Singhal Karan, Tu Tao, Gottweis Juraj, Sayres Rory, Wulczyn Ellery, Amin Mohamed, Hou Le, Clark Kevin, Pfohl Stephen R, Cole-Lewis Heather, Neal Darlene, Rashid Qazi Mamunur, Schaekermann Mike, Wang Amy, Dash Dev, Chen Jonathan H, Shah Nigam H, Lachgar Sami, Mansfield Philip Andrew, Prakash Sushant, Green Bradley, Dominowska Ewa, Agüera Y Arcas Blaise, Tomašev Nenad, Liu Yun, Wong Renee, Semturs Christopher, Mahdavi S Sara, Barral Joelle K, Webster Dale R, Corrado Greg S, Matias Yossi, Azizi Shekoofeh, Karthikesalingam Alan, Natarajan Vivek
Google Research, Mountain View, CA, USA.
Google DeepMind, Mountain View, CA, USA.
Nat Med. 2025 Mar;31(3):943-950. doi: 10.1038/s41591-024-03423-7. Epub 2025 Jan 8.
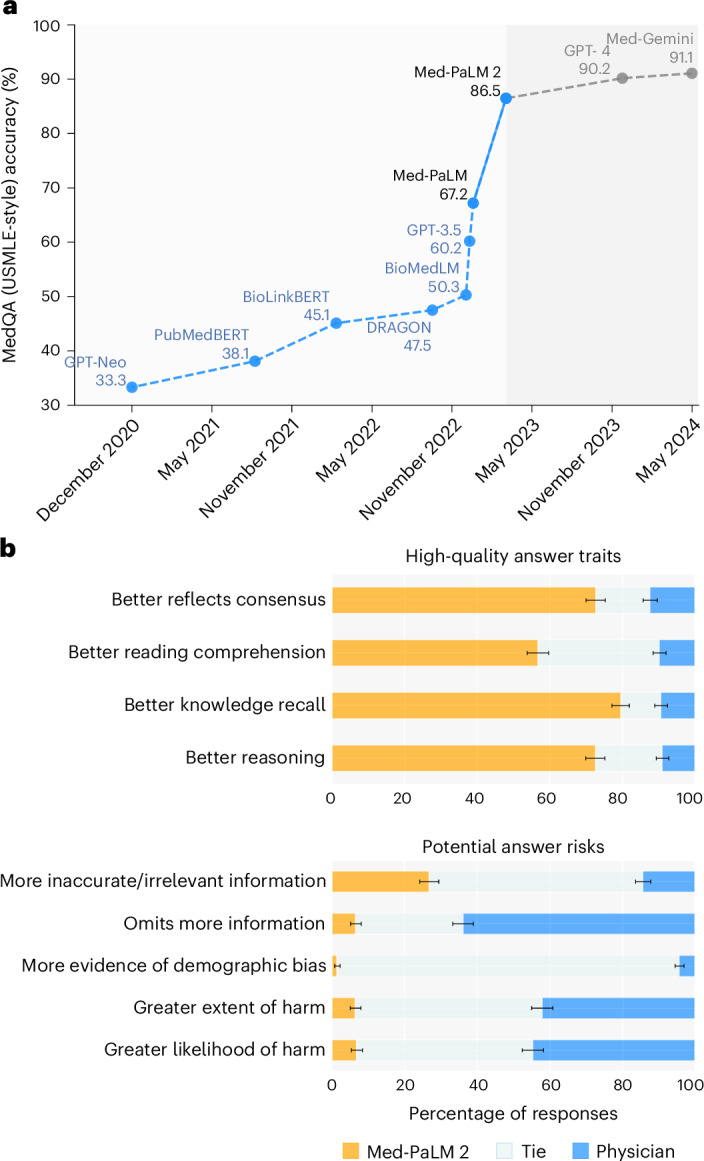
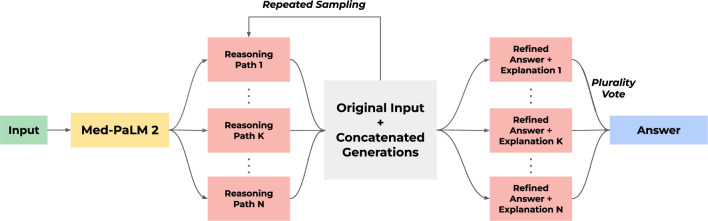
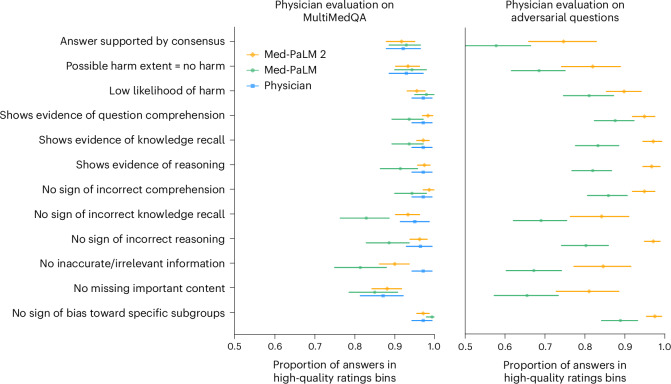
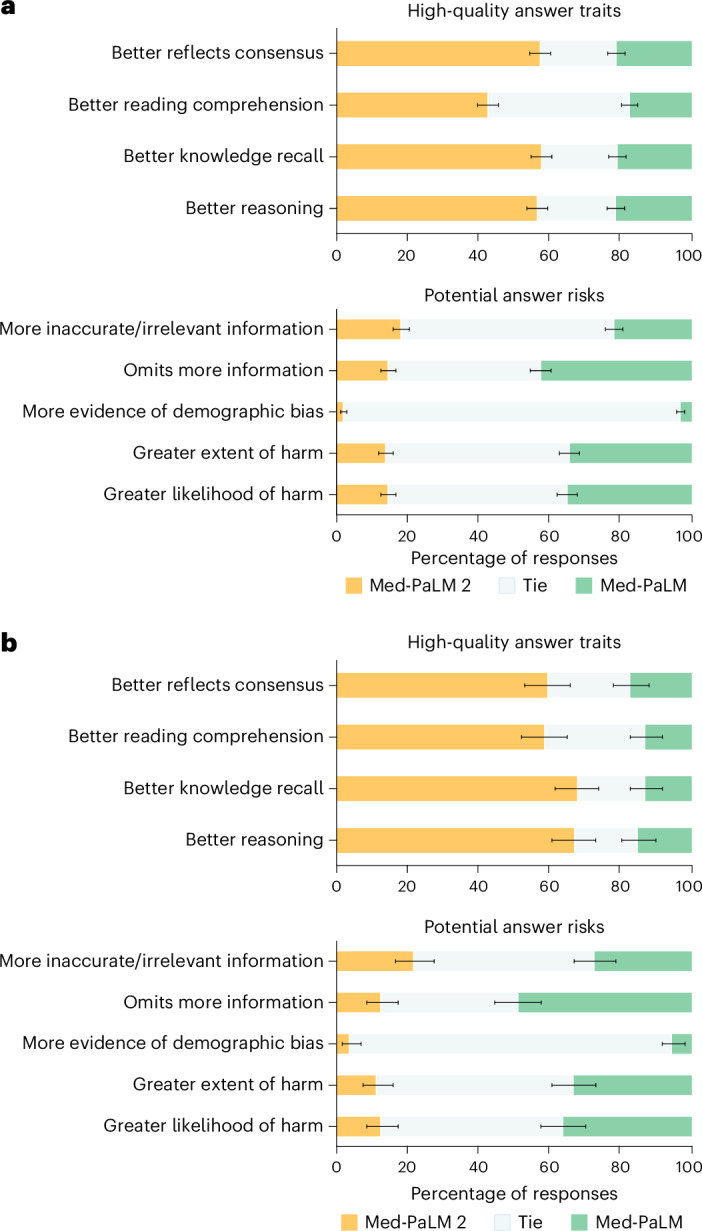
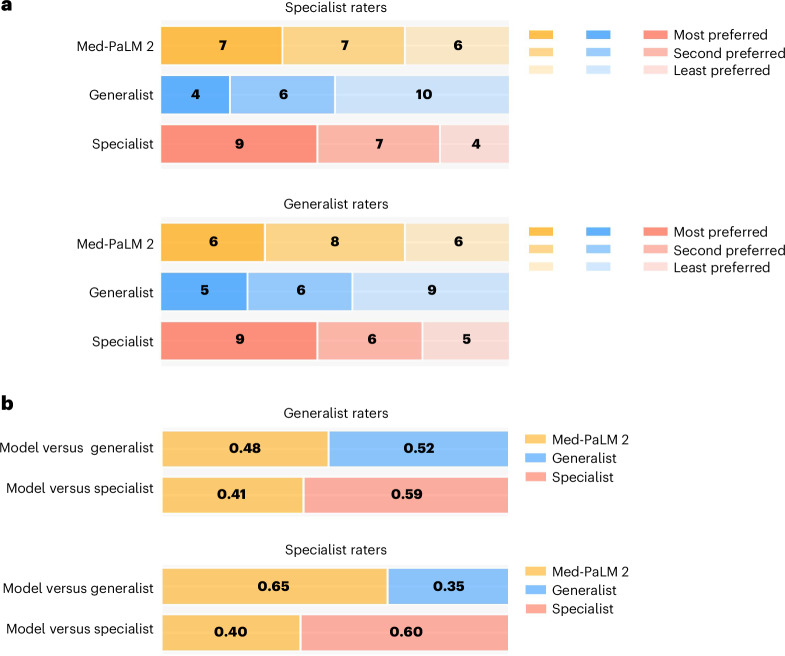
