Marchesi Raffaele, Micheletti Nicolo, I-Hsien Kuo Nicholas, Barbieri Sebastiano, Jurman Giuseppe, Osmani Venet
Data Science for Health (DSH), Fondazione Bruno Kessler, Trento, Italy.
Department of Mathematics, University of Pavia, Pavia, Italy.
PLoS Comput Biol. 2025 May 19;21(5):e1013080. doi: 10.1371/journal.pcbi.1013080. eCollection 2025 May.
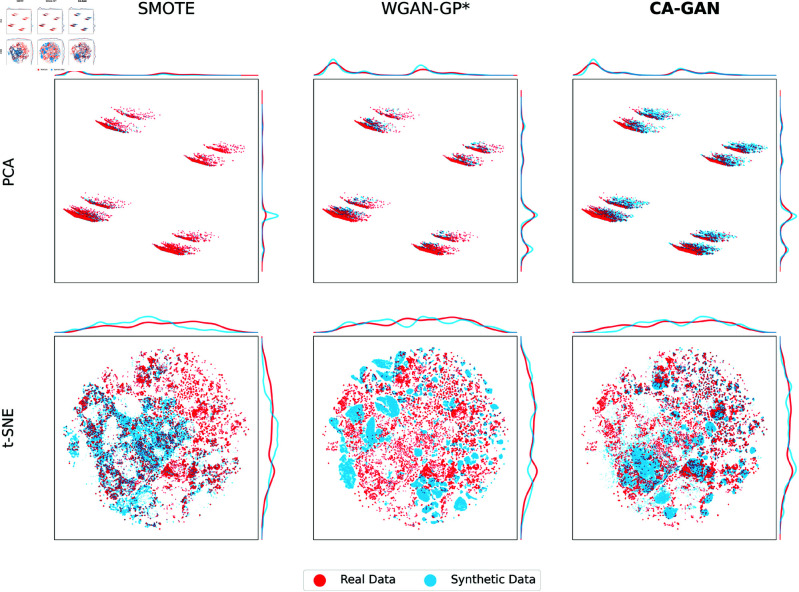
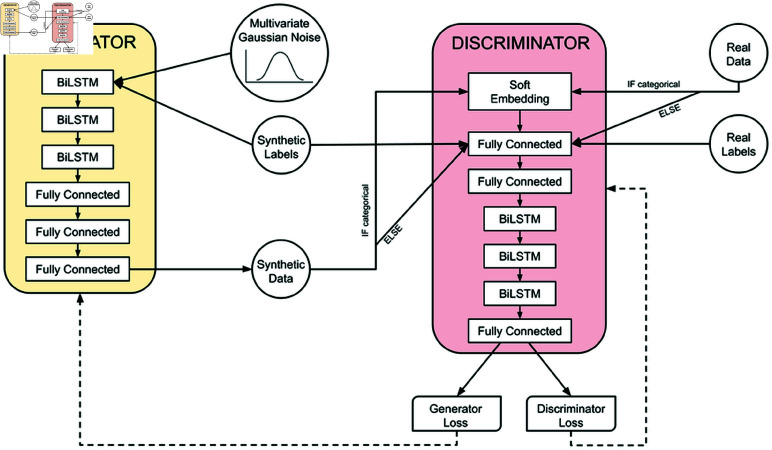
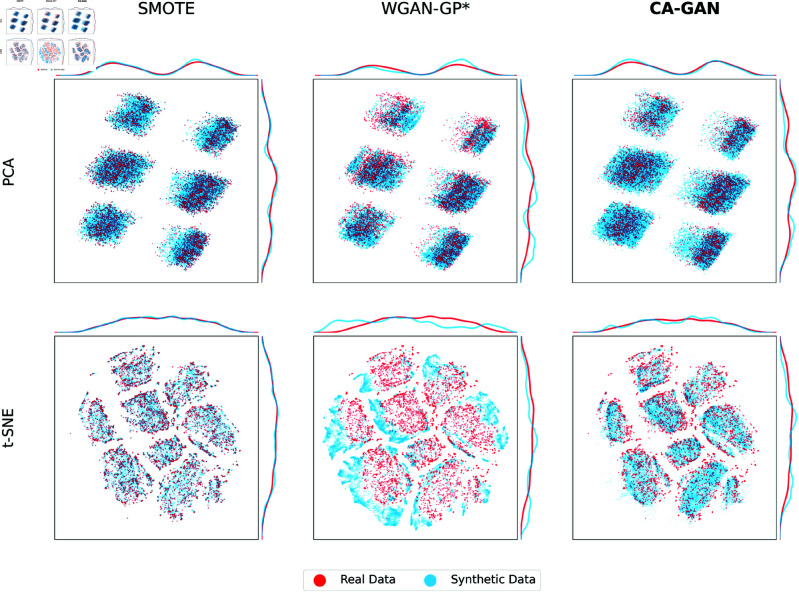
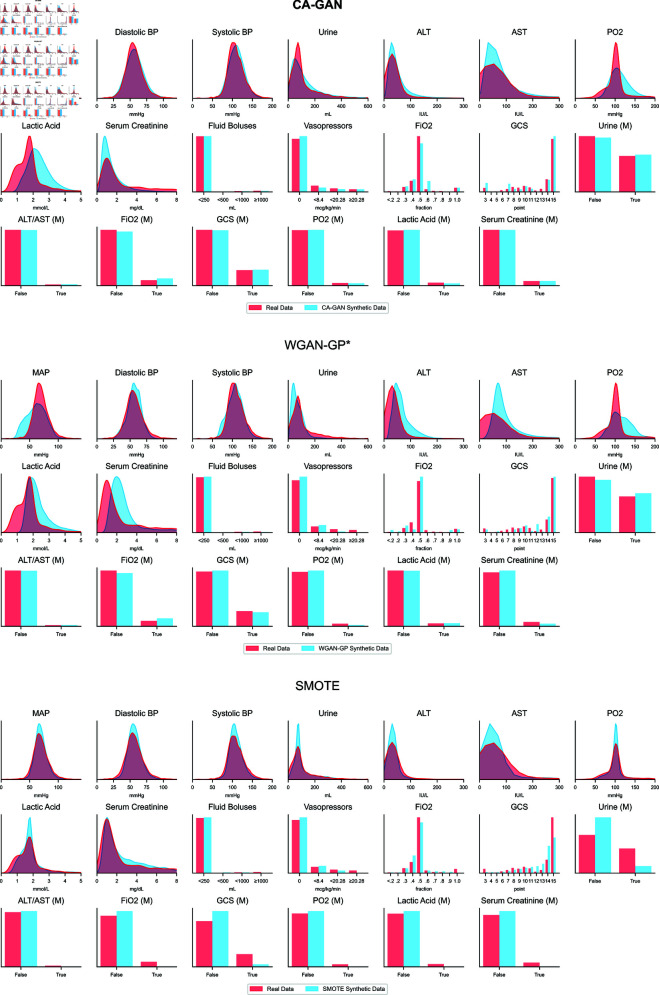
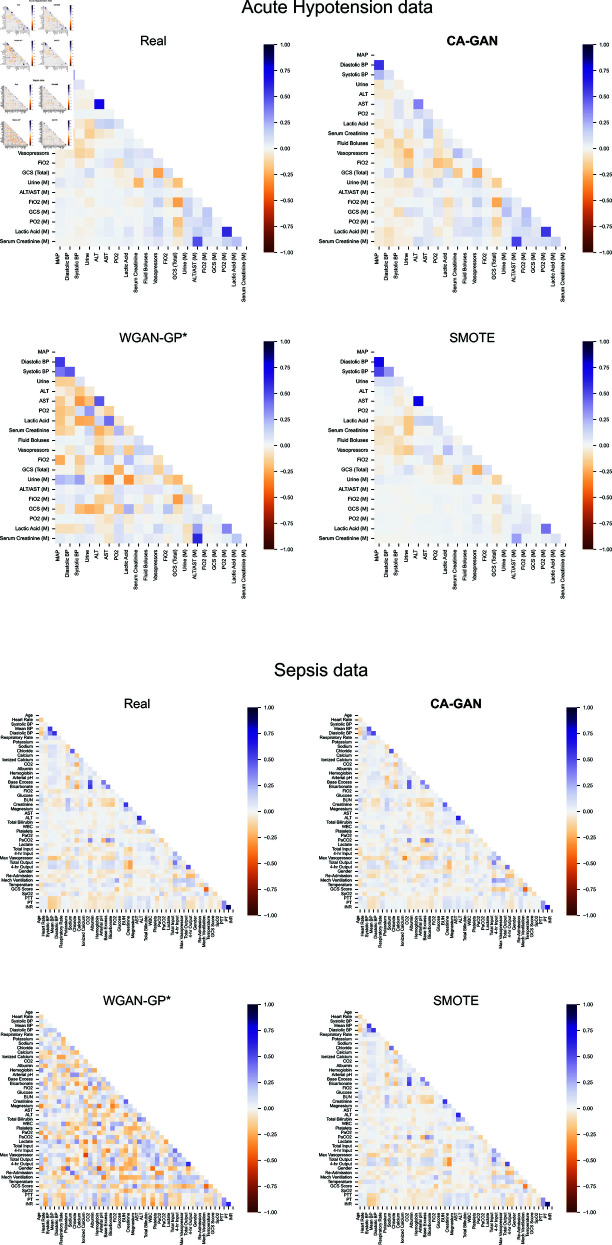
Representation bias in health data can lead to unfair decisions and compromise the generalisability of research findings. As a consequence, underrepresented subpopulations, such as those from specific ethnic