Shinde Pramod, Willemsen Lisa, Anderson Michael, Aoki Minori, Basu Saonli, Burel Julie G, Cheng Peng, Ghosh Dastidar Souradipto, Dunleavy Aidan, Einav Tal, Forschmiedt Jamie, Fourati Slim, Garcia Javier, Gibson William, Greenbaum Jason A, Guan Leying, Guan Weikang, Gygi Jeremy P, Ha Brendan, Hou Joe, Hsiao Jason, Huang Yunda, Jansen Rick, Kakoty Bhargob, Kang Zhiyu, Kobie James J, Kojima Mari, Konstorum Anna, Lee Jiyeun, Lewis Sloan A, Li Aixin, Lock Eric F, Mahita Jarjapu, Mendes Marcus, Meng Hailong, Neher Aidan, Nili Somayeh, Olsen Lars Rønn, Orfield Shelby, Overton James A, Pai Nidhi, Parker Cokie, Qian Brian, Rasmussen Mikkel, Reyna Joaquin, Richardson Eve, Safo Sandra, Sorenson Josey, Srinivasan Aparna, Thrupp Nicola, Tippalagama Rashmi, Trevizani Raphael, Ventz Steffen, Wang Jiuzhou, Wu Cheng-Chang, Ay Ferhat, Grant Barry, Kleinstein Steven H, Peters Bjoern
Center for Vaccine Innovation, La Jolla Institute for Immunology, La Jolla, California, United States of America.
Division of Biostatistics and Health Data Science, University of Minnesota, Minneapolis, Minnesota, United States of America.
PLoS Comput Biol. 2025 Mar 31;21(3):e1012927. doi: 10.1371/journal.pcbi.1012927. eCollection 2025 Mar.
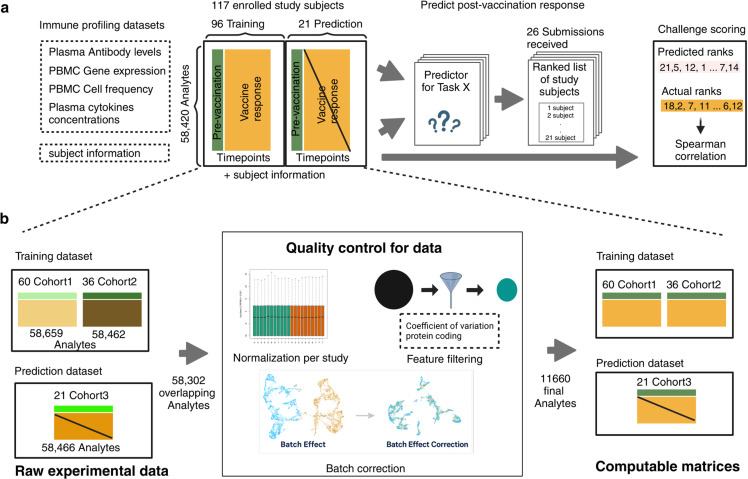
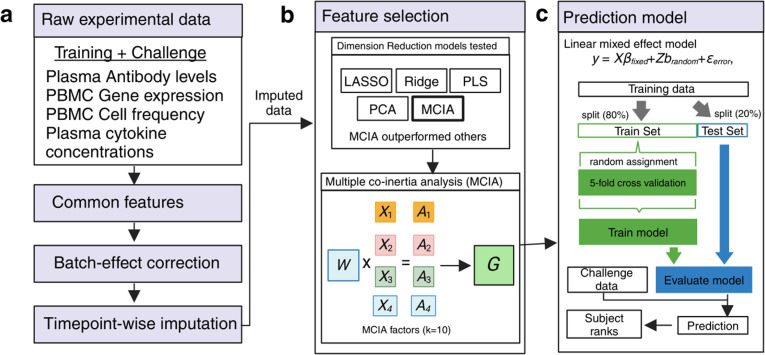
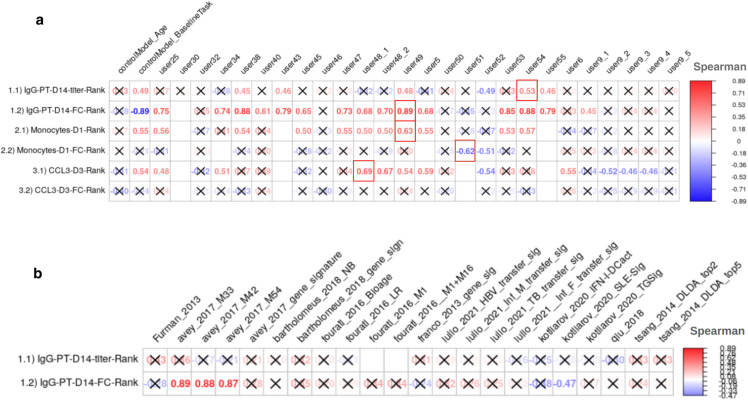
Systems vaccinology studies have been used to build computational models that predict individual vaccine responses and identify the factors contributing to differences in outcome. Comparing such models is challenging due to variability in study designs. To address this, we established a community resource to compare models predicting B. pertussis booster responses and generate experimental data for the explicit purpose of model evaluation. We here describe our second computational prediction challenge using this resource, where we benchmarked 49 algorithms from 53 scientists. We found that the most successful models stood out in their handling of nonlinearities, reducing large feature sets to representative subsets, and advanced data preprocessing. In contrast, we found that models adopted from literature that were developed to predict vaccine antibody responses in other settings performed poorly, reinforcing the need for purpose-built models. Overall, this demonstrates the value of purpose-generated datasets for rigorous and open model evaluations to identify features that improve the reliability and applicability of computational models in vaccine response prediction.
系统疫苗学研究已被用于构建预测个体疫苗反应并确定导致结果差异的因素的计算模型。由于研究设计的可变性,比较此类模型具有挑战性。为了解决这个问题,我们建立了一个社区资源,以比较预测百日咳加强针反应的模型,并专门为模型评估生成实验数据。我们在此描述使用该资源进行的第二次计算预测挑战,我们对来自53位科学家的49种算法进行了基准测试。我们发现,最成功的模型在处理非线性、将大型特征集缩减为代表性子集以及先进的数据预处理方面表现突出。相比之下,我们发现从文献中采用的、为预测其他情况下的疫苗抗体反应而开发的模型表现不佳,这凸显了构建专用模型的必要性。总体而言,这证明了专门生成的数据集对于严格且开放的模型评估的价值,以识别可提高计算模型在疫苗反应预测中的可靠性和适用性的特征。