Fisher Hadar, Jaffe Nigel, Pidvirny Kristina, Tierney Anna, Pizzagalli Diego, Webb Christian
Harvard Medical School and McLean Hospital.
McLean Hospital.
Res Sq. 2025 Apr 17:rs.3.rs-6414400. doi: 10.21203/rs.3.rs-6414400/v1.
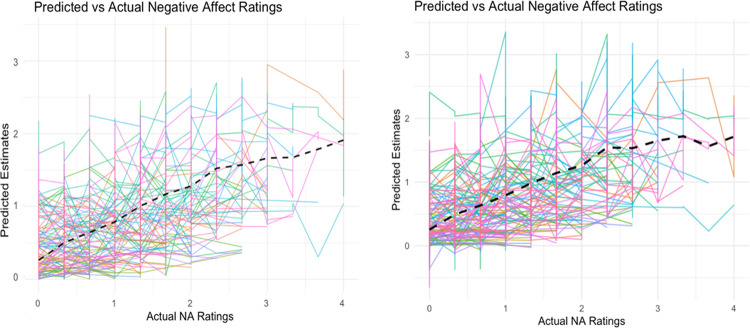
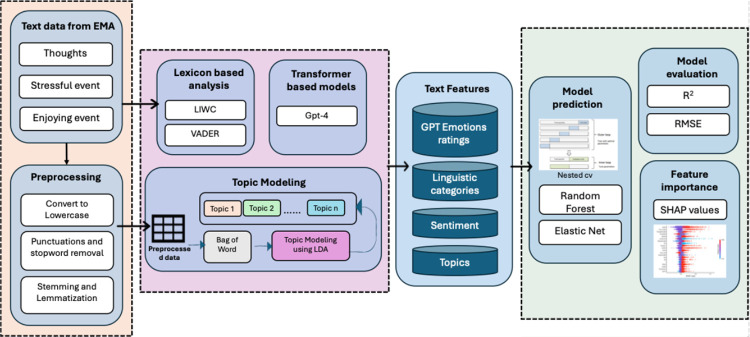
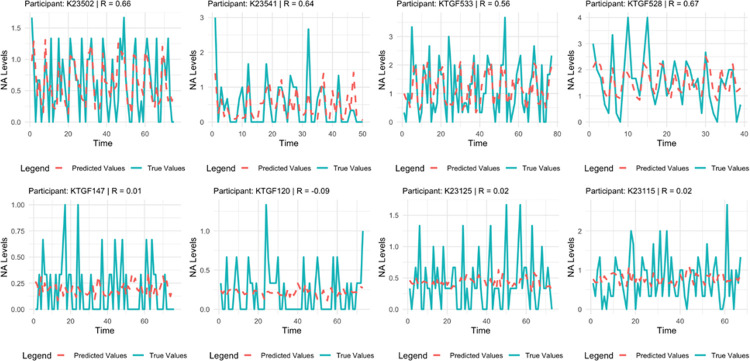
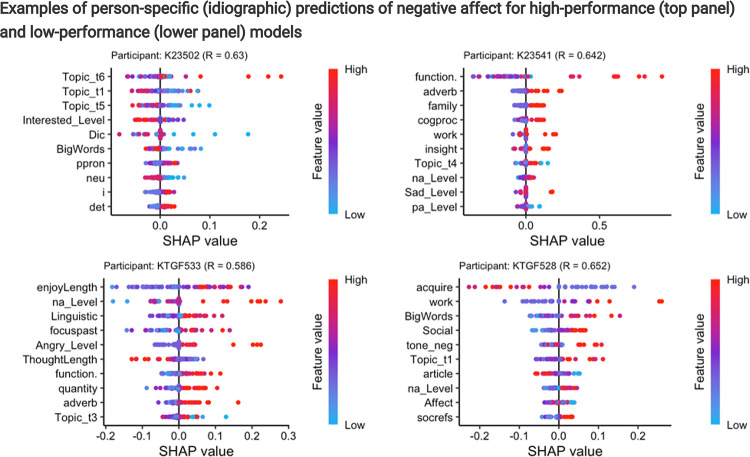
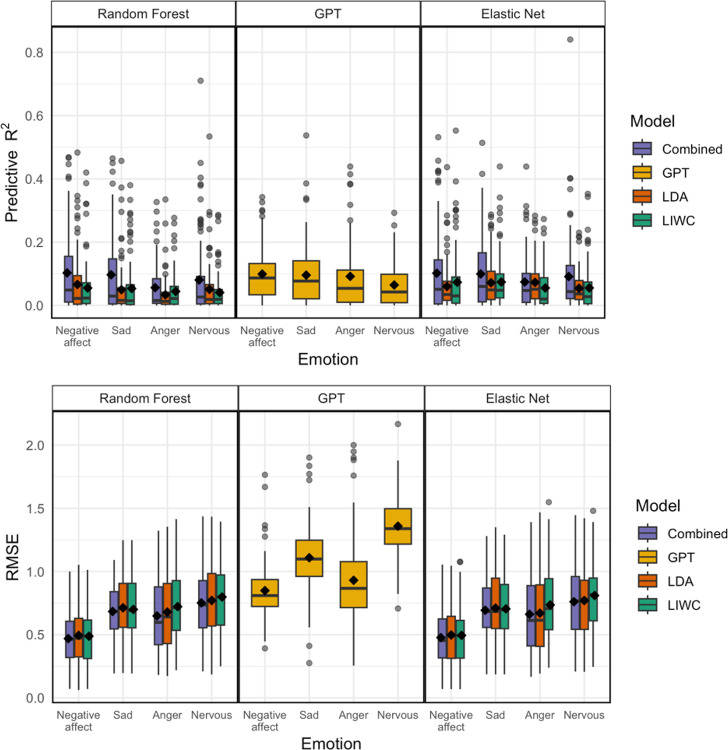
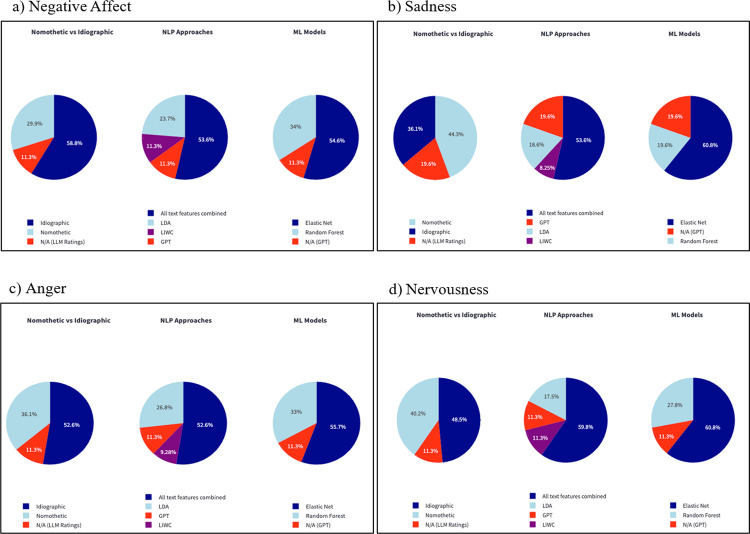
Tracking emotion fluctuations in adolescents' daily lives is essential for understanding mood dynamics and identifying early markers of affective disorders. This study examines the potential of text-based approaches for emotion prediction by comparing nomothetic (group-level) and idiographic (individualized) models in predicting adolescents' daily negative affect (NA) from text features. Additionally, we evaluate different Natural Language Processing (NLP) techniques for capturing within-person emotion fluctuations. We analyzed ecological momentary assessment (EMA) text responses from 97 adolescents (ages 14-18, 77.3% female, 22.7% male, N=7,680). Text features were extracted using a dictionary-based approach, topic modeling, and GPT-derived emotion ratings. Random Forest and Elastic Net Regression models predicted NA from these text features, comparing nomothetic and idiographic approaches. All key findings, interactive visualizations, and model comparisons are available via a companion web app: https://emotracknlp.streamlit.app/. Idiographic models combining