backgrounds or genders, do not benefit equally from clinical discoveries. Several approaches have been developed to mitigate representation bias, ranging from simple resampling methods, such as SMOTE, to recent approaches based on generative adversarial networks (GAN). However, generating high-dimensional time-series synthetic health data remains a significant challenge. In response, we devised a novel architecture (CA-GAN) that synthesises authentic, high-dimensional time series data. CA-GAN outperforms state-of-the-art methods in a qualitative and a quantitative evaluation while avoiding mode collapse, a serious GAN failure. We perform evaluation using 7535 patients with hypotension and sepsis from two diverse, real-world clinical datasets. We show that synthetic data generated by our CA-GAN improves model fairness in Black patients as well as female patients when evaluated separately for each subpopulation. Furthermore, CA-GAN generates authentic data of the minority class while faithfully maintaining the original distribution of data, resulting in improved performance in a downstream predictive task.
健康数据中的代表性偏差可能导致不公平的决策,并损害研究结果的普遍性。因此,代表性不足的亚群体,如来自特定种族背景或性别的群体,无法平等地从临床发现中受益。已经开发了几种方法来减轻代表性偏差,从简单的重采样方法,如SMOTE,到基于生成对抗网络(GAN)的最新方法。然而,生成高维时间序列合成健康数据仍然是一项重大挑战。作为回应,我们设计了一种新颖的架构(CA-GAN),用于合成真实的高维时间序列数据。在定性和定量评估中,CA-GAN优于现有方法,同时避免了模式崩溃,这是GAN的一个严重故障。我们使用来自两个不同的真实世界临床数据集的7535名低血压和脓毒症患者进行评估。我们表明,当对每个亚群体分别进行评估时,我们的CA-GAN生成的合成数据提高了黑人患者和女性患者的模型公平性。此外,CA-GAN生成少数群体类别的真实数据,同时忠实地保持数据的原始分布,从而在下游预测任务中提高性能。