Kumar Abhinav, Rodrigues Paul, Kareem A K, Sekac Tingneyuc, Abdullaev Sherzod, Chohan Jasgurpreet Singh, Manjunatha R, Rethik Kumar, Dasi Shivakrishna, Kiani Mahmood
Department of Nuclear and Renewable Energy, Ural Federal University Named After the First President of Russia Boris Yeltsin, Ekaterinburg, 620002, Russia.
Department of Technical Sciences, Western Caspian University, Baku, Azerbaijan.
Sci Rep. 2025 Jan 2;15(1):373. doi: 10.1038/s41598-024-84556-0.
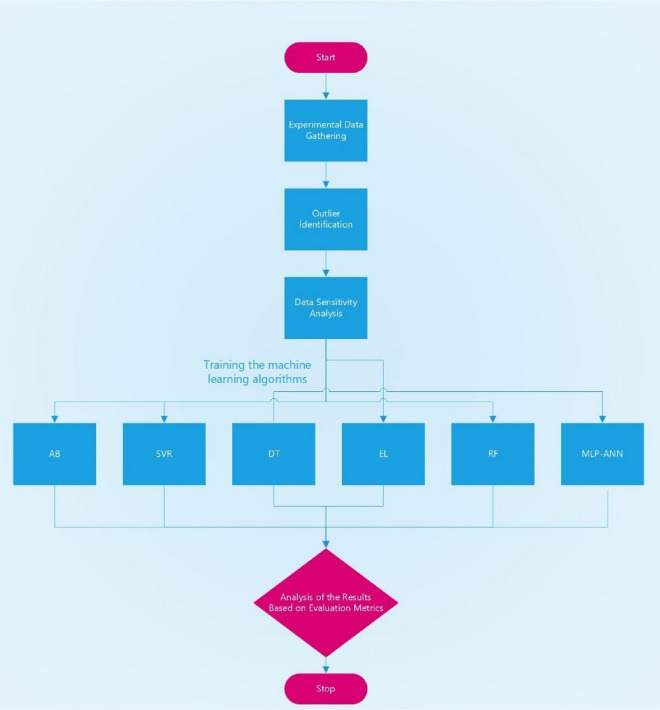
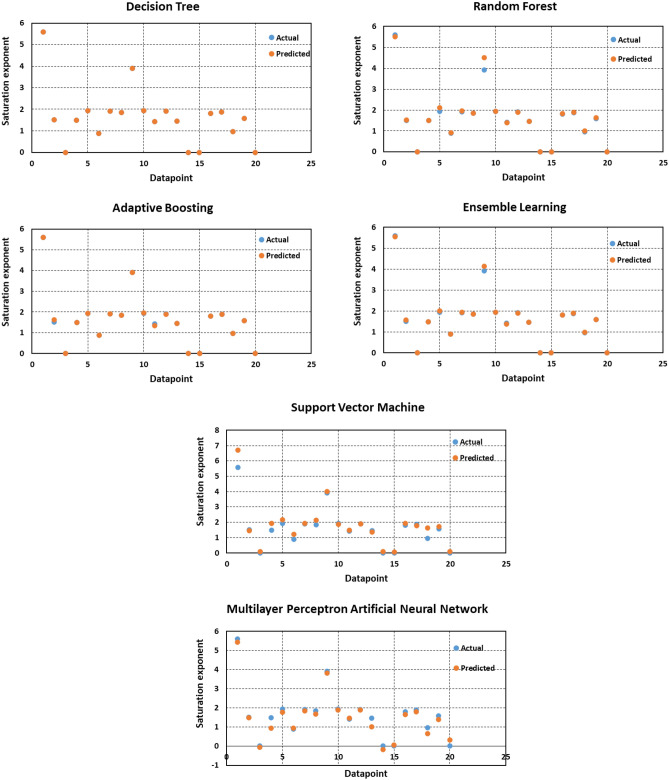
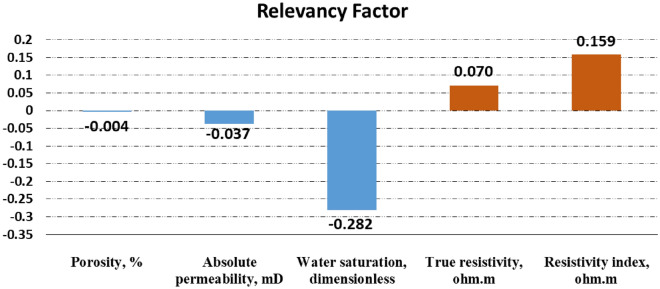
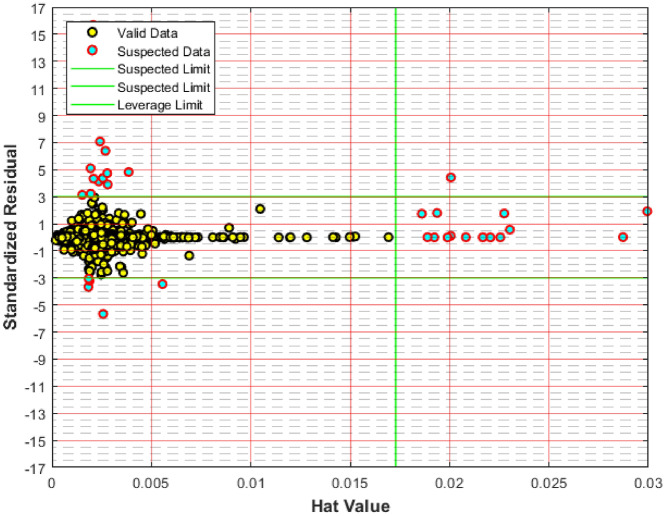
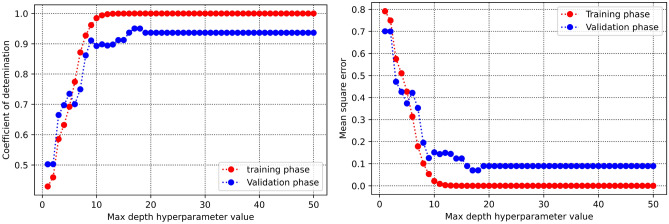
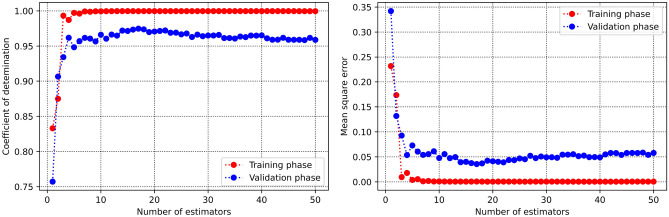
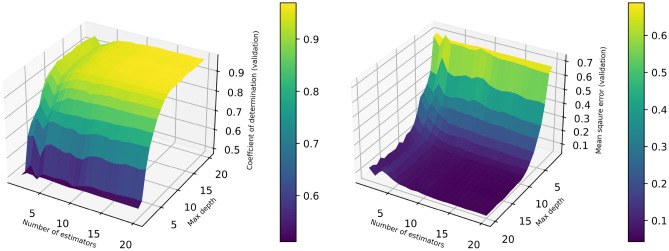
