Leucuța Daniel-Corneliu, Urda-Cîmpean Andrada Elena, Istrate Dan, Drugan Tudor
Department of Medical Informatics and Biostatistics, Iuliu Hațieganu University of Medicine and Pharmacy, 400349 Cluj-Napoca, Romania.
Diagnostics (Basel). 2025 Jun 6;15(12):1451. doi: 10.3390/diagnostics15121451.
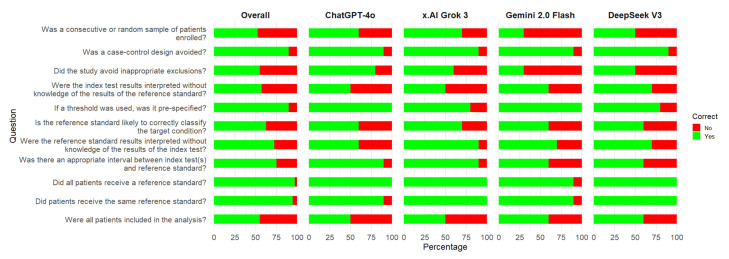
Diagnostic accuracy studies are essential for the evaluation of the performance of medical tests. The risk of bias (RoB) for these studies is commonly assessed using the Quality Assessment of Diagnostic Accuracy Studies (QUADAS) tool. This study aimed to assess the capabilities and reasoning accuracy of large language models (LLMs) in evaluating the RoB in diagnostic accuracy studies, using QUADAS 2, compared to human experts. : Four LLMs were used for the AI assessment: ChatGPT 4o model, X.AI Grok 3 model, Gemini 2.0 flash model, and DeepSeek V3 model. Ten recent open-access diagnostic accuracy studies were selected. Each article was independently assessed by human experts and by LLMs using QUADAS 2. : Out of 110 signaling questions assessments (11 questions for each of the 10 articles) by the four AI models, and the mean percentage of correct assessments of all the models was 72.95%. The most accurate model was Grok 3, followed by ChatGPT 4o, DeepSeek V3, and Gemini 2.0 Flash, with accuracies ranging from 74.45% to 67.27%. When analyzed by domain, the most accurate responses were for "flow and timing", followed by "index test", and then similarly for "patient selection" and "reference standard". An extensive list of reasoning errors was documented. : This study demonstrates that LLMs can achieve a moderate level of accuracy in evaluating the RoB in diagnostic accuracy studies. However, they are not yet a substitute for expert clinical and methodological judgment. LLMs may serve as complementary tools in systematic reviews, with compulsory human supervision.
诊断准确性研究对于评估医学检测的性能至关重要。这些研究的偏倚风险(RoB)通常使用诊断准确性研究质量评估(QUADAS)工具进行评估。本研究旨在评估大语言模型(LLMs)在使用QUADAS 2评估诊断准确性研究中的RoB时的能力和推理准确性,并与人类专家进行比较。使用了四个大语言模型进行人工智能评估:ChatGPT 4o模型、X.AI Grok 3模型、Gemini 2.0闪存模型和DeepSeek V3模型。选择了十项近期的开放获取诊断准确性研究。每篇文章由人类专家和大语言模型使用QUADAS 2独立评估。在四个人工智能模型对110个信号问题的评估中(10篇文章,每篇11个问题),所有模型正确评估的平均百分比为72.95%。最准确的模型是Grok 3,其次是ChatGPT 4o、DeepSeek V3和Gemini 2.0 Flash,准确率从74.45%到67.27%不等。按领域分析时,最准确的回答是关于“流程和时间”,其次是“索引测试”,然后“患者选择”和“参考标准”的情况类似。记录了大量的推理错误。这项研究表明,大语言模型在评估诊断准确性研究中的RoB时可以达到中等水平的准确性。然而,它们还不能替代专家的临床和方法学判断。大语言模型可以作为系统评价中的补充工具,但需要强制性的人工监督。