Institute of Global Engagement & Empowerment, Yonsei University, Seoul, Republic of Korea.
Mo-Im Kim Nursing Research Institute, Yonsei University College of Nursing, Seoul, Republic of Korea.
JMIR Med Inform. 2024 Nov 22;12:e59396. doi: 10.2196/59396.
Mild cognitive impairment (MCI) poses significant challenges in early diagnosis and timely intervention. Underdiagnosis, coupled with the economic and social burden of dementia, necessitates more precise detection methods. Machine learning (ML) algorithms show promise in managing complex data for MCI and dementia prediction.
This study assessed the predictive accuracy of ML models in identifying the onset of MCI and dementia using the Korean Longitudinal Study of Aging (KLoSA) dataset.
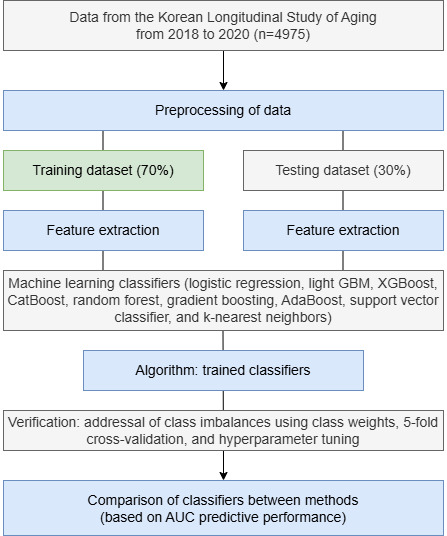
This study used data from the KLoSA, a comprehensive biennial survey that tracks the demographic, health, and socioeconomic aspects of middle-aged and older Korean adults from 2018 to 2020. Among the 6171 initial households, 4975 eligible older adult participants aged 60 years or older were selected after excluding individuals based on age and missing data. The identification of MCI and dementia relied on self-reported diagnoses, with sociodemographic and health-related variables serving as key covariates. The dataset was categorized into training and test sets to predict MCI and dementia by using multiple models, including logistic regression, light gradient-boosting machine, XGBoost (extreme gradient boosting), CatBoost, random forest, gradient boosting, AdaBoost, support vector classifier, and k-nearest neighbors, and the training and test sets were used to evaluate predictive performance. The performance was assessed using the area under the receiver operating characteristic curve (AUC). Class imbalances were addressed via weights. Shapley additive explanation values were used to determine the contribution of each feature to the prediction rate.
Among the 4975 participants, the best model for predicting MCI onset was random forest, with a median AUC of 0.6729 (IQR 0.3883-0.8152), followed by k-nearest neighbors with a median AUC of 0.5576 (IQR 0.4555-0.6761) and support vector classifier with a median AUC of 0.5067 (IQR 0.3755-0.6389). For dementia onset prediction, the best model was XGBoost, achieving a median AUC of 0.8185 (IQR 0.8085-0.8285), closely followed by light gradient-boosting machine with a median AUC of 0.8069 (IQR 0.7969-0.8169) and AdaBoost with a median AUC of 0.8007 (IQR 0.7907-0.8107). The Shapley values highlighted pain in everyday life, being widowed, living alone, exercising, and living with a partner as the strongest predictors of MCI. For dementia, the most predictive features were other contributing factors, education at the high school level, education at the middle school level, exercising, and monthly social engagement.
ML algorithms, especially XGBoost, exhibited the potential for predicting MCI onset using KLoSA data. However, no model has demonstrated robust accuracy in predicting MCI and dementia. Sociodemographic and health-related factors are crucial for initiating cognitive conditions, emphasizing the need for multifaceted predictive models for early identification and intervention. These findings underscore the potential and limitations of ML in predicting cognitive impairment in community-dwelling older adults.
轻度认知障碍(MCI)在早期诊断和及时干预方面带来了重大挑战。由于漏诊以及痴呆症的经济和社会负担,我们需要更精确的检测方法。机器学习(ML)算法在管理 MCI 和痴呆症预测的复杂数据方面显示出了潜力。
本研究评估了使用韩国老龄化纵向研究(KLoSA)数据集的 ML 模型在识别 MCI 和痴呆症发病方面的预测准确性。
本研究使用了 KLoSA 的数据,这是一项对中年及以上韩国成年人进行的全面两年一次的调查,从 2018 年到 2020 年跟踪他们的人口统计学、健康和社会经济方面。在最初的 6171 个家庭中,选择了 4975 名符合条件的 60 岁及以上的老年参与者,这些参与者是在根据年龄和缺失数据排除了一些人之后选择的。MCI 和痴呆症的识别依赖于自我报告的诊断,社会人口统计学和与健康相关的变量是关键的协变量。该数据集被分为训练集和测试集,通过使用多种模型,包括逻辑回归、轻梯度提升机、XGBoost(极端梯度提升)、CatBoost、随机森林、梯度提升、AdaBoost、支持向量分类器和 K-最近邻,来预测 MCI 和痴呆症,然后使用训练集和测试集来评估预测性能。使用接收器操作特征曲线下的面积(AUC)来评估性能。通过权重来解决类别不平衡问题。Shapley 加性解释值用于确定每个特征对预测率的贡献。
在 4975 名参与者中,预测 MCI 发病的最佳模型是随机森林,其中位数 AUC 为 0.6729(IQR 0.3883-0.8152),其次是 K-最近邻,中位数 AUC 为 0.5576(IQR 0.4555-0.6761)和支持向量分类器,中位数 AUC 为 0.5067(IQR 0.3755-0.6389)。对于痴呆症发病预测,最佳模型是 XGBoost,其中位数 AUC 为 0.8185(IQR 0.8085-0.8285),紧随其后的是轻梯度提升机,中位数 AUC 为 0.8069(IQR 0.7969-0.8169)和 AdaBoost,中位数 AUC 为 0.8007(IQR 0.7907-0.8107)。Shapley 值突出了日常生活中的疼痛、丧偶、独居、锻炼和与伴侣生活是 MCI 的最强预测因素。对于痴呆症,最具预测性的特征是其他促成因素、高中教育、中学教育、锻炼和每月的社交参与。
ML 算法,特别是 XGBoost,在使用 KLoSA 数据预测 MCI 发病方面显示出了潜力。然而,没有一种模型在预测 MCI 和痴呆症方面表现出稳健的准确性。社会人口统计学和与健康相关的因素对认知状况的发生至关重要,这强调了需要针对早期识别和干预的多方面预测模型。这些发现突出了 ML 在预测社区居住的老年人群体认知障碍方面的潜力和局限性。