Endebu Tamrat, Taye Girma, Deressa Wakgari
Department of Epidemiology and Biostatistics, School of Public Health, College of Health Sciences, Addis Ababa University, Addis Ababa, Ethiopia.
BMC Med Inform Decis Mak. 2025 May 19;25(1):192. doi: 10.1186/s12911-025-03030-7.
Despite the global commitment to ending AIDS by 2030, the loss of follow-up (LTFU) in HIV care remains a significant challenge. To address this issue, a data-driven clinical decision tool is crucial for identifying patients at greater risk of LTFU and facilitating personalized and proactive interventions. This study aimed to develop a prediction model to assess the future risk of LTFU in HIV care in Ethiopia.
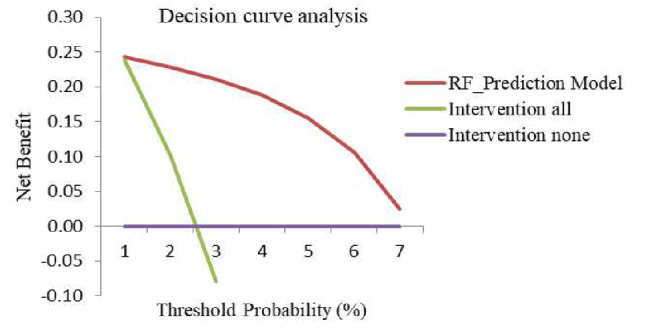
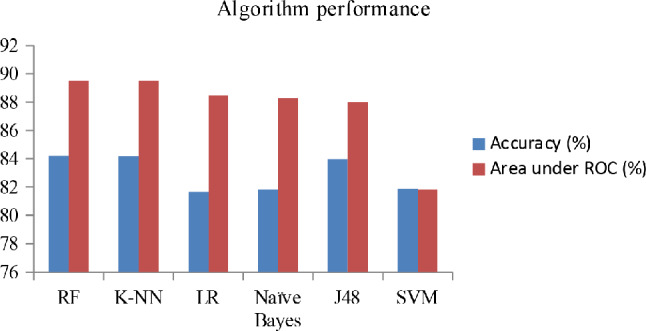
The study used a retrospective design in which machine learning (ML) methods were applied to the electronic medical records (EMRs) data of adult HIV-positive individuals who were newly enrolled in antiretroviral therapy between July 2019 and April 2024. The data were collected across eight randomly selected high-volume healthcare facilities. Six supervised ML classifiers-J48 decision tree, random forest, K-nearest neighbors, support vector machine, logistic regression, and naïve Bayes-were utilized for training via Weka 3.8.6 software. The performance of each algorithm was evaluated through a 10-fold cross-validation approach. Algorithm performance was compared via the corrected resampled t test (p < 0.05), and decision curve analysis (DCA) was used to assess the model's clinical utility.
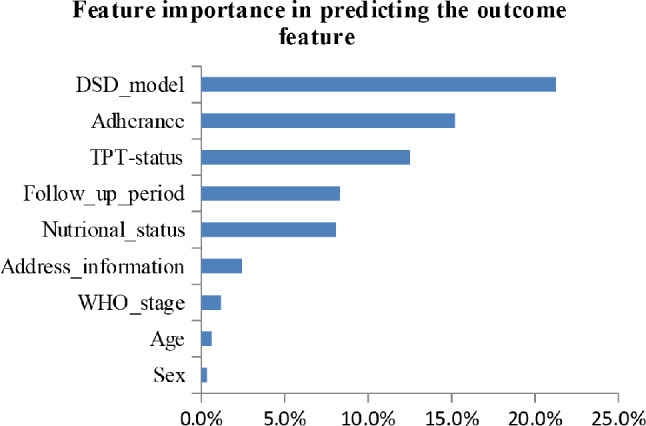
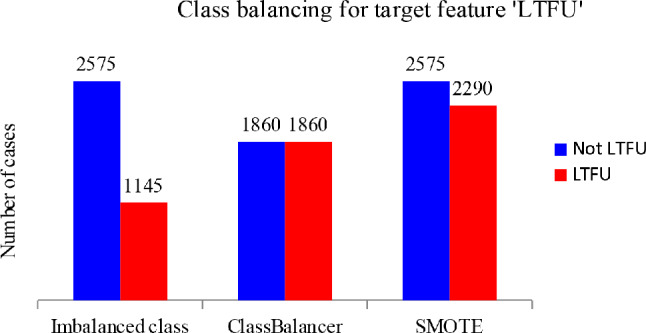
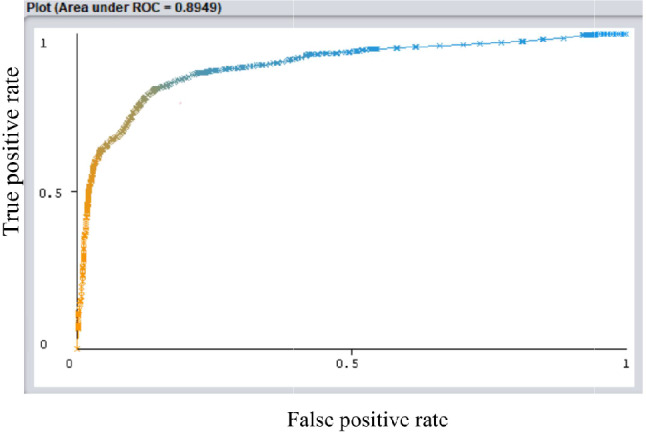