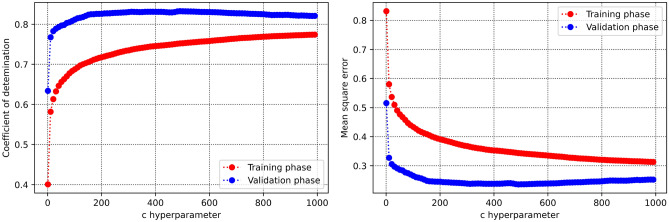
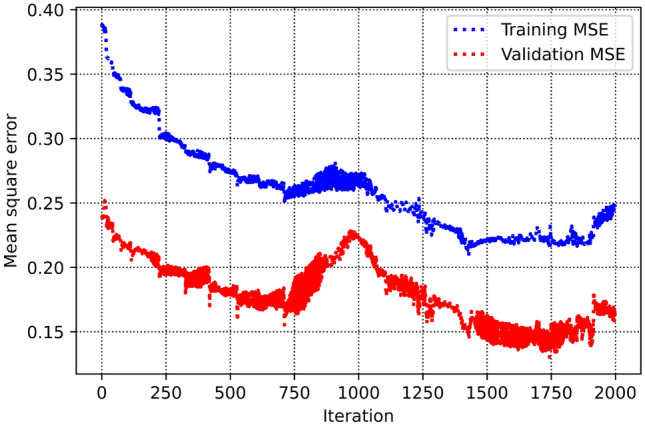
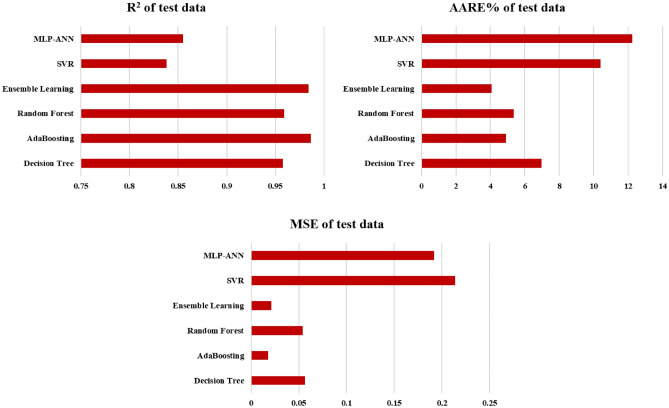
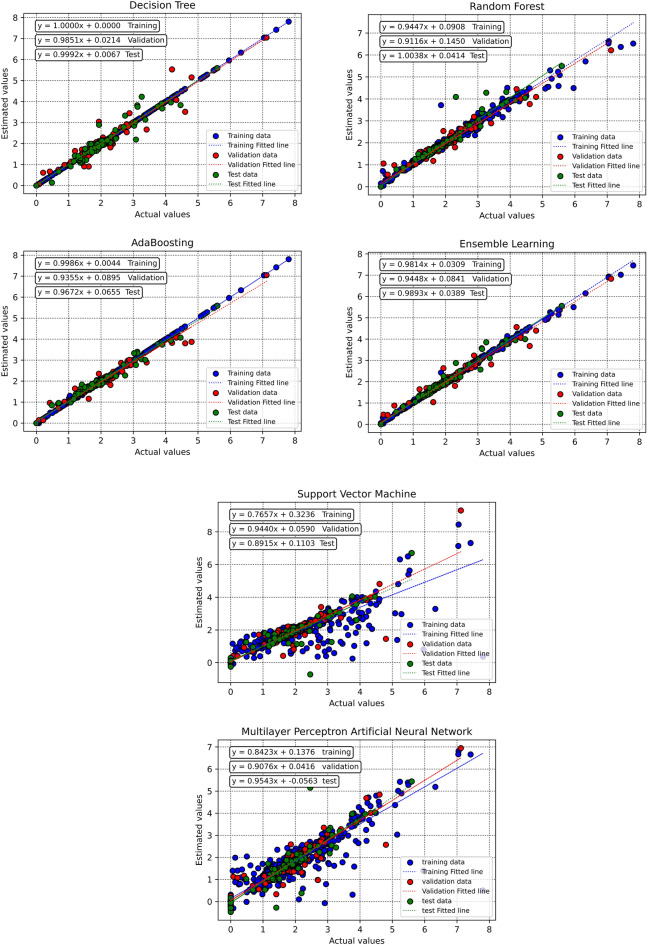
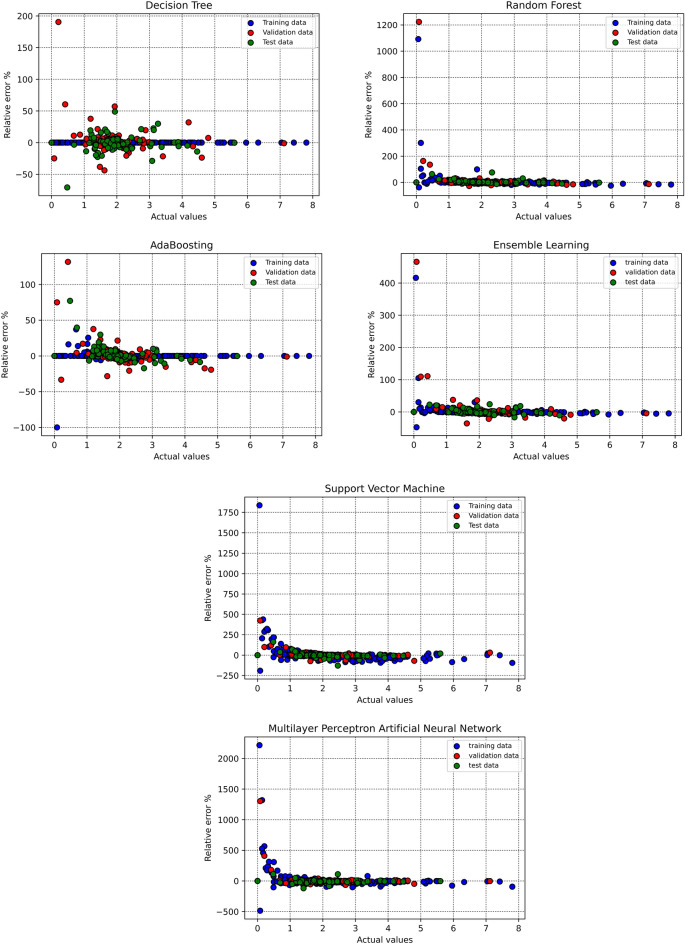
Precise estimation of rock petrophysical parameters are seriously important for the reliable computation of hydrocarbon in place in the underground formations. Therefore, accurately estimation rock saturation exponent is necessary in this regard. In this communication, we aim to develop intelligent data-driven models of decision tree, random forest, ensemble learning, adaptive boosting, support vector machine and multilayer perceptron artificial neural network to predict rock saturation exponent parameter in terms of rock absolute permeability, porosity, resistivity