Levartovsky Asaf, Albshesh Ahmad, Grinman Ana, Shachar Eyal, Lahat Adi, Eliakim Rami, Kopylov Uri
Gastroenterology, affiliated with Tel Aviv University, Sheba Medical Center, Tel Hashomer, Israel.
Endosc Int Open. 2025 Mar 14;13:a25420943. doi: 10.1055/a-2542-0943. eCollection 2025.
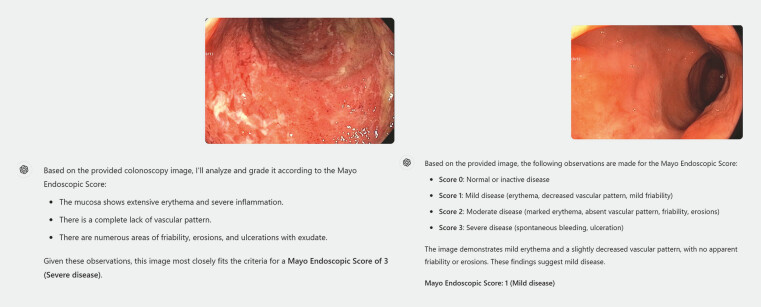
The Mayo Endoscopic Subscore (MES) is widely utilized for assessing mucosal activity in ulcerative colitis (UC). Artificial intelligence has emerged as a promising tool for enhancing diagnostic precision and addressing interobserver variability. This study evaluated the diagnostic accuracy of ChatGPT-4, a multimodal large language model, in identifying and grading endoscopic images of UC patients using the MES.
Real-world endoscopic images of UC patients were reviewed by an expert consensus board. Each image was graded based on the MES. Only images that were uniformly graded were subsequently provided to three inflammatory bowel disease (IBD) specialists and ChatGPT-4. Severity gradings of the IBD specialists and ChatGPT-4 were compared with assessments made by the expert consensus board.
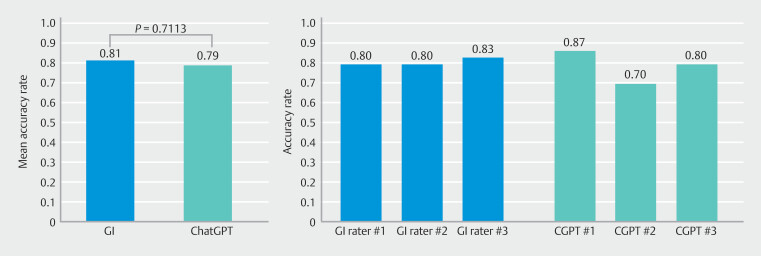
Thirty of 50 images were graded with complete agreement among the experts. Compared with the consensus board, ChatGPT-4 gradings had a mean accuracy rate of 78.9% whereas the mean accuracy rate for the IBD specialists was 81.1%. Between the two groups, there was no statistically significant difference in mean accuracy rates ( = 0.71) and a high degree of reliability was found.
ChatGPT-4 has the potential to assess mucosal inflammation severity from endoscopic images of UC patients, without prior configuration or fine-tuning. Performance rates were comparable to those of IBD specialists.
梅奥内镜亚评分(MES)被广泛用于评估溃疡性结肠炎(UC)的黏膜活性。人工智能已成为提高诊断准确性和解决观察者间差异的一种有前景的工具。本研究评估了多模态大语言模型ChatGPT-4在使用MES识别和分级UC患者内镜图像方面的诊断准确性。
由专家共识委员会对UC患者的真实世界内镜图像进行评估。每张图像根据MES进行分级。随后,仅将分级一致的图像提供给三位炎症性肠病(IBD)专家和ChatGPT-4。将IBD专家和ChatGPT-4的严重程度分级与专家共识委员会的评估结果进行比较。
50张图像中有30张在专家之间获得了完全一致的分级。与共识委员会相比,ChatGPT-4分级的平均准确率为78.9%,而IBD专家的平均准确率为81.1%。两组之间,平均准确率没有统计学显著差异(P = 0.71),并且发现具有高度可靠性。
ChatGPT-4有潜力在无需预先配置或微调的情况下,从UC患者的内镜图像评估黏膜炎症严重程度。其表现率与IBD专家相当。