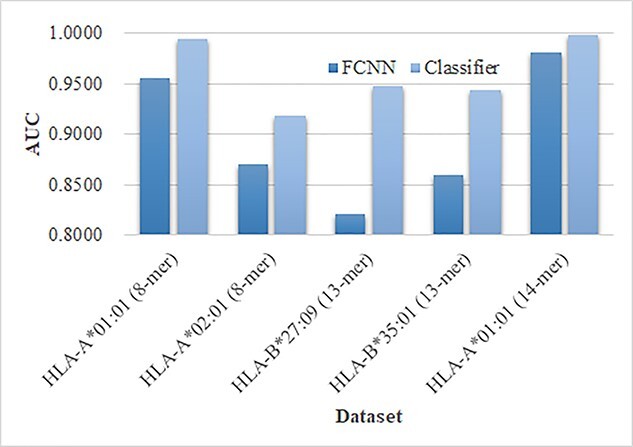
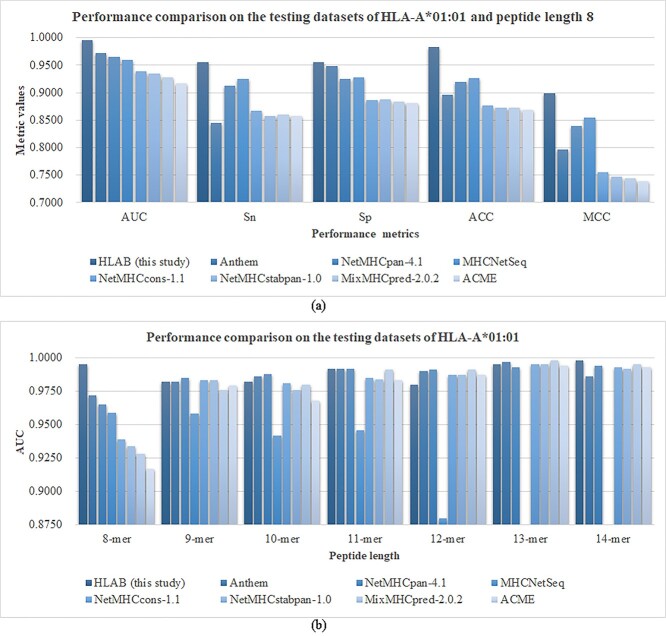
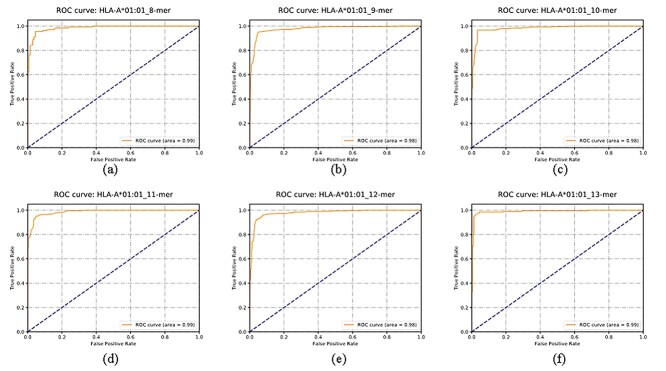
Human Leukocyte Antigen (HLA) is a type of molecule residing on the surfaces of most human cells and exerts an essential role in the immune system responding to the invasive items. The T cell antigen receptors may recognize the HLA-peptide complexes on the surfaces of cancer cells and destroy these cancer cells through toxic T lymphocytes. The computational determination of HLA-binding peptides will facilitate the rapid development of cancer immunotherapies. This study hypothesized that the natural language processing-encoded peptide features may be further enriched by another deep neural network. The hypothesis was tested with the Bi-directional Long Short-Term Memory-extracted features from the pretrained Protein Bidirectional Encoder Representations from Transformers-encoded features of the class I HLA (HLA-I)-binding peptides. The experimental data showed that our proposed HLAB feature engineering algorithm outperformed the existing ones in detecting the HLA-I-binding peptides. The extensive evaluation data show that the proposed HLAB algorithm outperforms all the seven existing studies on predicting the peptides binding to the HLA-A*01:01 allele in AUC and achieves the best average AUC values on the six out of the seven k-mers (k=8,9,...,14, respectively represent the prediction task of a polypeptide consisting of k amino acids) except for the 9-mer prediction tasks. The source code and the fine-tuned feature extraction models are available at http://www.healthinformaticslab.org/supp/resources.php.
人类白细胞抗原 (HLA) 是一种存在于大多数人体细胞表面的分子,在免疫系统对入侵物的反应中发挥着重要作用。T 细胞抗原受体可以识别癌细胞表面的 HLA-肽复合物,并通过毒性 T 淋巴细胞破坏这些癌细胞。HLA 结合肽的计算确定将促进癌症免疫疗法的快速发展。本研究假设,自然语言处理编码的肽特征可以通过另一个深度神经网络进一步丰富。该假设通过使用双向长短期记忆提取的特征和预训练的蛋白质双向编码器表示从变压器编码的 HLA(HLA-I)结合肽的特征进行了测试。实验数据表明,我们提出的 HLA 特征工程算法在检测 HLA-I 结合肽方面优于现有算法。广泛的评估数据表明,与预测 HLA-A*01:01 等位基因结合肽的七种现有研究相比,所提出的 HLA 算法在 AUC 方面表现更好,并在除 9 -mer 预测任务外的六个 k-mer(k=8、9、...、14 分别代表由 k 个氨基酸组成的多肽的预测任务)中达到了最佳平均 AUC 值。源代码和微调的特征提取模型可在 http://www.healthinformaticslab.org/supp/resources.php 获得。