index, true resistivity, and water saturation based on acquired 1041 field data. A well-known outlier detection algorithm is applied on the gathered data to assess the data reliability before model development. Additionally, relevancy factor is estimated for each input parameter to assess the relative effects of input parameters on the saturation exponent. The sensitivity analysis indicates that resistivity index and true resistivity have direct correlation with the saturation exponent while porosity, absolute permeability and water saturation is inversely related with saturation exponent. In addition, the graphical-based and statistical-based evaluations illustrate that AdaBoost and ensemble learning models outperforms all other developed data-driven intelligent models as these two models are associated with lowest values of mean square error (adaptive boosting: 0.017 and ensemble learning: 0.021 based on unseen test data) and largest values of coefficient of determination (adaptive boosting: 0.986 and ensemble learning: 0.983 based on unseen test data).
准确估算岩石的岩石物理参数对于可靠计算地下地层中的原地烃类至关重要。因此,在这方面准确估算岩石饱和度指数是必要的。在本交流中,我们旨在开发决策树、随机森林、集成学习、自适应提升、支持向量机和多层感知器人工神经网络等智能数据驱动模型,以根据获取的1041个现场数据,依据岩石绝对渗透率、孔隙度、电阻率指数、真电阻率和含水饱和度来预测岩石饱和度指数参数。在模型开发之前,对收集的数据应用一种著名的异常值检测算法来评估数据的可靠性。此外,还为每个输入参数估计相关性因子,以评估输入参数对饱和度指数的相对影响。敏感性分析表明,电阻率指数和真电阻率与饱和度指数直接相关,而孔隙度、绝对渗透率和含水饱和度与饱和度指数呈负相关。此外,基于图形和基于统计的评估表明,AdaBoost和集成学习模型优于所有其他开发的数据驱动智能模型,因为这两个模型的均方误差值最低(基于未见过的测试数据,自适应提升:0.017,集成学习:0.021),决定系数值最大(基于未见过的测试数据,自适应提升:0.986,集成学习:0.983)。