Sallam Malik, Alasfoor Israa M, Khalid Shahad W, Al-Mulla Rand I, Al-Farajat Amwaj, Mijwil Maad M, Zahrawi Reem, Sallam Mohammed, Egger Jan, Al-Adwan Ahmad S
Department of Pathology, Microbiology and Forensic Medicine, School of Medicine, The University of Jordan, Amman, Jordan.
Department of Clinical Laboratories and Forensic Medicine, Jordan University Hospital, Amman, Jordan.
Narra J. 2025 Apr;5(1):e2371. doi: 10.52225/narra.v5i1.2371. Epub 2025 Apr 8.
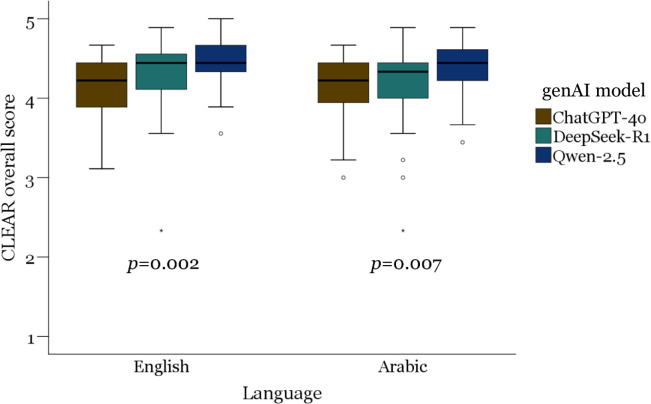
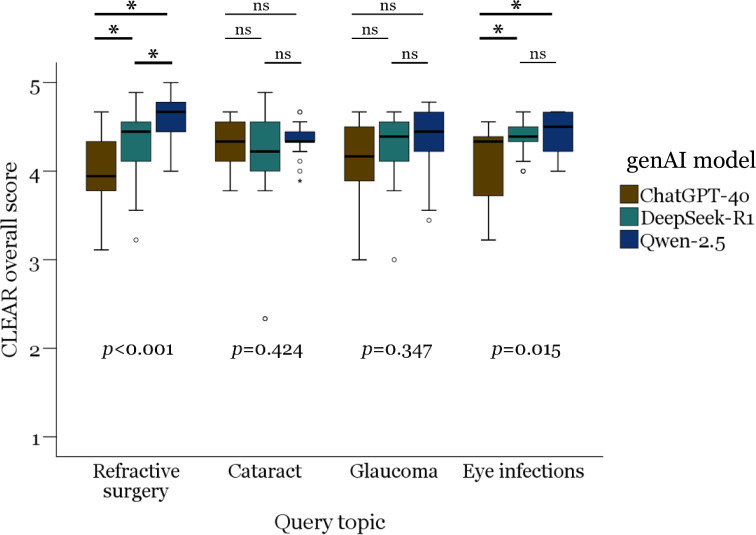
The rapid evolution of generative artificial intelligence (genAI) has ushered in a new era of digital medical consultations, with patients turning to AI-driven tools for guidance. The emergence of Chinese-developed genAI models such as DeepSeek-R1 and Qwen-2.5 presented a challenge to the dominance of OpenAI's ChatGPT. The aim of this study was to benchmark the performance of Chinese genAI models against ChatGPT-40 and to assess disparities in performance across English and Arabic. Following the METRICS checklist for genAI evaluation, Qwen-2.5, DeepSeek-R1, and ChatGPT-40 were assessed for completeness, accuracy, and relevance using the CLEAR tool in common patient ophthalmology queries. In English, Qwen-2.5 demonstrated the highest overall performance (CLEAR score: 4.43 ± 0.28), outperforming both DeepSeek-R1 (4.3 ± 0.43) and ChatGPT-40 (4.14 ± 0.41), with = 0.002. A similar hierarchy emerged in Arabic, with Qwen-2.5 again leading (4.40 ± 0.29), followed by DeepSeek-R1 (4.20 ± 0.49) and ChatGPT-40 (4.14 ± 0.41), with = 0.007. Each tested genAI model exhibited near-identical performance across the two languages, with ChatGPT-40 demonstrating the most balanced linguistic capabilities ( = 0.957), while Qwen-2.5 and DeepSeek-R1 showed a marginal superiority for English. An in-depth examination of genAI performance across key CLEAR components revealed that Qwen-2.5 consistently excelled in content completeness, factual accuracy, and relevance in both English and Arabic, setting a new benchmark for genAI in medical inquiries. Despite minor linguistic disparities, all three models exhibited robust multilingual capabilities, challenging the long-held assumption that genAI is inherently biased toward English. These findings highlight the evolving nature of AI-driven medical assistance, with Chinese genAI models being able to rival or even surpass ChatGPT-40 in ophthalmology-related queries.
生成式人工智能(genAI)的快速发展开启了数字医疗咨询的新时代,患者开始借助人工智能驱动的工具获取指导。像DeepSeek-R1和Qwen-2.5等中国研发的genAI模型的出现,对OpenAI的ChatGPT的主导地位构成了挑战。本研究的目的是将中国genAI模型的性能与ChatGPT-40进行基准测试,并评估英语和阿拉伯语在性能上的差异。按照genAI评估的METRICS清单,使用CLEAR工具在常见的患者眼科问题中对Qwen-2.5、DeepSeek-R1和ChatGPT-40进行完整性、准确性和相关性评估。在英语方面,Qwen-2.5展现出最高的总体性能(CLEAR分数:4.43±0.28),优于DeepSeek-R1(4.3±0.43)和ChatGPT-40(4.14±0.41),P = 0.002。在阿拉伯语中也出现了类似的排名,Qwen-2.5再次领先(4.40±0.29),其次是DeepSeek-R1(4.20±0.49)和ChatGPT-40(4.14±0.41),P = 0.007。每个测试的genAI模型在两种语言中的表现几乎相同,ChatGPT-40展现出最平衡的语言能力(P = 0.957),而Qwen-2.5和DeepSeek-R1在英语方面表现出微弱优势。对genAI在关键CLEAR组件上的性能进行深入研究发现,Qwen-2.5在英语和阿拉伯语的内容完整性、事实准确性和相关性方面始终表现出色,为医疗咨询中的genAI设定了新的基准。尽管存在微小的语言差异,但所有三个模型都展现出强大的多语言能力,挑战了长期以来认为genAI天生偏向英语的假设。这些发现凸显了人工智能驱动的医疗辅助的不断发展,中国genAI模型在眼科相关问题上能够与ChatGPT-40竞争甚至超越它。