Tang Tengjie, Li Angkai, Tan Xingye, Ji Qingli, Si Lu, Bao Le
Department of Statistics, Pennsylvania State University, University Park, Pennsylvania, U.S.A.
Key laboratory of Carcinogenesis and Translational Research, Department of Melanoma and Sarcoma, Peking University, Cancer Hospital & Institute, Beijing 100142, China.
medRxiv. 2025 Apr 7:2025.04.07.25325243. doi: 10.1101/2025.04.07.25325243.
Patients with rare cancers face substantial challenges due to limited evidence-based treatment options, resulting from sparse clinical trials. Advances in large language models (LLMs) and recommendation algorithms offer new opportunities to utilize all clinical trial information to improve clinical decisions.
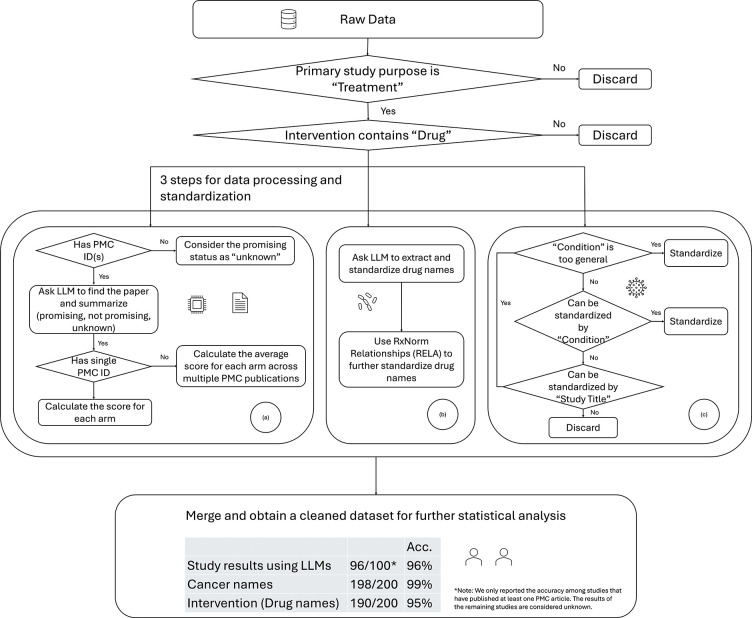
We used LLM to systematically extract and standardize more than 100,000 cancer trials from ClinicalTrials.gov. Each trial was annotated using a customized scoring system reflecting cancer-treatment interactions based on clinical outcomes and trial attributes. Using this structured data set, we implemented three state-of-the-art collaborative filtering algorithms to recommend potentially effective treatments across different cancer types.
The LLM-driven data extraction process successfully generated a comprehensive and rigorously curated database from fragmented clinical trial information, covering 78 cancer types and 5,315 distinct interventions. Recommendation models demonstrated high predictive accuracy (cross-validated RMSE: 0.49-0.62) and identified clinically meaningful new treatments for melanoma, independently validated by oncology experts.
Our study establishes a proof of concept demonstrating that the combination of LLMs with sophisticated recommendation algorithms can systematically identify novel and clinically plausible cancer treatments. This integrated approach may accelerate the identification of effective therapies for rare cancers, ultimately improving patient outcomes by generating evidence-based treatment recommendations where traditional data sources remain limited.
由于临床试验稀少,基于证据的治疗选择有限,罕见癌症患者面临巨大挑战。大语言模型(LLMs)和推荐算法的进展为利用所有临床试验信息改善临床决策提供了新机会。
我们使用大语言模型从ClinicalTrials.gov系统地提取并标准化了超过10万项癌症试验。每项试验都使用一个定制的评分系统进行注释,该系统根据临床结果和试验属性反映癌症治疗的相互作用。利用这个结构化数据集,我们实施了三种最先进的协同过滤算法,以推荐不同癌症类型中潜在有效的治疗方法。
由大语言模型驱动的数据提取过程成功地从碎片化的临床试验信息中生成了一个全面且经过严格整理的数据库,涵盖78种癌症类型和5315种不同的干预措施。推荐模型显示出较高的预测准确性(交叉验证均方根误差:0.49 - 0.62),并为黑色素瘤确定了具有临床意义的新治疗方法,经肿瘤学专家独立验证。
我们的研究建立了一个概念验证,表明大语言模型与复杂的推荐算法相结合可以系统地识别新的且临床上合理的癌症治疗方法。这种综合方法可能会加速为罕见癌症确定有效治疗方法,最终通过在传统数据来源有限的情况下生成基于证据的治疗建议来改善患者预后。