text features from different NLP approaches exhibited the best performance: they performed comparably to nomothetic models in R but yielded lower prediction error (Root Mean Squared Error), improving within-person precision. Importantly, there were substantial between-person differences in model performance and predictive linguistic features. When selecting the best-performing model for each participant, significant correlations between predicted and observed emotion scores were found for 90.7-94.8% of participants. Our findings suggest that while nomothetic models offer initial scalability, idiographic models may provide greater predictive precision with sufficient within-person data. A flexible, personalized approach that selects the optimal model for each individual may enhance emotion monitoring, while leveraging text data to provide contextual insights that could inform appropriate interventions.
追踪青少年日常生活中的情绪波动对于理解情绪动态和识别情感障碍的早期标志物至关重要。本研究通过比较基于群体水平的(常模)和个性化的(自陈)模型从文本特征预测青少年日常消极情绪(NA)的能力,来检验基于文本的方法在情绪预测方面的潜力。此外,我们评估了不同的自然语言处理(NLP)技术来捕捉个体内部的情绪波动。我们分析了97名青少年(年龄14 - 18岁,77.3%为女性,22.7%为男性,N = 7680)的生态瞬时评估(EMA)文本回复。使用基于词典的方法、主题建模和GPT衍生的情绪评分来提取文本特征。随机森林和弹性网络回归模型从这些文本特征预测NA,比较常模和自陈方法。所有关键发现、交互式可视化以及模型比较都可通过配套的网络应用程序获取:https://emotracknlp.streamlit.app/。结合不同NLP方法的文本特征的自陈模型表现最佳:它们在R值上与常模模型相当,但预测误差(均方根误差)更低,提高了个体内部的预测精度。重要的是,模型性能和预测性语言特征在个体之间存在显著差异。当为每个参与者选择表现最佳的模型时,90.7 - 94.8%的参与者的预测情绪得分与观察到的情绪得分之间存在显著相关性。我们的研究结果表明,虽然常模模型具有初步的可扩展性,但自陈模型在有足够的个体内部数据时可能提供更高的预测精度。一种为每个个体选择最优模型的灵活、个性化方法可能会增强情绪监测,同时利用文本数据提供可用于指导适当干预的情境洞察力。