Friedman Joseph I, Parchure Prathamesh, Cheng Fu-Yuan, Fu Weijia, Cheertirala Satyanarayana, Timsina Prem, Raut Ganesh, Reina Katherine, Joseph-Jimerson Josiane, Mazumdar Madhu, Freeman Robert, Reich David L, Kia Arash
Department of Psychiatry, Icahn School of Medicine at Mount Sinai, New York, New York.
Department of Neuroscience, Icahn School of Medicine at Mount Sinai, New York, New York.
JAMA Netw Open. 2025 May 1;8(5):e258874. doi: 10.1001/jamanetworkopen.2025.8874.
Automating the identification of risk for developing hospital delirium with models that use machine learning (ML) could facilitate more rapid prevention, identification, and treatment of delirium. However, there are very few reports on the performance of ML models for delirium risk stratification in live clinical practice.
To report on development, operationalization, and validation of a multimodal ML model for delirium risk stratification in live clinical practice and its associations with workflow and clinical outcomes.
DESIGN, SETTING, AND PARTICIPANTS: This quality improvement study developed an ML model supported by automated electronic medical records to stratify the risk of non-intensive care unit delirium in live clinical practice using the Confusion Assessment Method as the diagnostic reference standard, with an iterative model update method. Data from patients aged at least 60 years admitted to non-intensive care units at Mount Sinai Hospital between January 2016 and January 2020 were used to train and test the ML model presented. The model was validated in live clinical practice from March 2023 to March 2024. Analysis of the model's associations with workflow and clinical outcomes was conducted retrospectively in 2024, comparing hospitalized patients prior to deployment of any model version (pre-ML cohort) and during model clinical deployment (post-ML cohort).
Outcomes of interest were area under the receiver operating characteristic curve, monthly delirium detection rates, median length of hospital stay, and daily doses of opiate, benzodiazepine, and antipsychotic medications administered.
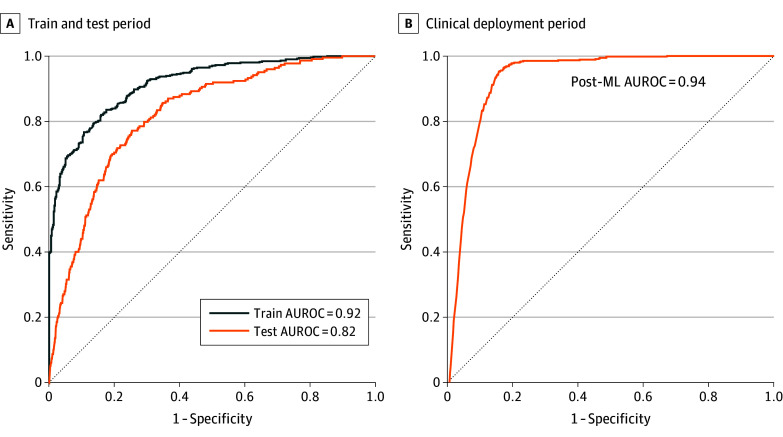
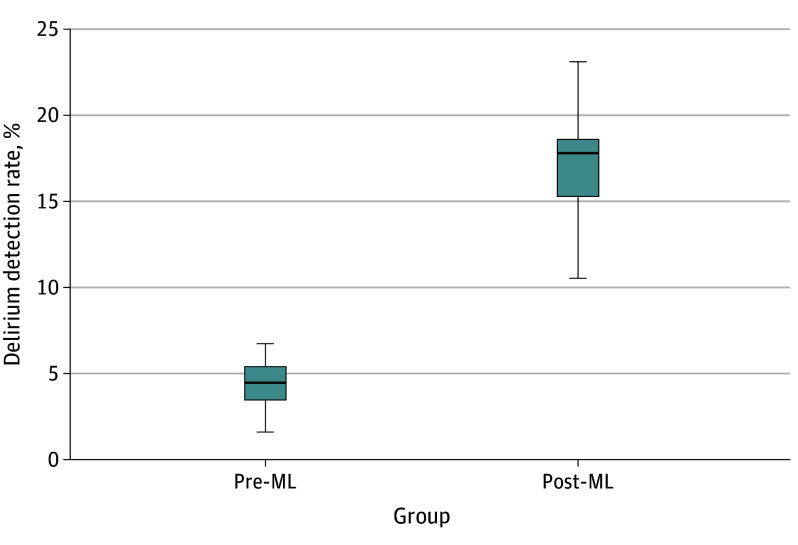
The overall sample included 32 284 inpatient admissions (mean [SD] age, 73.56 (9.67) years, 15 157 [46.9%] women). A total of 25 261 inpatient admissions of older patients with both medical and surgical primary diagnoses represented the combined model testing and training cohort (median age, 73.37 [66.42-81.36] years) and live clinical deployment validation cohort (median [IQR] age, 