Zanatta Luca, Barchi Francesco, Manoni Simone, Tolu Silvia, Bartolini Andrea, Acquaviva Andrea
Department of Electrical, Electronic, and Information Engineering "Guglielmo Marconi", Università di Bologna, 40126, Bologna, Italy.
Department of Electrical and Photonics Engineering Automation and Control, Danmarks Tekniske Universitet, 2800, Lyngby-Taarbæk, Denmark.
Sci Rep. 2024 Dec 28;14(1):30648. doi: 10.1038/s41598-024-77779-8.
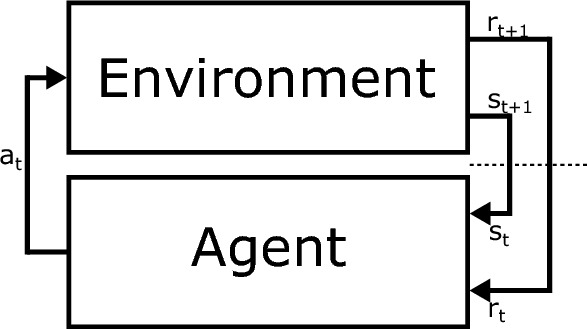
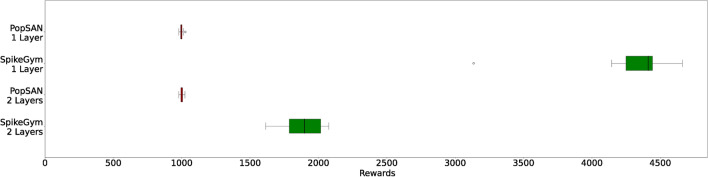
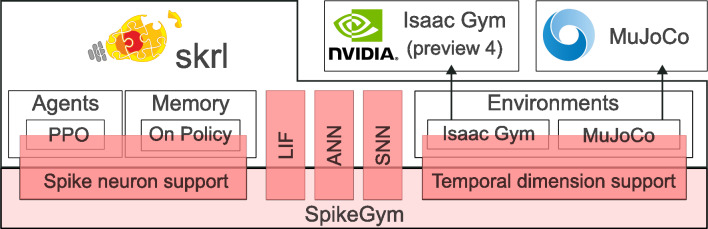
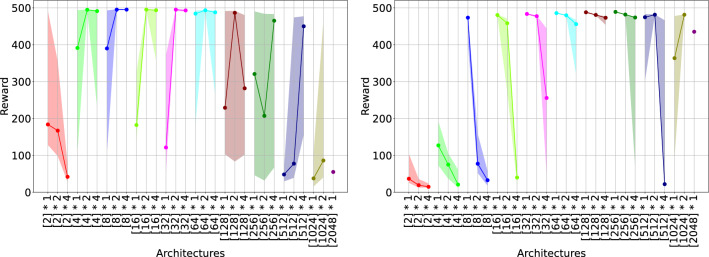
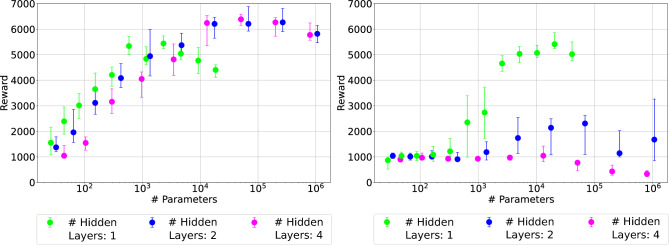
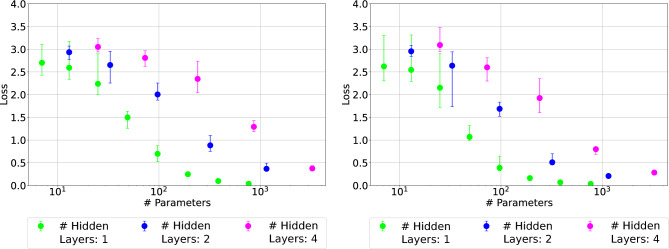
Spiking Neural Networks (SNNs) stand as the third generation of Artificial Neural Networks (ANNs), mirroring the functionality of the mammalian brain more closely than their predecessors. Their computational units, spiking neurons, characterized by Ordinary Differential Equations (ODEs), allow for dynamic system representation, with spikes serving as the medium for asynchronous communication among neurons. Due to their inherent ability to capture input dynamics, SNNs hold great promise for deep networks in Reinforcement Learning (RL) tasks. Deep RL (DRL), and in particular Proximal Policy Optimization (PPO) has been proven to be valuable for training robots due to the difficulty in creating comprehensive offline datasets that capture all environmental features. DRL combined with SNNs offers a compelling solution for tasks characterized by temporal complexity. In this work, we study the effectiveness of SNNs on DRL tasks leveraging a novel framework we developed for training SNNs with PPO in the Isaac Gym simulator implemented using the skrl library. Thanks to its significantly faster training speed compared to available SNN DRL tools, the framework allowed us to: (i) Perform an effective exploration of SNN configurations for DRL robotic tasks; (ii) Compare SNNs and ANNs for various network configurations such as the number of layers and neurons. Our work demonstrates that in DRL tasks the optimal SNN topology has a lower number of layers than ANN and we highlight how the state-of-art SNN architectures used in complex RL tasks, such as Ant, SNNs have difficulties fully leveraging deeper layers. Finally, we applied the best topology identified thanks to our Isaac Gym-based framework on Ant-v4 benchmark running on MuJoCo simulator, exhibiting a performance improvement by a factor of 4.4 over the state-of-art SNN trained on the same task.
脉冲神经网络(SNNs)是第三代人工神经网络(ANNs),比其前身更紧密地模拟哺乳动物大脑的功能。它们的计算单元,即脉冲神经元,由常微分方程(ODEs)表征,允许动态系统表示,脉冲作为神经元之间异步通信的媒介。由于其固有的捕捉输入动态的能力,SNNs在强化学习(RL)任务中的深度网络方面具有很大的潜力。深度强化学习(DRL),特别是近端策略优化(PPO),由于难以创建捕获所有环境特征的全面离线数据集,已被证明对训练机器人很有价值。DRL与SNNs相结合为具有时间复杂性的任务提供了一个引人注目的解决方案。在这项工作中,我们利用我们开发的一个新颖框架,在使用skrl库实现的Isaac Gym模拟器中用PPO训练SNNs,研究SNNs在DRL任务上的有效性。由于与现有的SNN DRL工具相比,其训练速度明显更快,该框架使我们能够:(i)对DRL机器人任务的SNN配置进行有效探索;(ii)比较SNNs和ANNs在各种网络配置(如层数和神经元数量)方面的情况。我们的工作表明,在DRL任务中,最优的SNN拓扑结构的层数比ANN少,并且我们强调了在复杂RL任务(如蚂蚁任务)中使用的最先进的SNN架构,SNNs在充分利用更深层方面存在困难。最后,我们将基于Isaac Gym的框架所确定的最佳拓扑结构应用于在MuJoCo模拟器上运行的Ant-v4基准测试,与在同一任务上训练的最先进的SNN相比,性能提高了4.4倍。