Xie Qianqian, Chen Qingyu, Chen Aokun, Peng Cheng, Hu Yan, Lin Fongci, Peng Xueqing, Huang Jimin, Zhang Jeffrey, Keloth Vipina, Zhou Xinyu, Qian Lingfei, He Huan, Shung Dennis, Ohno-Machado Lucila, Wu Yonghui, Xu Hua, Bian Jiang
Yale University.
University of Florida.
Res Sq. 2024 Dec 18:rs.3.rs-5456223. doi: 10.21203/rs.3.rs-5456223/v1.
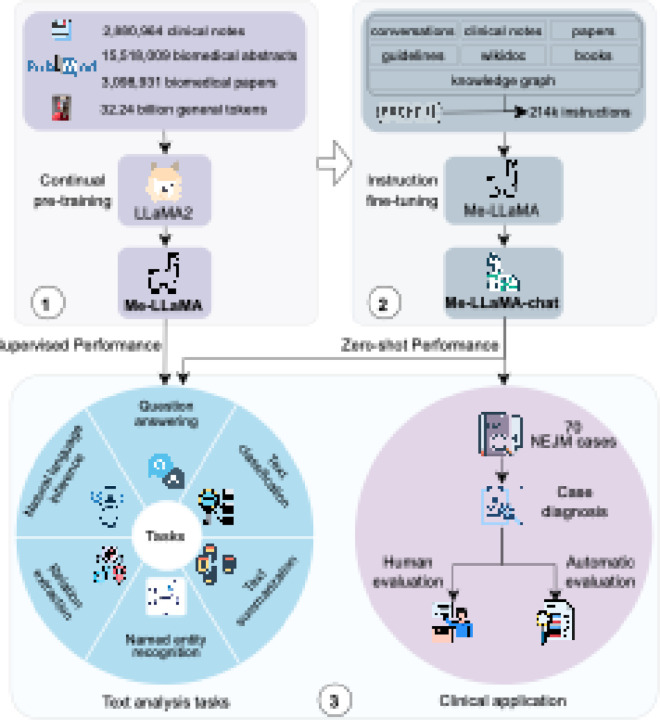
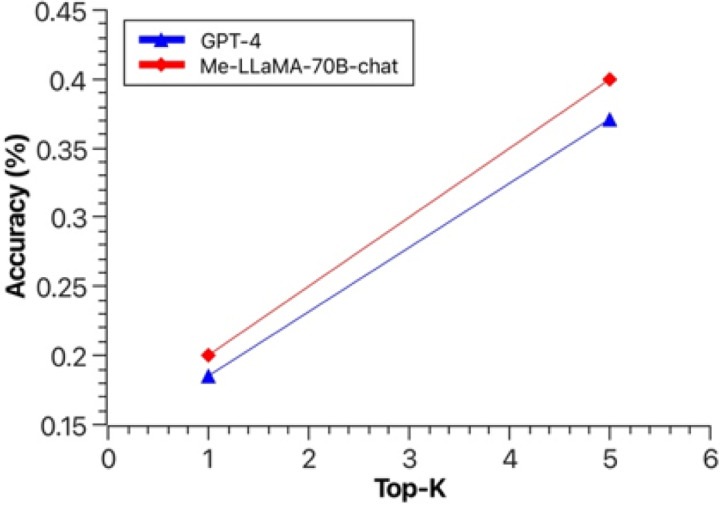
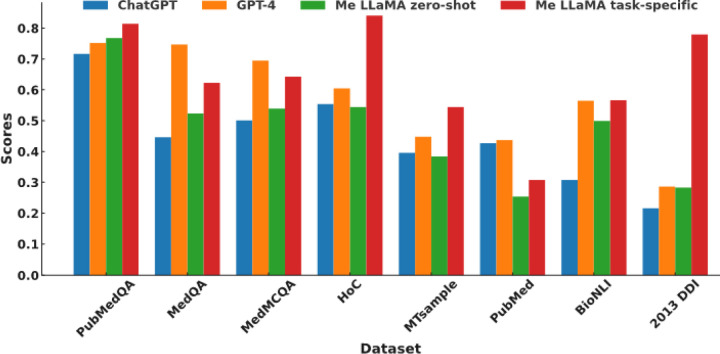
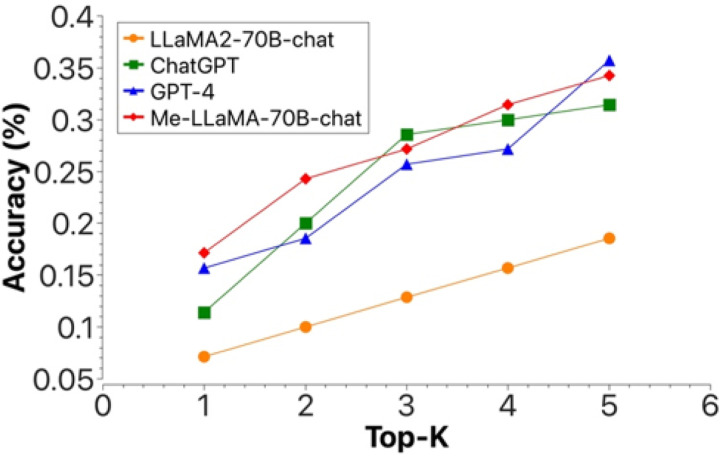
Recent advancements in large language models (LLMs) like ChatGPT and LLaMA have shown significant potential in medical applications, but their effectiveness is limited by a lack of specialized medical knowledge due to general-domain training. In this study, we developed Me-LLaMA, a new family of open-source medical LLMs that uniquely integrate extensive domain-specific knowledge with robust instruction-following capabilities. Me-LLaMA comprises foundation models (Me-LLaMA 13B and 70B) and their chat-enhanced versions, developed through comprehensive continual pretraining and instruction tuning of LLaMA2 models using both biomedical literature and clinical notes. Me-LLaMA utilized the largest and most comprehensive medical data, including 129B pre-training tokens and 214K instruction tuning samples from diverse biomedical and clinical data sources. Training the 70B models required substantial computational resources, exceeding 100,000 A100 GPU hours. We applied Me-LLaMA to six medical text analysis tasks and evaluated its performance on 12 benchmark datasets. To further assess Me-LLaMA's potential clinical utility, we evaluated its performance on complex clinical case diagnosis compared with other commercial