Khodasevich Dennis, Holland Nina, van der Laan Lars, Cardenas Andres
Department of Epidemiology and Population Health, Stanford University School of Medicine, Palo Alto, California, United States of America.
Center for Environmental Research and Community Health (CERCH), University of California Berkeley School of Public Health, Berkeley, California, United States of America.
PLoS Comput Biol. 2025 Feb 6;21(2):e1012768. doi: 10.1371/journal.pcbi.1012768. eCollection 2025 Feb.
DNA methylation (DNAm) provides a window to characterize the impacts of environmental exposures and the biological aging process. Epigenetic clocks are often trained on DNAm using penalized regression of CpG sites, but recent evidence suggests potential benefits of training epigenetic predictors on principal components.
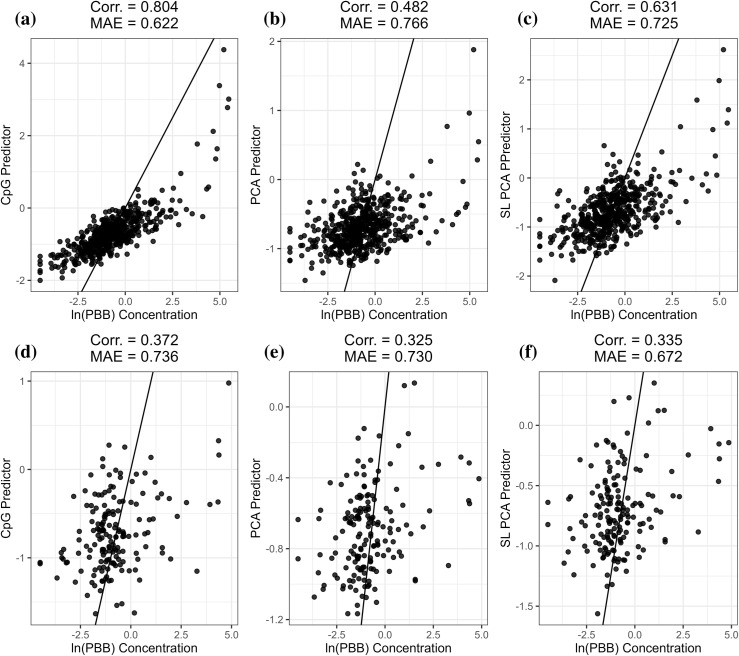
METHODOLOGY/FINDINGS: We developed a pipeline to simultaneously train three epigenetic predictors; a traditional CpG Clock, a PCA Clock, and a SuperLearner PCA Clock (SL PCA). We gathered publicly available DNAm datasets to generate i) a novel childhood epigenetic clock, ii) a reconstructed Hannum adult blood clock, and iii) as a proof of concept, a predictor of polybrominated biphenyl exposure using the three developmental methodologies. We used correlation coefficients and median absolute error to assess fit between predicted and observed measures, as well as agreement between duplicates. The SL PCA clocks improved fit with observed phenotypes relative to the PCA clocks or CpG clocks across several datasets. We found evidence for higher agreement between duplicate samples run on alternate DNAm arrays when using SL PCA clocks relative to traditional methods. Analyses examining associations between relevant exposures and epigenetic age acceleration (EAA) produced more precise effect estimates when using predictions derived from SL PCA clocks.
We introduce a novel method for the development of DNAm-based predictors that combines the improved reliability conferred by training on principal components with advanced ensemble-based machine learning. Coupling SuperLearner with PCA in the predictor development process may be especially relevant for studies with longitudinal designs utilizing multiple array types, as well as for the development of predictors of more complex phenotypic traits.
DNA甲基化(DNAm)为表征环境暴露和生物衰老过程的影响提供了一个窗口。表观遗传时钟通常通过对CpG位点进行惩罚回归来训练DNAm,但最近的证据表明,在主成分上训练表观遗传预测因子可能具有潜在益处。
方法/发现:我们开发了一个流程来同时训练三种表观遗传预测因子;传统的CpG时钟、主成分分析(PCA)时钟和超级学习主成分分析(SL PCA)时钟。我们收集了公开可用的DNAm数据集,以生成:i)一种新型儿童表观遗传时钟,ii)重建的汉纳姆成人血液时钟,以及iii)作为概念验证,使用三种发育方法来预测多溴联苯暴露。我们使用相关系数和中位数绝对误差来评估预测值与观测值之间的拟合度,以及重复样本之间的一致性。在多个数据集中,相对于PCA时钟或CpG时钟,SL PCA时钟改善了与观测表型的拟合度。我们发现,相对于传统方法,当使用SL PCA时钟时,在交替DNAm阵列上运行的重复样本之间具有更高的一致性。当使用从SL PCA时钟得出的预测时,检查相关暴露与表观遗传年龄加速(EAA)之间关联的分析产生了更精确的效应估计值。
我们介绍了一种基于DNAm的预测因子开发的新方法,该方法将在主成分上训练所带来的更高可靠性与先进的基于集成的机器学习相结合。在预测因子开发过程中将超级学习器与主成分分析相结合,对于采用多种阵列类型的纵向设计研究,以及开发更复杂表型特征的预测因子可能尤其相关。