National Center for Biotechnology Information (NCBI), National Library of Medicine (NLM), National Institutes of Health (NIH), Bethesda, USA.
Department of Computer Science, University of Illinois Urbana-Champaign, Urbana, IL, USA.
Nat Commun. 2024 Nov 18;15(1):9074. doi: 10.1038/s41467-024-53081-z.
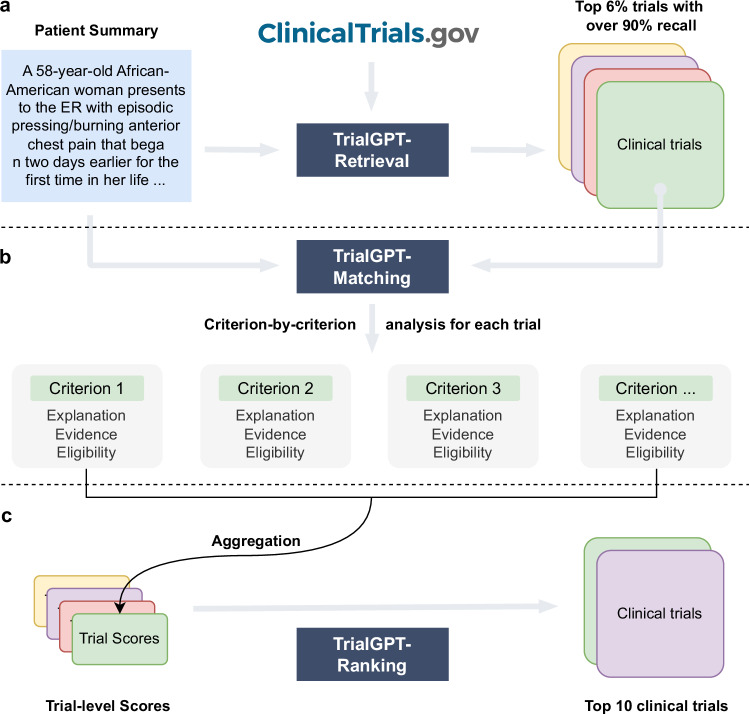
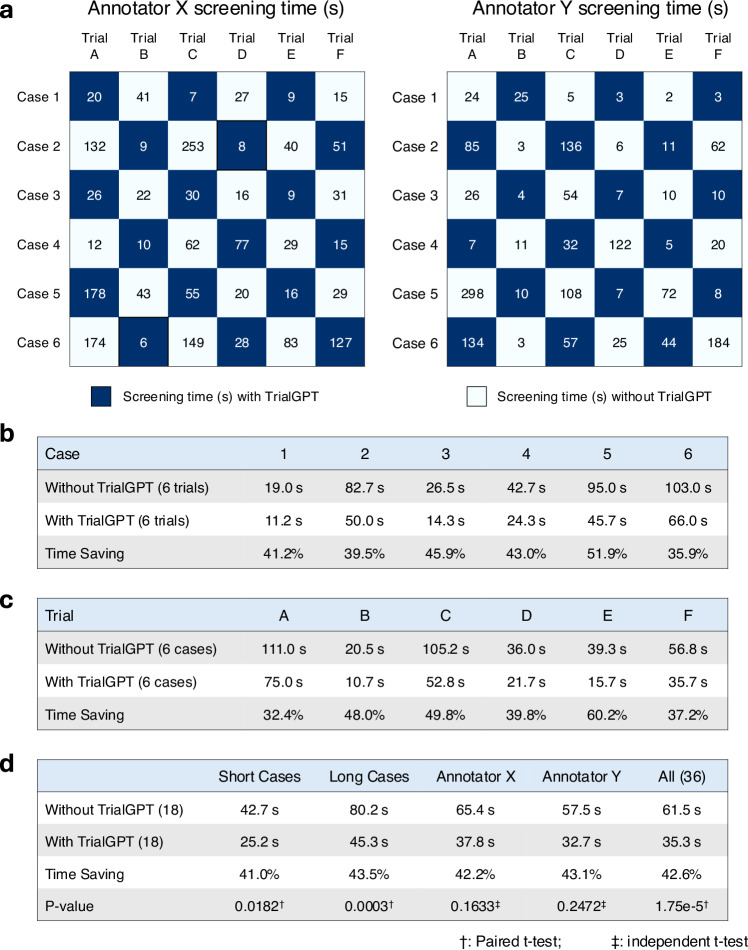
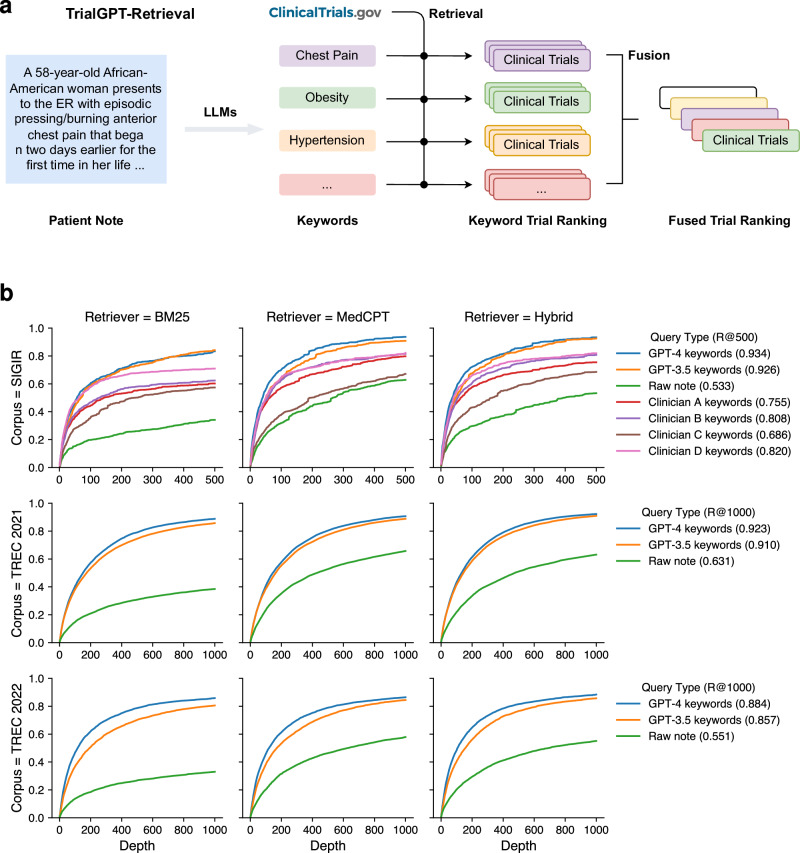
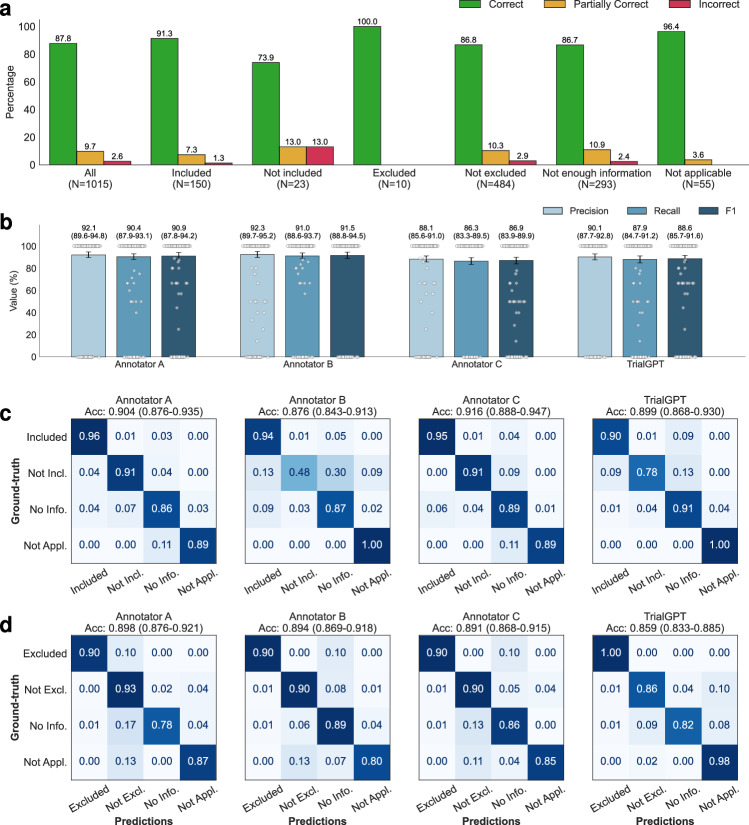
Patient recruitment is challenging for clinical trials. We introduce TrialGPT, an end-to-end framework for zero-shot patient-to-trial matching with large language models. TrialGPT comprises three modules: it first performs large-scale filtering to retrieve candidate trials (TrialGPT-Retrieval); then predicts criterion-level patient eligibility (TrialGPT-Matching); and finally generates trial-level scores (TrialGPT-Ranking). We evaluate TrialGPT on three cohorts of 183 synthetic patients with over 75,000 trial annotations. TrialGPT-Retrieval can recall over 90% of relevant trials using less