72.11 [62.26-78.97] years), while 7023 inpatient admissions of older patients with both medical and surgical primary diagnoses represented the combined pre-ML (median [IQR] age, 74.00 [68.00-81.00] years) and post-ML (median [IQR] age, 75.33 [68.34-82.91] years) cohorts. The model presented is a fusion of electronic medical record patient data features and clinical note features processed by natural language processing. The results of model validation in live clinical practice included an area under the curve of 0.94 (95% CI, 0.93-0.95). Median (IQR) monthly delirium detection rates of inpatients assessed for delirium with the Confusion Assessment Method increased from 4.42% (95% CI, 3.70%-5.14%) in the pre-ML cohort to 17.17% (95% CI, 15.54%-18.80%) in the post-ML cohort (P < .001). Post-ML vs pre-ML cohorts received lower daily doses of benzodiazepines (median [IQR] 0.93 [0.42-2.28] diazepam dose equivalents vs 1.60 [0.66-4.27] diazepam dose equivalents; P < .001) and olanzapine (median [IQR], 1.09 [0.38-2.46] mg vs 2.50 [1.17-6.65] mg; P < .001).
This quality improvement study demonstrates the feasibility of a novel multimodal ML model to automate delirium risk stratification in live clinical practice. The model demonstrated acceptable performance in live clinical practice and may facilitate resource allocation to enhance delirium identification and care.
利用机器学习(ML)模型自动识别医院谵妄发生风险,有助于更快速地预防、识别和治疗谵妄。然而,关于ML模型在实际临床实践中进行谵妄风险分层的性能报告非常少。
报告一种用于实际临床实践中谵妄风险分层的多模态ML模型的开发、实施和验证,及其与工作流程和临床结果的关联。
设计、设置和参与者:这项质量改进研究开发了一个由自动化电子病历支持的ML模型,以使用混乱评估方法作为诊断参考标准,在实际临床实践中对非重症监护病房谵妄风险进行分层,并采用迭代模型更新方法。使用2016年1月至2020年1月在西奈山医院非重症监护病房住院的至少60岁患者的数据来训练和测试所呈现的ML模型。该模型于2023年3月至2024年3月在实际临床实践中进行了验证。2024年对该模型与工作流程和临床结果的关联进行了回顾性分析,比较了在任何模型版本部署之前(ML前队列)和模型临床部署期间(ML后队列)的住院患者。
感兴趣的结果包括受试者操作特征曲线下面积、每月谵妄检测率、住院中位时长以及每日使用的阿片类、苯二氮䓬类和抗精神病药物剂量。
总体样本包括32284例住院患者(平均[标准差]年龄,73.56[9.67]岁,15157例[46.9%]为女性)。共有25261例患有内科和外科主要诊断的老年患者住院病例代表了联合模型测试和训练队列(中位年龄,73.37[66.42 - 81.36]岁)以及实际临床部署验证队列(中位[四分位间距]年龄,72.11[62.26 - 78.97]岁),而7023例患有内科和外科主要诊断的老年患者住院病例代表了联合ML前(中位[四分位间距]年龄,74.00[68.00 - 81.00]岁)和ML后(中位[四分位间距]年龄,75.33[68.34 - 82.91]岁)队列。所呈现的模型是电子病历患者数据特征与通过自然语言处理处理的临床笔记特征的融合。实际临床实践中的模型验证结果包括曲线下面积为0.94(95%CI,0.93 - 0.95)。使用混乱评估方法评估谵妄的住院患者的中位(四分位间距)每月谵妄检测率从ML前队列的4.42%(95%CI,3.70% - 5.14%)增加到ML后队列的17.17%(95%CI,15.54% - 18.80%)(P <.001)。与ML前队列相比,ML后队列接受的苯二氮䓬类药物每日剂量更低(中位[四分位间距]地西泮等效剂量0.93[0.42 - 2.28]对比1.60[0.66 - 4.27]地西泮等效剂量;P <.001)以及奥氮平(中位[四分位间距],1.09[0.38 - 2.46]mg对比2.50[1.17 - 6.65]mg;P <.001)。
这项质量改进研究证明了一种新型多模态ML模型在实际临床实践中自动进行谵妄风险分层的可行性。该模型在实际临床实践中表现出可接受的性能,并可能有助于资源分配以加强谵妄的识别和护理。