Nassir Nasna, Almarri Mohamed A, Kumail Muhammad, Mohamed Nesrin, Balan Bipin, Hanif Shehzad, AlObathani Maryam, Jamalalail Bassam, Elsokary Hanan, Kondaramage Dasuki, Shiyas Suhana, Kosaji Noor, Satsangi Dharana, Abdelmotagali Madiha Hamdi Saif, Abou Tayoun Ahmad, Ahmed Olfat Zuhair Salem, Youssef Douaa Fathi, Suwaidi Hanan Al, Albanna Ammar, S Du Plessis Stefan, Khansaheb Hamda Hassan, Alsheikh-Ali Alawi, Uddin Mohammed
Center for Applied and Translational Genomics (CATG), Mohammed Bin Rashid University of Medicine and Health Sciences, Dubai Health, Dubai, UAE.
College of Medicine, Mohammed Bin Rashid University of Medicine and Health Sciences, Dubai Health, Dubai, UAE.
Nat Commun. 2025 Jul 24;16(1):6747. doi: 10.1038/s41467-025-61645-w.
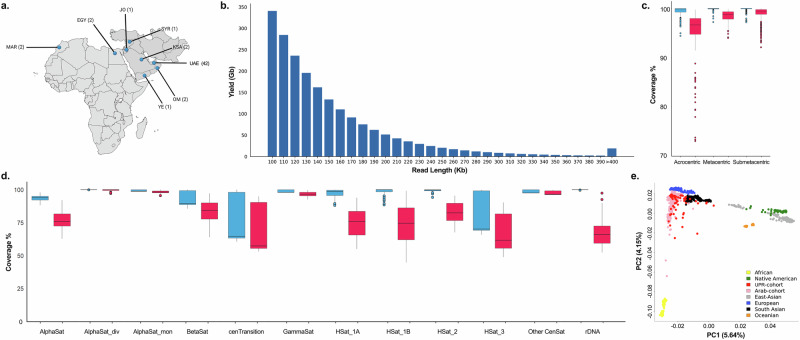
Pangenomes provide a robust and comprehensive portrayal of genetic diversity in humans, but Arab populations remain underrepresented. We present a preliminary UAE-based Arab Pangenome Reference (UPR) utilizing 53 individuals of diverse Arab ethnicities residing in the United Arab Emirates. We assembled nuclear and mitochondrial pangenomes using 35.27X high-fidelity long reads, 54.22X ultralong reads and 65.46X Hi-C reads. This approach yielded contiguous haplotype-phased de novo assemblies of exceptional quality, with an average N50 of 124.28 Mb. We discovered 111.96 million base pairs of previously uncharacterized euchromatic sequences absent from existing human pangenomes, the T2T-CHM13 and GRCh38 reference human genomes, and other public datasets. Moreover, we identified 8.94 million population-specific small variants and 235,195 structural variants within the Arab pangenome, not present in linear and pangenome references and public datasets. We detected 883 gene duplications, including the TATA-binding protein gene TAF11L5, which was uniquely duplicated across all Arab populations and that included 15.06% of genes associated with recessive diseases. By exploring the mitochondrial pangenome, we identified 1,436 bp of previously unreported sequences. Our study provides a valuable resource for future genetic research and genomic medicine initiatives in Arab population and other population with similar genetic backgrounds.
泛基因组为人类遗传多样性提供了强大而全面的描述,但阿拉伯人群体的代表性仍然不足。我们利用居住在阿拉伯联合酋长国的53名不同阿拉伯族裔个体,展示了一个基于阿联酋的初步阿拉伯泛基因组参考(UPR)。我们使用35.27倍的高保真长读长、54.22倍的超长读长和65.46倍的Hi-C读长组装了核基因组和线粒体泛基因组。这种方法产生了质量卓越的连续单倍型定相从头组装,平均N50为124.28兆碱基。我们发现了现有人类泛基因组、T2T-CHM13和GRCh38参考人类基因组以及其他公共数据集中不存在的1.1196亿碱基对的先前未表征的常染色质序列。此外,我们在阿拉伯泛基因组中鉴定出894万个群体特异性小变异和235,195个结构变异,这些变异不存在于线性和泛基因组参考以及公共数据集中。我们检测到883个基因重复,包括TATA结合蛋白基因TAF11L5,它在所有阿拉伯人群体中独特地重复,并且包含15.06%与隐性疾病相关的基因。通过探索线粒体泛基因组,我们鉴定出1436碱基对的先前未报道的序列。我们的研究为阿拉伯人群体和其他具有相似遗传背景的群体未来的遗传研究和基因组医学计划提供了宝贵的资源。