Feng Huini, Ju Ying, Yin Xiaofeng, Qiu Wenshi, Zhang Xu
School of Mathematics and Statistics, Southwest University, Chongqing, China.
School of Informatics, Xiamen University, Xiamen, China.
Brief Funct Genomics. 2025 Jan 15;24. doi: 10.1093/bfgp/elae048.
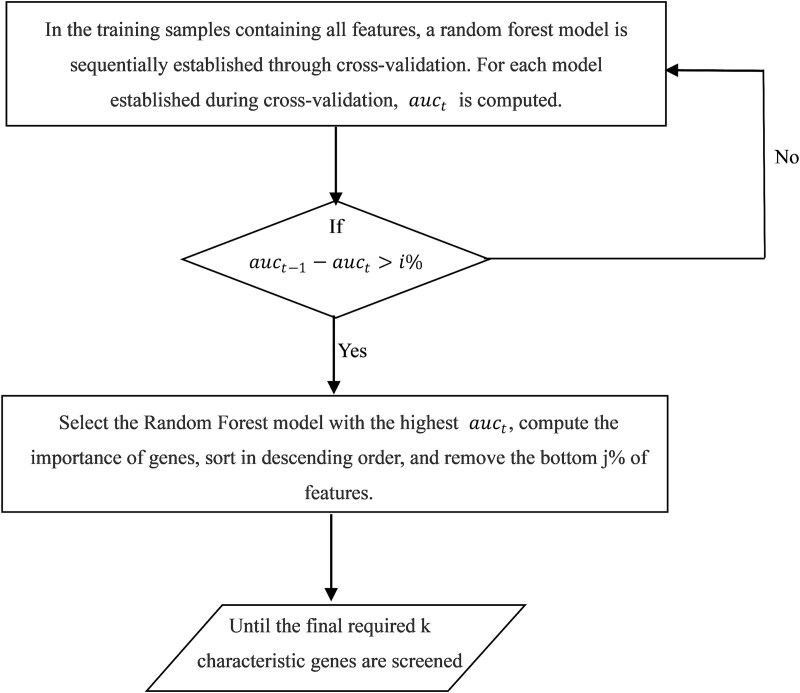
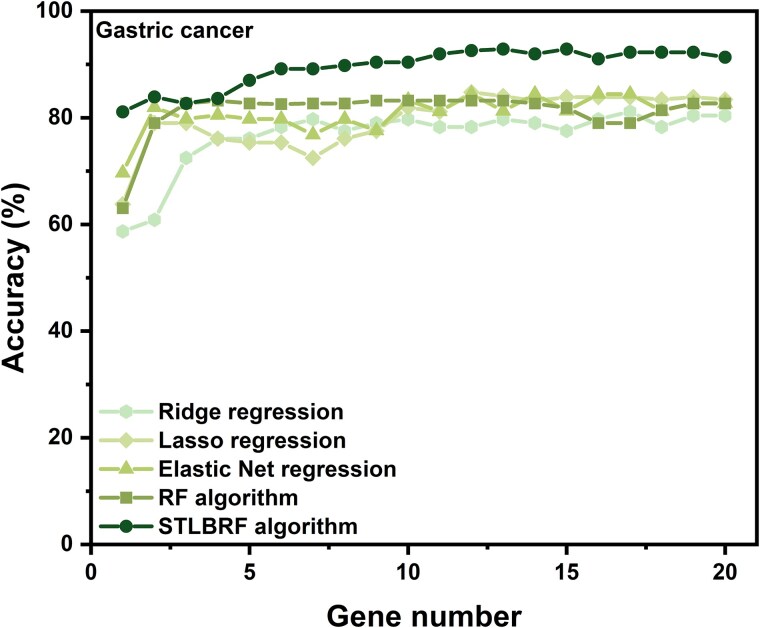
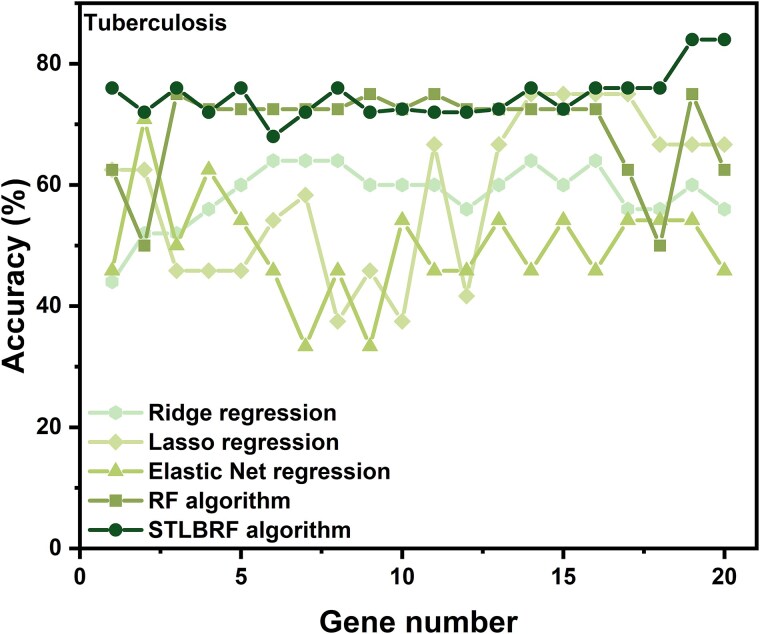
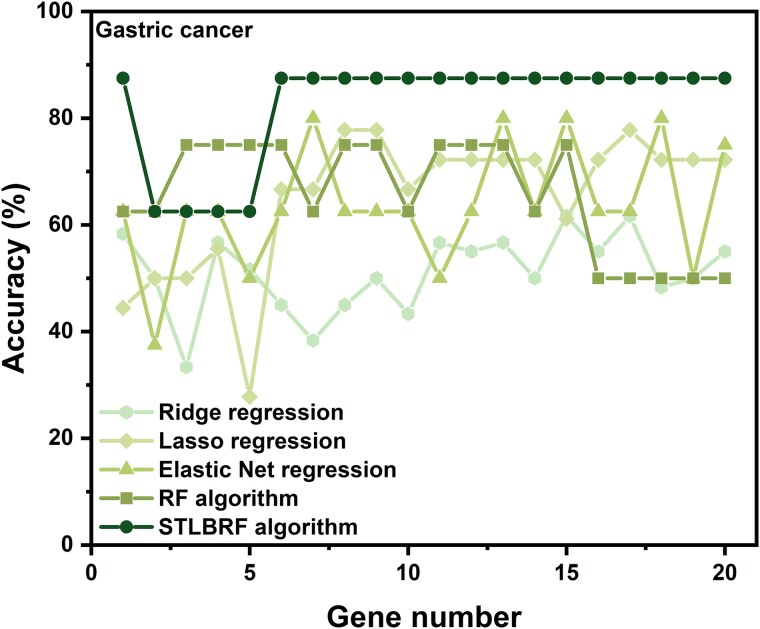
When the traditional random forest (RF) algorithm is used to select feature elements in biostatistical data, a large amount of noise data and parameters can affect the importance of the selected feature elements, making the control of feature selection difficult. Therefore, it is a challenge for the traditional RF algorithm to preserve the accuracy of algorithm results in the presence of noise data. Generally, directly removing noise data can result in significant bias in the results. In this study, we develop a new algorithm, standardized threshold, and loops based random forest (STLBRF), and apply it to the field of gene expression data for feature gene selection. This algorithm, based on the traditional RF algorithm, combines backward elimination and K-fold cross-validation to construct a cyclic system and set a