Newton Philip M, Summers Christopher J, Zaheer Uzman, Xiromeriti Maira, Stokes Jemima R, Bhangu Jaskaran Singh, Roome Elis G, Roberts-Phillips Alanna, Mazaheri-Asadi Darius, Jones Cameron D, Hughes Stuart, Gilbert Dominic, Jones Ewan, Essex Keioni, Ellis Emily C, Davey Ross, Cox Adrienne A, Bassett Jessica A
Swansea University Medical School, Swansea, Wales, SA2 8PP UK.
Med Sci Educ. 2025 Feb 4;35(2):721-729. doi: 10.1007/s40670-025-02293-z. eCollection 2025 Apr.
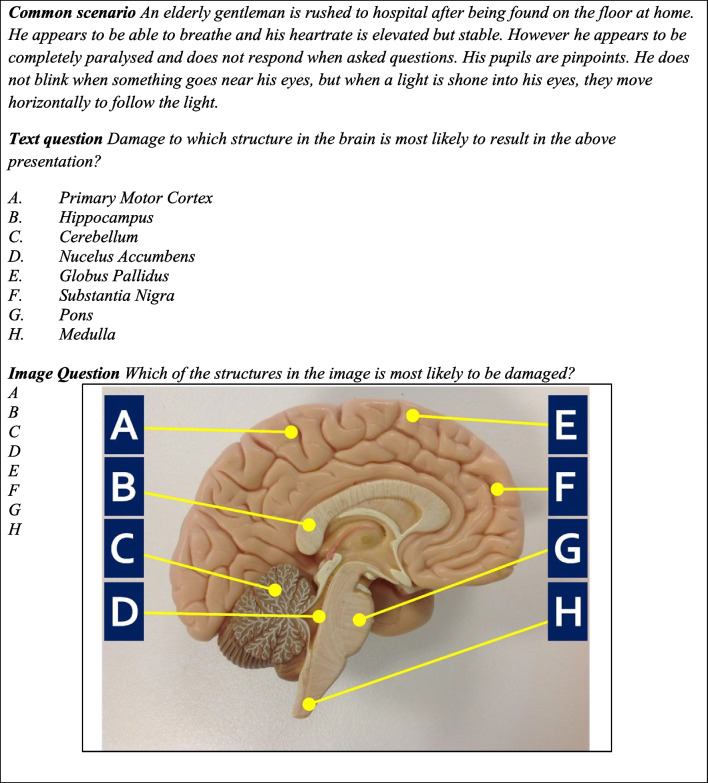
ChatGPT apparently shows excellent performance on high-level professional exams such as those involved in medical assessment and licensing. This has raised concerns that ChatGPT could be used for academic misconduct, especially in unproctored online exams. However, ChatGPT has previously shown weaker performance on questions with pictures, and there have been concerns that ChatGPT's performance may be artificially inflated by the public nature of the sample questions tested, meaning they likely formed part of the training materials for ChatGPT. This led to suggestions that cheating could be mitigated by using novel questions for every sitting of an exam and making extensive use of picture-based questions. These approaches remain untested. Here, we tested the performance of ChatGPT-4o on existing medical licensing exams in the UK and USA, and on novel questions based on those exams. ChatGPT-4o scored 94% on the United Kingdom Medical Licensing Exam Applied Knowledge Test and 89.9% on the United States Medical Licensing Exam Step 1. Performance was not diminished when the questions were rewritten into novel versions, or on completely novel questions which were not based on any existing questions. ChatGPT did show reduced performance on questions containing images when the answer options were added to an image as text labels. These data demonstrate that the performance of ChatGPT continues to improve and that secure testing environments are required for the valid assessment of both foundational and higher order learning.
The online version contains supplementary material available at 10.1007/s40670-025-02293-z.
ChatGPT在诸如医学评估和执照考试等高级专业考试中表现出卓越的成绩。这引发了人们对ChatGPT可能被用于学术不端行为的担忧,尤其是在无监考的在线考试中。然而,ChatGPT此前在带有图片的问题上表现较弱,并且有人担心ChatGPT的成绩可能因所测试的样本题目的公开性质而被人为抬高,这意味着这些题目可能是ChatGPT训练材料的一部分。这导致有人建议,通过每次考试使用新颖的题目并大量使用基于图片的题目,可以减轻作弊现象。这些方法尚未经过测试。在此,我们测试了ChatGPT-4o在英国和美国现有医学执照考试以及基于这些考试的新颖题目上的表现。ChatGPT-4o在英国医学执照考试应用知识测试中得分为94%,在美国医学执照考试第一步中得分为89.9%。当题目被改写为新颖版本时,或者在完全不基于任何现有题目的新颖题目上,其表现并未降低。当答案选项以文本标签的形式添加到图片中时,ChatGPT在包含图片的题目上确实表现出成绩下降。这些数据表明ChatGPT的性能在持续提高,并且需要安全的测试环境来有效评估基础学习和高阶学习。
在线版本包含可在10.1007/s40670-025-02293-z获取的补充材料。