A total of 3,720 individuals' EMR data were analyzed, with 2,575 (69.2%) classified as not LTFU and 1,145 (30.8%) classified as LTFU. On the basis of the ML feature selection process, six strong predictors of LTFU were identified: differentiated service delivery model, adherence, tuberculosis preventive therapy, follow-up period, nutritional status, and address information. The random forest algorithm showed superior performance, with an accuracy of 84.2%, a sensitivity of 82.4%, a specificity of 85.7%, a precision of 83.7%, an F1 score of 83.1%, and an area under the curve of 89.5%. The model demonstrated greater clinical utility, offering greater net benefit than both the 'intervention for all' approach and the 'intervention for none' approach, particularly at threshold probabilities of 10% and above.
This study developed a machine learning-based predictive model for assessing the future risk of LTFU in HIV care within low-resource settings. Notably, the model built via the random forest algorithm exhibited high accuracy and strong discriminative performance, highlighting its positive net benefit for clinical applications. Furthermore, ongoing external validation across diverse populations is important to ensure the model's reliability and generalizability.
尽管全球致力于到2030年终结艾滋病,但艾滋病毒护理中的失访问题仍是一项重大挑战。为解决这一问题,数据驱动的临床决策工具对于识别失访风险较高的患者并促进个性化和积极主动的干预措施至关重要。本研究旨在开发一种预测模型,以评估埃塞俄比亚艾滋病毒护理中未来失访的风险。
该研究采用回顾性设计,将机器学习方法应用于2019年7月至2024年4月新开始接受抗逆转录病毒治疗的成年艾滋病毒阳性个体的电子病历数据。数据是在八个随机选择的高流量医疗机构收集的。使用六种监督式机器学习分类器——J48决策树、随机森林、K近邻、支持向量机、逻辑回归和朴素贝叶斯——通过Weka 3.8.6软件进行训练。每种算法的性能通过10折交叉验证方法进行评估。通过校正重采样t检验(p < 0.05)比较算法性能,并使用决策曲线分析(DCA)评估模型的临床效用。
共分析了3720个人的电子病历数据,其中2575人(69.2%)被归类为未失访,1145人(30.8%)被归类为失访。基于机器学习特征选择过程,确定了六个失访的强预测因素:差异化服务提供模式、依从性、结核病预防性治疗、随访期、营养状况和地址信息。随机森林算法表现出卓越的性能,准确率为84.2%,灵敏度为82.4%,特异性为85.7%,精确率为83.7%,F1分数为83.1%,曲线下面积为89.5%。该模型显示出更大的临床效用,与“全员干预”方法和“无干预”方法相比,都提供了更大的净效益,特别是在阈值概率为10%及以上时。
本研究开发了一种基于机器学习的预测模型,用于评估资源匮乏环境下艾滋病毒护理中未来失访的风险。值得注意的是,通过随机森林算法构建的模型表现出高准确率和强大的判别性能,突出了其在临床应用中的积极净效益。此外,对不同人群进行持续的外部验证对于确保模型的可靠性和通用性很重要。