Connectome - Student Association for Neurosurgery, Neurology and Neurosciences, Berlin, Germany.
Department of Neurosurgery, University Hospital of Münster, Münster, Germany.
BMC Med Educ. 2024 Nov 28;24(1):1391. doi: 10.1186/s12909-024-06399-7.
Clinical decision-making (CDM) refers to physicians' ability to gather, evaluate, and interpret relevant diagnostic information. An integral component of CDM is the medical history conversation, traditionally practiced on real or simulated patients. In this study, we explored the potential of using Large Language Models (LLM) to simulate patient-doctor interactions and provide structured feedback.
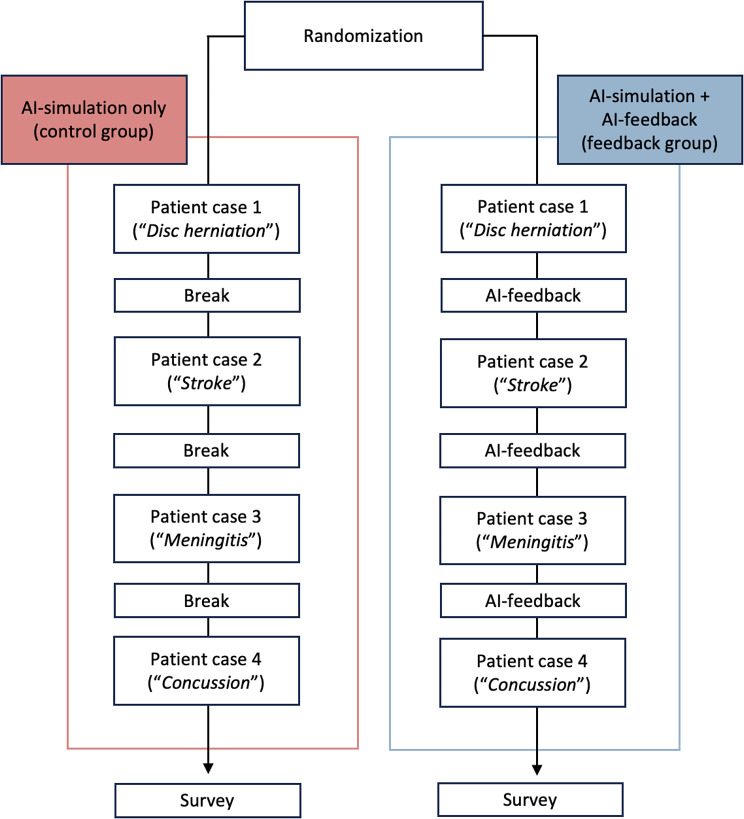
We developed AI prompts to simulate patients with different symptoms, engaging in realistic medical history conversations. In our double-blind randomized design, the control group participated in simulated medical history conversations with AI patients (control group), while the intervention group, in addition to simulated conversations, also received AI-generated feedback on their performances (feedback group). We examined the influence of feedback based on their CDM performance, which was evaluated by two raters (ICC = 0.924) using the Clinical Reasoning Indicator - History Taking Inventory (CRI-HTI). The data was analyzed using an ANOVA for repeated measures.
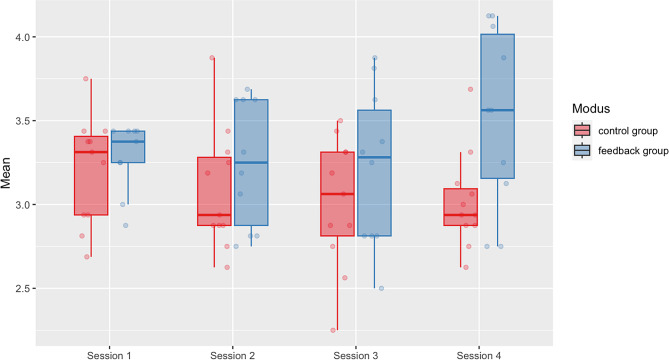
Our final sample included 21 medical students (age = 22.10 years, semester = 4, 14 females). At baseline, the feedback group (mean = 3.28 ± 0.09 [standard deviation]) and the control group (3.21 ± 0.08) achieved similar CRI-HTI scores, indicating successful randomization. After only four training sessions, the feedback group (3.60 ± 0.13) outperformed the control group (3.02 ± 0.12), F (1,18) = 4.44, p = .049 with a strong effect size, partial η = 0.198. Specifically, the feedback group showed improvements in the subdomains of CDM of creating context (p = .046) and securing information (p = .018), while their ability to focus questions did not improve significantly (p = .265).
The results suggest that AI-simulated medical history conversations can support CDM training, especially when combined with structured feedback. Such training format may serve as a cost-effective supplement to existing training methods, better preparing students for real medical history conversations.
临床决策(CDM)是指医生收集、评估和解释相关诊断信息的能力。CDM 的一个组成部分是传统上在真实或模拟患者身上进行的病史对话。在这项研究中,我们探讨了使用大型语言模型(LLM)模拟医患互动并提供结构化反馈的潜力。
我们开发了 AI 提示来模拟具有不同症状的患者,进行逼真的病史对话。在我们的双盲随机设计中,对照组与 AI 患者进行模拟病史对话(对照组),而干预组除了模拟对话外,还收到了基于他们表现的 AI 生成的反馈(反馈组)。我们根据他们的 CDM 表现来检查反馈的影响,这是由两位评估者(ICC=0.924)使用临床推理指标-病史采集清单(CRI-HTI)进行评估的。数据使用重复测量的 ANOVA 进行分析。
我们的最终样本包括 21 名医学生(年龄=22.10 岁,学期=4,14 名女性)。在基线时,反馈组(均值=3.28±0.09[标准差])和对照组(3.21±0.08)的 CRI-HTI 得分相似,表明随机分组成功。仅经过四次培训后,反馈组(3.60±0.13)的表现优于对照组(3.02±0.12),F(1,18)=4.44,p=0.049,效应量较大,部分η=0.198。具体而言,反馈组在创建背景(p=0.046)和获取信息(p=0.018)方面的 CDM 子领域表现有所提高,而他们的聚焦问题能力没有显著提高(p=0.265)。
结果表明,AI 模拟的病史对话可以支持 CDM 培训,尤其是当与结构化反馈结合使用时。这种培训形式可能成为现有培训方法的经济有效的补充,使学生更好地为真实的病史对话做好准备。