Seo Jean, Park Sumin, Byun Sungjoo, Choi Jinwook, Choi Jinho, Shin Hyopil
Department of Linguistics, Seoul National University, Seoul, Korea.
College of Humanities, Seoul National University, Seoul, Korea.
Healthc Inform Res. 2025 Apr;31(2):166-174. doi: 10.4258/hir.2025.31.2.166. Epub 2025 Apr 30.
Developing large language models (LLMs) in biomedicine requires access to high-quality training and alignment tuning datasets. However, publicly available Korean medical preference datasets are scarce, hindering the advancement of Korean medical LLMs. This study constructs and evaluates the efficacy of the Korean Medical Preference Dataset (KoMeP), an alignment tuning dataset constructed with an automated pipeline, minimizing the high costs of human annotation.
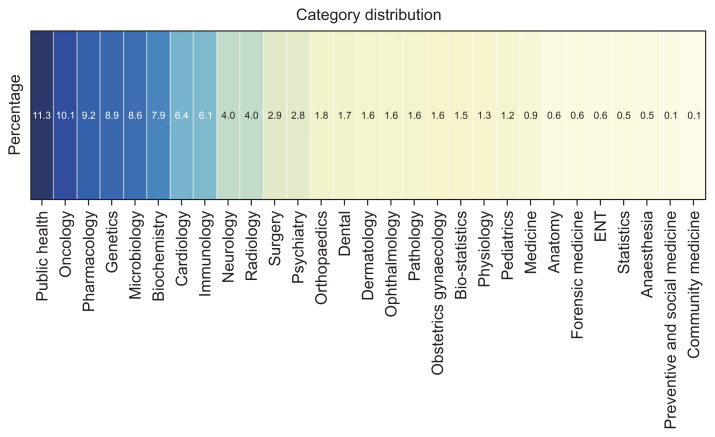
KoMeP was generated using the DAHL score, an automated hallucination evaluation metric. Five LLMs (Dolly-v2-3B, MPT-7B, GPT-4o, Qwen-2-7B, Llama-3-8B) produced responses to 8,573 biomedical examination questions, from which 5,551 preference pairs were extracted. Each pair consisted of a "chosen" response and a "rejected" response, as determined by their DAHL scores. The dataset was evaluated when trained through two different alignment tuning methods, direct preference optimization (DPO) and odds ratio preference optimization (ORPO) respectively across five different models. The KorMedMCQA benchmark was employed to assess the effectiveness of alignment tuning.
Models trained with DPO consistently improved KorMedMCQA performance; notably, Llama-3.1-8B showed a 43.96% increase. In contrast, ORPO training produced inconsistent results. Additionally, English-to-Korean transfer learning proved effective, particularly for English-centric models like Gemma-2, whereas Korean-to-English transfer learning achieved limited success. Instruction tuning with KoMeP yielded mixed outcomes, which suggests challenges in dataset formatting.
KoMeP is the first publicly available Korean medical preference dataset and significantly improves alignment tuning performance in LLMs. The DPO method outperforms ORPO in alignment tuning. Future work should focus on expanding KoMeP, developing a Korean-native dataset, and refining alignment tuning methods to produce safer and more reliable Korean medical LLMs.
在生物医学领域开发大语言模型(LLMs)需要高质量的训练和对齐微调数据集。然而,公开可用的韩语医学偏好数据集稀缺,阻碍了韩语医学大语言模型的发展。本研究构建并评估了韩语医学偏好数据集(KoMeP)的有效性,这是一个使用自动化管道构建的对齐微调数据集,将人工标注的高成本降至最低。
KoMeP是使用DAHL分数生成的,这是一种自动幻觉评估指标。五个大语言模型(Dolly-v2-3B、MPT-7B、GPT-4o、Qwen-2-7B、Llama-3-8B)对8573个生物医学考试问题给出了回答,从中提取了5551个偏好对。每对由一个“选择的”回答和一个“拒绝的”回答组成,这是由它们的DAHL分数决定的。当通过两种不同的对齐微调方法(直接偏好优化(DPO)和优势比偏好优化(ORPO))分别在五个不同模型上进行训练时,对该数据集进行了评估。使用KorMedMCQA基准来评估对齐微调的有效性。
使用DPO训练的模型始终提高了KorMedMCQA的性能;值得注意的是,Llama-3.1-8B显示出43.96%的增长。相比之下,ORPO训练产生了不一致的结果。此外,英语到韩语的迁移学习被证明是有效的,特别是对于像Gemma-2这样以英语为中心的模型,而韩语到英语的迁移学习取得的成功有限。使用KoMeP进行指令微调产生了好坏参半的结果,这表明在数据集格式化方面存在挑战。
KoMeP是第一个公开可用的韩语医学偏好数据集,并显著提高了大语言模型中的对齐微调性能。在对齐微调方面,DPO方法优于ORPO。未来的工作应集中在扩展KoMeP、开发韩语原生数据集以及改进对齐微调方法,以生产更安全、更可靠的韩语医学大语言模型。