LLMs, using both automatic and human evaluations. Me-LLaMA models outperform LLaMA, and other existing open-source medical LLMs in both zero-shot and supervised learning settings for most text analysis tasks. With task-specific instruction tuning, Me-LLaMA models also surpass leading commercial LLMs, outperforming ChatGPT on 7 out of 8 datasets and GPT-4 on 5 out of 8 datasets. Moreover, Me-LLaMA's performance is comparable to ChatGPT and GPT-4 for diagnosing complex clinical cases. Our findings underscore combining domain-specific continual pretraining with instruction tuning is essential for developing effective domain-specific large language models in healthcare, significantly enhancing performance across diverse medical text analysis tasks and applications. By publicly releasing our models and resources under appropriate user agreements, we aim to foster innovation and facilitate advancements in medical AI, benefiting researchers and practitioners within the community.
像ChatGPT和LLaMA这样的大语言模型(LLMs)最近取得的进展在医学应用中显示出了巨大潜力,但由于其通用领域训练导致缺乏专业医学知识,其有效性受到限制。在本研究中,我们开发了Me-LLaMA,这是一个新的开源医学大语言模型家族,它独特地将广泛的特定领域知识与强大的指令跟随能力相结合。Me-LLaMA包括基础模型(Me-LLaMA 13B和70B)及其聊天增强版本,通过使用生物医学文献和临床笔记对LLaMA2模型进行全面的持续预训练和指令微调而开发。Me-LLaMA利用了最大且最全面的医学数据,包括来自不同生物医学和临床数据源的129B预训练令牌和214K指令微调样本。训练70B模型需要大量计算资源,超过100,000个A100 GPU小时。我们将Me-LLaMA应用于六个医学文本分析任务,并在12个基准数据集上评估其性能。为了进一步评估Me-LLaMA的潜在临床效用,我们使用自动和人工评估,将其在复杂临床病例诊断中的性能与其他商业大语言模型进行了比较。在大多数文本分析任务的零样本和监督学习设置中,Me-LLaMA模型优于LLaMA和其他现有的开源医学大语言模型。通过特定任务的指令微调,Me-LLaMA模型也超越了领先的商业大语言模型,在8个数据集中的7个上优于ChatGPT,在8个数据集中的5个上优于GPT-4。此外,Me-LLaMA在诊断复杂临床病例方面的性能与ChatGPT和GPT-4相当。我们的研究结果强调,将特定领域的持续预训练与指令微调相结合对于在医疗保健领域开发有效的特定领域大语言模型至关重要,可显著提高在各种医学文本分析任务和应用中的性能。通过在适当的用户协议下公开发布我们的模型和资源,我们旨在促进医学人工智能的创新和发展,使社区内的研究人员和从业者受益。