Turki Deema F, Turki Ahmad F
Speech and Hearing Pathology Department, Faculty of Medical Rehabilitation Sciences, King Abdulaziz University, Jeddah 21589, Saudi Arabia.
Electrical and Computer Engineering Department, Faculty of Engineering, King Abdulaziz University, Jeddah 21589, Saudi Arabia.
Diagnostics (Basel). 2025 May 31;15(11):1401. doi: 10.3390/diagnostics15111401.
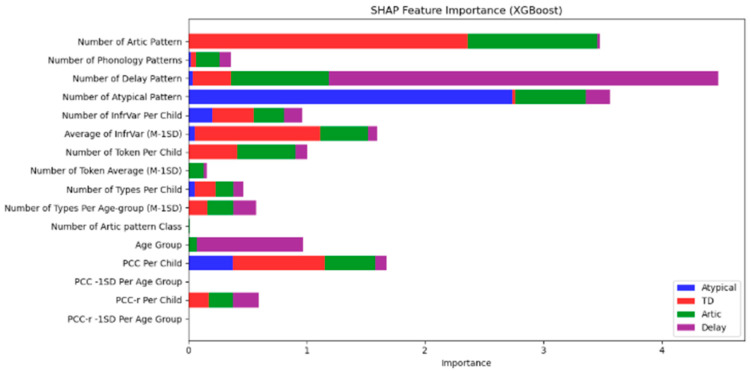
This study investigates the application of machine learning (ML) techniques in diagnosing speech sound disorders (SSDs) in Saudi Arabic-speaking children, with a specific focus on phonological biomarkers, particularly Infrequent Variance (InfrVar), to improve diagnostic accuracy. SSDs are a significant concern in pediatric speech pathology, affecting an estimated 10-15% of preschool-aged children worldwide. However, accurate diagnosis remains challenging, especially in linguistically diverse populations. Traditional diagnostic tools, such as the Percentage of Consonants Correct (PCC), often fail to capture subtle phonological variations. This study explores the potential of machine learning models to enhance diagnostic accuracy by incorporating culturally relevant phonological biomarkers like InfrVar, aiming to develop a more effective diagnostic approach for SSDs in Saudi Arabic-speaking children. Data from 235 Saudi Arabic-speaking children aged 2;6 to 5;11 years were analyzed using several machine learning models: Random Forest, Support Vector Machine (SVM), XGBoost, Logistic Regression, K-Nearest Neighbors, and Naïve Bayes. The dataset was used to classify speech patterns into four categories: Atypical, Typical Development (TD), Articulation, and Delay. Phonological features such as Phonological Variance (PhonVar), InfrVar, and Percentage of Consonants Correct (PCC) were used as key variables. SHapley Additive exPlanations (SHAP) analysis was employed to interpret the contributions of individual features to model predictions. The XGBoost and Random Forest models demonstrated the highest performance, with an accuracy of 91.49% and an AUC of 99.14%. SHAP analysis revealed that articulation patterns and phonological patterns were the most influential features for distinguishing between Atypical and TD categories. The K-Means clustering approach identified four distinct subgroups based on speech development patterns: TD (46.61%), Articulation (25.42%), Atypical (18.64%), and Delay (9.32%). Machine learning models, particularly XGBoost and Random Forest, effectively classified speech development categories in Saudi Arabic-speaking children. This study highlights the importance of incorporating culturally specific phonological biomarkers like InfrVar and PhonVar to improve diagnostic precision for SSDs. These findings lay the groundwork for the development of AI-assisted diagnostic tools tailored to diverse linguistic contexts, enhancing early intervention strategies in pediatric speech pathology.
本研究调查了机器学习(ML)技术在诊断沙特阿拉伯语儿童语音障碍(SSD)中的应用,特别关注语音生物标志物,尤其是罕见变异(InfrVar),以提高诊断准确性。SSD是儿童言语病理学中的一个重要问题,估计全球有10 - 15%的学龄前儿童受其影响。然而,准确诊断仍然具有挑战性,尤其是在语言多样化的人群中。传统的诊断工具,如辅音正确率(PCC),往往无法捕捉到细微的语音变异。本研究探索了机器学习模型通过纳入如InfrVar等与文化相关的语音生物标志物来提高诊断准确性的潜力,旨在为沙特阿拉伯语儿童的SSD开发一种更有效的诊断方法。使用几种机器学习模型对235名年龄在2;6至5;11岁的沙特阿拉伯语儿童的数据进行了分析:随机森林、支持向量机(SVM)、XGBoost、逻辑回归、K近邻和朴素贝叶斯。该数据集用于将语音模式分为四类:非典型、典型发育(TD)、发音和延迟。语音变异(PhonVar)、InfrVar和辅音正确率(PCC)等语音特征被用作关键变量。采用SHapley加法解释(SHAP)分析来解释各个特征对模型预测的贡献。XGBoost和随机森林模型表现出最高的性能,准确率为91.49%,曲线下面积(AUC)为99.14%。SHAP分析表明,发音模式和语音模式是区分非典型和TD类别的最具影响力的特征。K均值聚类方法根据语音发展模式确定了四个不同的亚组:TD(46.61%)、发音(25.42%)、非典型(18.64%)和延迟(9.32%)。机器学习模型,特别是XGBoost和随机森林,有效地对沙特阿拉伯语儿童的语音发展类别进行了分类。本研究强调了纳入如InfrVar和PhonVar等特定文化的语音生物标志物以提高SSD诊断精度的重要性。这些发现为开发针对不同语言背景的人工智能辅助诊断工具奠定了基础,增强了儿童言语病理学中的早期干预策略。