standardized threshold: error increment. The algorithm overcomes the shortcomings of existing gene selection methods. We compare ridge regression, lasso regression, elastic net regression, the traditional RF algorithm, and our improved RF algorithm using three real gene expression datasets and conducting a quantitative analysis. To ensure the reliability of the results, we validate the effectiveness of the genes selected by these methods using the Random Forest classifier. The results indicate that, compared to other methods, the STLBRF algorithm achieves not only higher effectiveness in feature gene selection but also better control over the number of selected genes. Our method offers reliable technical support for feature expression analysis and research on biomarker selection.
当使用传统随机森林(RF)算法在生物统计数据中选择特征元素时,大量噪声数据和参数会影响所选特征元素的重要性,使得特征选择的控制变得困难。因此,对于传统RF算法来说,在存在噪声数据的情况下保持算法结果的准确性是一项挑战。一般来说,直接去除噪声数据会导致结果出现显著偏差。在本研究中,我们开发了一种新算法,即基于标准化阈值和循环的随机森林(STLBRF),并将其应用于基因表达数据领域进行特征基因选择。该算法在传统RF算法的基础上,结合向后消除和K折交叉验证来构建一个循环系统,并设置一个标准化阈值:误差增量。该算法克服了现有基因选择方法的缺点。我们使用三个真实的基因表达数据集,并进行定量分析,比较了岭回归、套索回归、弹性网回归、传统RF算法和我们改进的RF算法。为确保结果的可靠性,我们使用随机森林分类器验证了这些方法所选基因的有效性。结果表明,与其他方法相比,STLBRF算法不仅在特征基因选择方面具有更高的有效性,而且对所选基因的数量有更好的控制。我们的方法为特征表达分析和生物标志物选择研究提供了可靠的技术支持。