Large language models (LLMs) have shown promise in medical question answering, with Med-PaLM being the first to exceed a 'passing' score in United States Medical Licensing Examination style questions. However, challenges remain in long-form medical question answering and handling real-world workflows. Here, we present Med-PaLM 2, which bridges these gaps with a combination of base LLM improvements, medical domain fine-tuning and new strategies for improving reasoning and grounding through ensemble refinement and chain of retrieval. Med-PaLM 2 scores up to 86.5% on the MedQA dataset, improving upon Med-PaLM by over 19%, and demonstrates dramatic performance increases across MedMCQA, PubMedQA and MMLU clinical topics datasets. Our detailed human evaluations framework shows that physicians prefer Med-PaLM 2 answers to those from other physicians on eight of nine clinical axes. Med-PaLM 2 also demonstrates significant improvements over its predecessor across all evaluation metrics, particularly on new adversarial datasets designed to probe LLM limitations (P < 0.001). In a pilot study using real-world medical questions, specialists preferred Med-PaLM 2 answers to generalist physician answers 65% of the time. While specialist answers were still preferred overall, both specialists and generalists rated Med-PaLM 2 to be as safe as physician answers, demonstrating its growing potential in real-world medical applications.
大语言模型(LLMs)在医学问答方面已展现出潜力,Med-PaLM是首个在美国医学执照考试风格问题中获得“及格”分数的模型。然而,在长篇医学问答和处理现实世界工作流程方面仍存在挑战。在此,我们展示了Med-PaLM 2,它通过基础大语言模型改进、医学领域微调以及通过集成优化和检索链改进推理与基础的新策略相结合,弥合了这些差距。Med-PaLM 2在MedQA数据集上的得分高达86.5%,比Med-PaLM提高了超过19%,并在MedMCQA、PubMedQA和MMLU临床主题数据集上展现出显著的性能提升。我们详细的人工评估框架表明,在九个临床维度中的八个维度上,医生更喜欢Med-PaLM 2的答案而非其他医生的答案。Med-PaLM 2在所有评估指标上也比其前身有显著改进,特别是在旨在探究大语言模型局限性的新对抗性数据集上(P < 0.001)。在一项使用现实世界医学问题的试点研究中,专家在65%的情况下更喜欢Med-PaLM 2的答案而非全科医生的答案。虽然总体上专家的答案仍然更受青睐,但专家和全科医生都认为Med-PaLM 2与医生的答案一样安全,这表明其在现实世界医学应用中的潜力不断增长。