than 6% of the initial collection. Manual evaluations on 1015 patient-criterion pairs show that TrialGPT-Matching achieves an accuracy of 87.3% with faithful explanations, close to the expert performance. The TrialGPT-Ranking scores are highly correlated with human judgments and outperform the best-competing models by 43.8% in ranking and excluding trials. Furthermore, our user study reveals that TrialGPT can reduce the screening time by 42.6% in patient recruitment. Overall, these results have demonstrated promising opportunities for patient-to-trial matching with TrialGPT.
患者招募对临床试验来说具有挑战性。我们引入了 TrialGPT,这是一种端到端的零样本患者与试验匹配的大型语言模型框架。TrialGPT 由三个模块组成:首先进行大规模筛选以检索候选试验(TrialGPT-Retrieval);然后预测标准级别的患者资格(TrialGPT-Matching);最后生成试验级别的评分(TrialGPT-Ranking)。我们在三个包含超过 75000 个试验注释的 183 名合成患者队列上评估了 TrialGPT。TrialGPT-Retrieval 可以使用不到初始集合的 6%召回超过 90%的相关试验。对 1015 对患者标准对的手动评估表明,TrialGPT-Matching 以忠实的解释达到了 87.3%的准确性,接近专家表现。TrialGPT-Ranking 评分与人类判断高度相关,在排名和排除试验方面比最佳竞争模型高出 43.8%。此外,我们的用户研究表明,TrialGPT 可以将患者招募的筛选时间减少 42.6%。总的来说,这些结果表明,使用 TrialGPT 进行患者与试验匹配具有很大的潜力。